FWI学习(1)损失函数
损失:衡量模型的量化指标,直接知道模型如何继续优化参数以提升任务性能。
FWI学习(1)损失函数
损失函数(LOSS FUNCTION):
1、是什么?
损失:衡量模型预期结果和真实值差异的量化指标,直接知道模型如何继续优化参数以提升任务性能。
2、类别
这里我们主要提及了pixel-wise Loss(像素级别任务),针对这类任务主要就是进行高分辨率、去噪这种的特性,所以和我们的任务目标是非常切合的。
-
L1 Loss(MAE)
∑∣y真实−y预测∣
简单说,L1 loss主要就是看我们真实数据和预测数据的绝对值差异。
- 特点:特征选择+抗噪声;保留边缘锐度,对异常值鲁棒
- 参数分布:稀疏
-
L2 Loss(MSE)
∑(y真实−y预测)^2
简单说,L2 loss就是平方差差异。
- 特点:平滑输出+稳定性高;强调大误差惩罚,输出更平滑,但易模糊细节。
- 参数分布:小且均匀
-
Huber Loss
简单说就是对L1和L2两种loss的混合使用,小误差用L2,大误差用L1,平衡两者的特性
-
Boundary Loss
专门针对边界Loss设计的,因为我们的任务需要关注边界信息,所以这个也是比较重要的一个标准。
-
其他:
这里同时还提及了其他的损失函数,比如seagull loss。这里主要还是想说,研究损失函数本身也算是一个研究方向,但是这个方向比较偏向底层的东西,做的人还是比较一个少。
思考:因为本身还是想往mamba模型这类状态空间模型上思考,也顺着去看了看其他的损失函数设计。这里也简单存一下:
-
传统SSM:
基于MLE(最大似然估计):
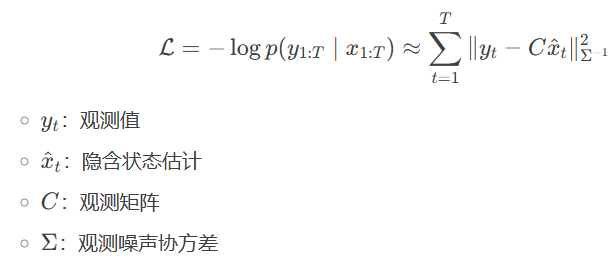
-
Mamba:
其实mamba对于长序列预测任务也还是选择的MSE或者MAE,这个和我们前面说的其实是一样的,也简介说明了我们L1\L2损失函数其实很适合这种长序列预测任务。
而对于分类、预测、自然语言处理这种,使用交叉熵损失会多一点,这个主要是针对mamba的选择性扫描机制,能够动态去关注时间步。
-
Mamba-UNet:
其实这里更多偏向于UNET本身而不是mamba上面了。
Dice Loss就是针对图像分割这类问题比较好的一个选择。
-
Dice Loss:
因为比较感兴趣,所以简单看了一下:
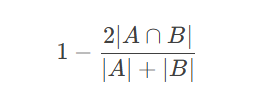
大概实现了这么一个事情:预测结果区域和ground truth区域的交并比,所以它是把一个类别的所有像素作为一个整体去计算Loss。这么做有一个好处,就是可以忽略大量背景像素,解决了正负样本不均衡的问题,所以收敛速度很快。
-
CE(交叉熵)
然后Mamba-UNet里面比较常见的也就是CE+DiceLoss的结合使用。
-
3、正则项
前面我们已经提及了一些常见的损失函数,尤其是我们的L1和L2,我们也知道了我们的L1和L2型损失函数主要依赖于绝对值差异以及平方差。
但是这里存在一个问题,当我们出现一组偏差特别特别大的数据的时候,就会导致偏差过大,这样就容易造成过拟合。
正则项就相当于给损失函数添加了一个惩罚机制,用来限制这种特别大的差异。

大概张这个样子。
然后我们说到了针对线性回归中使用正则项的优点,直观感受上就是我把我差别特别大的点差距拉小了,这样对我希望的模型也肯定会更加准确。
-
4、一个对图像处理类问题的特别指标SSIM:
当然我们研究的问题是图像处理,所以这里还存在一个问题:
在同一个图片我仅仅移动了两个像素点,我的图片肯定还是同一个东西,但是这个就会造成我们前面的两种方法得出的结果差别很大。
所以我们提出了SSIM这个指标,用来评估两张图像相似度的指标,尤其用于衡量图像的结构、亮度、对比度等感知质量是否相似。
所以这个SSIM需要单独拿出来说一下,SSIM也可以作为loss,甚至说也是很重要的一个指标评价标准。
5、反向梯度和优化器
(——对损失函数的函数的反馈实现)
根据前面我们说的,我们现在已经知道了我们的损失函数大概是什么,现在我们还需要解决一件事:我们怎么把我们的损失函数告诉我们的模型?
先说说反向梯度求解(因为python会自动帮我们完成这些事情,所以我们往往会忽略其中的设计)。
针对一个模型的训练,我们会有两个过程:
前向传播(forward pass):输入 → 模型 → 得到预测值 → 计算损失
反向传播(backward pass):通过链式法则计算每个参数对 Loss 的导数(即梯度)
这其中的梯度也会告诉我们怎么调整参数,让损失更小,也让我们训练出来的函数更好。简单说,Loss.backward()就是我们的反向梯度求解的过程。
而这里这个梯度怎么来呢?这就要说说我们的优化器(Optimizer)了。
优化器负责用计算出来的梯度去更新参数,然后我们比较常见的优化器就是Adam optimizer,一般会使用这个来实现自动化处理,所以我们才容易忽视这个东西。
6、泛化性实现的思考
对我们的模型训练,我们肯定还是希望我们的模型不仅仅只在我的训练集上表现好(记住数据),我们同样也还是希望我们的模型可以记住数据,在新的数据表现上也好。
而过拟合就是泛化性差的一个体现,它只记住了我们我给出的训练集,其他新的数据就不太适应了。
损失函数相当于给我了一个学习的方向,我们可以通过损失函数来避免模型的过拟合。
除此之外,我们还可以使用其他的办法,比如通过训练集和验证集来防止过拟合,以及我们的模型层数也不是训练的越多越好,loss是始终存在的,不可能为0,因为具有不确定性,但是我们肯定还是希望我们的模型尽量精准。
拿一个简单的函数关系式来举例:
y=F_m(x),y是我们的预期结果,x是我们的输入训练数据,m()就是我们希望训练的模型,我们是希望m()训练出来的个数越少越好,因为这样更可以直观体现我们x(输入)和y(输出)之间的关系,比如我换了一个训练集x之后,y依然可以按照原来的规律反应。这就是我们训练模型一个比较期望的结果。
但是现实我们也知道m()函数不可能只有一个,这个m()就相当于我们期望实现泛化性的结果。
最后一个思考是关于模型蒸馏:
蒸馏是什么呢?相当于原来我已经有了一个训练效果非常非常好的模型,它作为母模型可以从中提取一部分从而把“知识”传递给一个子模型。蒸馏的过程无疑也是对泛化性的一个提升,并且这个过程肯定比母模型会损失一些准确性。
但是对于类似99.999%和99.99%的准确性来说其实已经相差不大了(比较夸张的说法了),这种蒸馏出来的模型更加轻量化也能有更多的应用场景。当然,前提还是我们的母模型效果已经非常好了,所以对我们的现阶段FWI的研究来说还没走到这一步。
当然,以后也还说不定,留个悬念吧= ̄ω ̄=

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)