On Balancing Bias and Variance in Unsupervised Multi-Source-Free Domain Adaptation
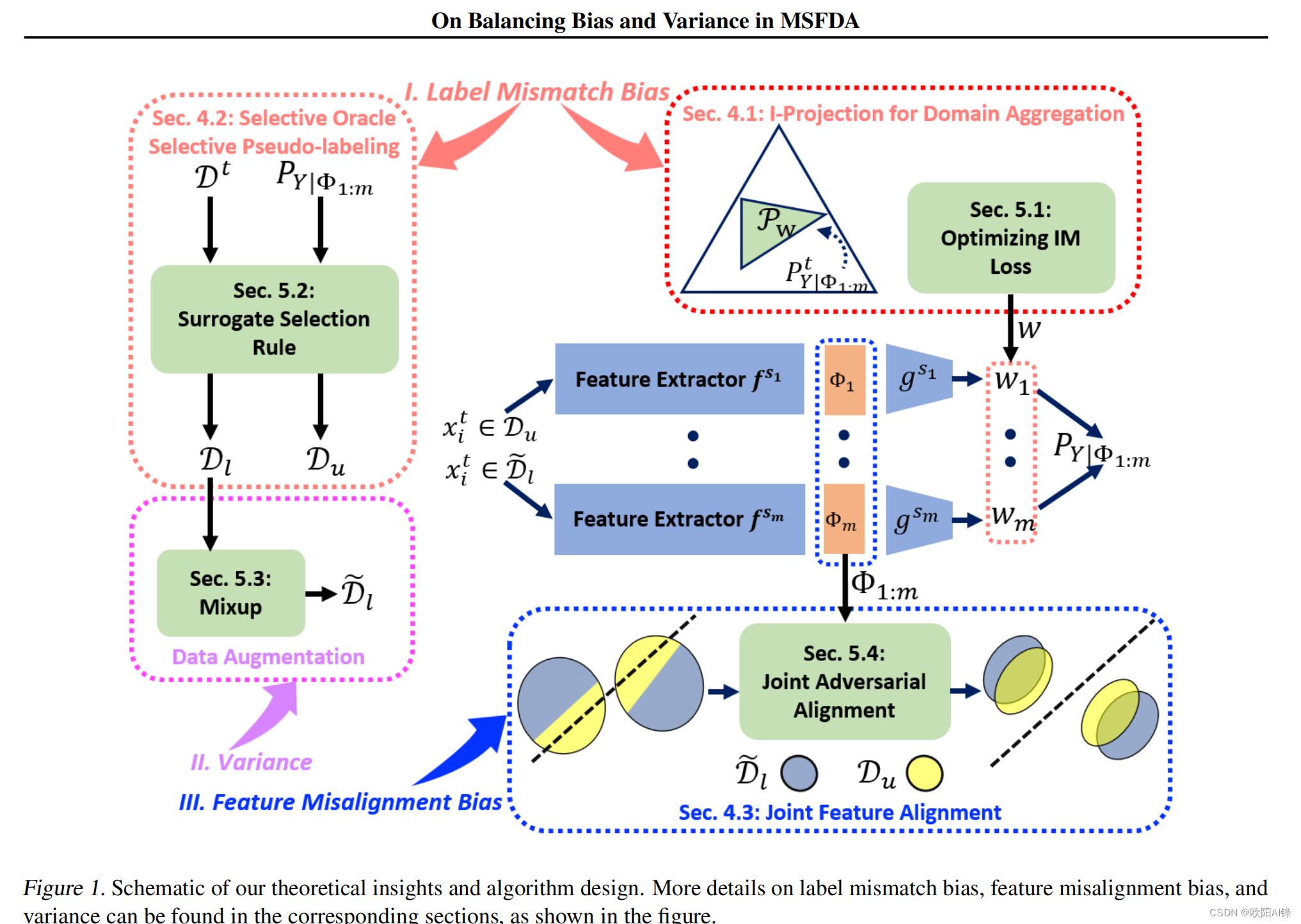
由于隐私、存储和其他限制,机器学习中对无监督域适应技术的需求越来越大,这种技术不需要访问用于训练源模型集合的数据。现有的多无源域自适应(MSFDA)方法主要是利用源模型产生的伪标记数据来训练目标模型,这些方法主要是改进伪标记技术或提出新的训练目标。相反,本文的目的是分析MSFDA的基本限制。特别是,我们对结果目标模型的泛化误差提出了一个信息论界限,这说明了固有的偏差-方差权衡。
·
由于隐私、存储和其他限制,机器学习中对无监督域适应技术的需求越来越大,这种技术不需要访问用于训练源模型集合的数据。现有的多无源域自适应(MSFDA)方法主要是利用源模型产生的伪标记数据来训练目标模型,这些方法主要是改进伪标记技术或提出新的训练目标。相反,本文的目的是分析MSFDA的基本限制。特别是,我们对结果目标模型的泛化误差提出了一个信息论界限,这说明了固有的偏差-方差权衡。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 0
0 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)