基于PDF文献的本地向量库构建和大模型检索(LLM-向量数据库)
pdf文献的本地化向量库构建和大模型交互
·
1.文献的向量化
1.1 导包需求
from langchain.vectorstores import Chroma
import os
from PyPDF2 import PdfReader
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_core.documents import Document1.2 向量化模型
这里选择了huggingface上的向量化模型"moka-ai/m3e-base",可以根据需求自由选择,向量化模型的选择可以参考其他博主的信息AI开发者de频道:文章显示
#向量化模型
model_name = "moka-ai/m3e-base"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)1.3 pdf文献的向量化
流程:
1. 读取pdf文献地址
2. 文献解析(采用开源解析包-PyPDF2)
3. 文献向量化
current_dir = os.getcwd()
# 读取包含PDF文件的目录
pdf_docs_dir = os.path.join(current_dir, 'wenxian')
if not os.path.exists(pdf_docs_dir):
print(f"目录不存在:{pdf_docs_dir}")
else:
# 获取目录中所有文件
files = os.listdir(pdf_docs_dir)
# 筛选出PDF文件
pdf_files = [file for file in files if file.lower().endswith('.pdf')]
docs = []
# 遍历每个PDF文件
for pdf_file in pdf_files:
pdf_docs_path = os.path.join(pdf_docs_dir, pdf_file)
print(f"处理文件:{pdf_docs_path}")
#文档解析
pdf_reader = PdfReader(pdf_docs_path)
for idx, page in enumerate(pdf_reader.pages):
docs.append(
Document(
page_content=page.extract_text(),
metadata={"source": f"{pdf_docs_path} on page {idx}"}
)
)
#指定向量化模型的存储地址和名称
persist_directory = os.path.join(current_dir, 'chroma_db')
os.makedirs(persist_directory, exist_ok=True)
#文本信息向量化
vectordb = Chroma.from_documents(
documents=docs, #解析后的文本信息
embedding=embedding, #向量化模型
persist_directory=persist_directory #存储地址
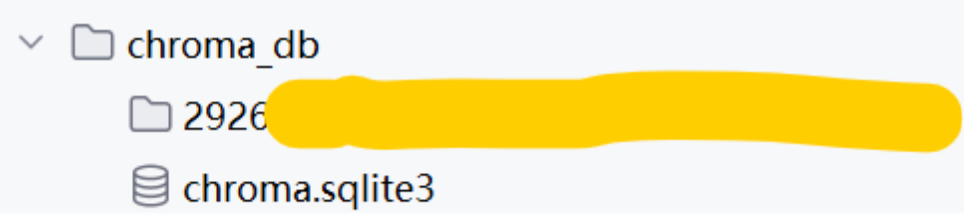
)结果如图所示:
2. 本地向量库检索
2.1 向量化数据量检索
import chromadb
#path处填入自己的数据库地址,链接数据库
#连接一个持久化存储的数据库,并获取数据集合
chroma_client = chromadb.PersistentClient(path=r"D:\chroma_db")
# 创建一个名为 "langchain" 的集合
collection_name = "langchain"
chroma_client.create_collection(name=collection_name)
#查询数据库中存在的集合名称
collections = chroma_client.list_collections()
collection_names = [collection.name for collection in collections]
print("向量库中存在的集合名称:", collection_names)
#索取名为langchain的集合数据
collection = chroma_client.get_collection(name="langchain")
#查看数据量
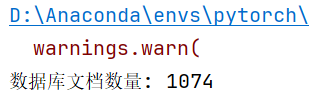
print(f"数据库文档数量: {collection.count()}")![]()
2.2 LLM交互
使用llama模型,llama模型的api_key获取地址,见此篇文章主流AI大模型的python代码调用和代码示例-CSDN博客,也可以换成其他模型
注意点:制作向量库的向量化模型和检索使用的向量化模型的向量维度需要一致,推荐使用同一种
# 推荐与创建向量化数据库的模型一致
model_name = "moka-ai/m3e-base"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
embedding = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
#索取向量信息
langchain_chroma = Chroma(
client=chroma_client,
collection_name="langchain",
embedding_function=embedding
)
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
query='硫化物电解质的性能'
#形成向量检索
retriever=langchain_chroma.as_retriever(search_kwargs={"k": 5}) #search_kwargs={"k": 5}
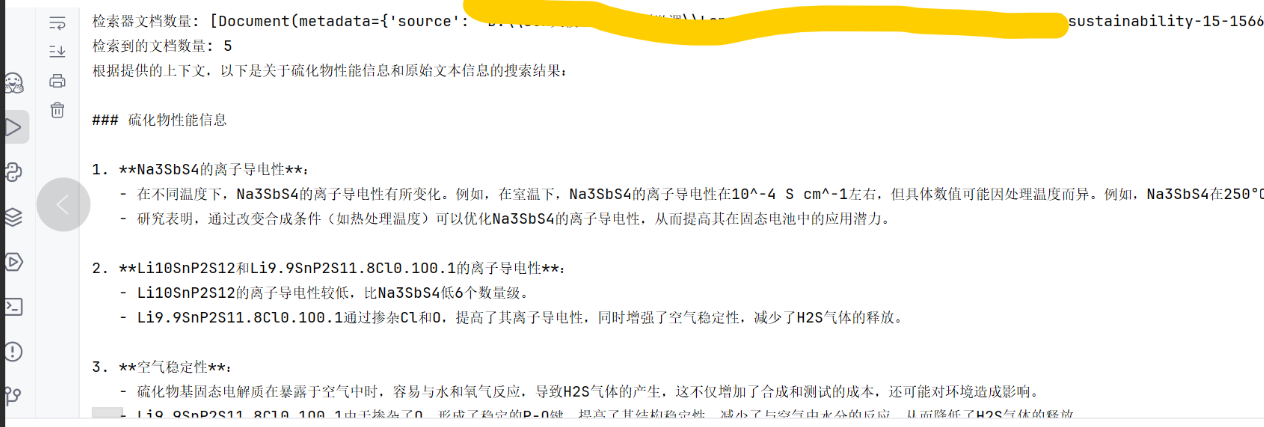
print(f"检索器文档数量: {retriever.get_relevant_documents(query)}")
print(f"检索到的文档数量: {len(retriever.get_relevant_documents(query))}")
#提示词模板
message = """
使用提供的上下文仅回答这个问题:
{question}
上下文:
{context}
"""
prompt_temp = ChatPromptTemplate.from_messages([('human', message)])
#使用的交互大模型
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
temperature=0.2,
model="meta/llama-3.3-70b-instruct",
base_url="https://integrate.api.nvidia.com/v1",
api_key="API_KEY"
)
# langchain构建
chain = {'question': RunnablePassthrough(), 'context': retriever} | prompt_temp | model
resp = chain.invoke(query)
print(resp.content)结果:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)