三、Tucker 分解
Tucker 分解Tucker 分解 Tucker 分解法可以被视作一种高阶 PCA. 它将张量分解为核心张量在每个mode上与矩阵的乘积. 因此, 对三阶张量 X∈RI×J×K\mathcal{X}\in\mathbb{R}^{I \times J \times K}X∈RI×J×K ,我们有如下分解:X≈G×1A
Tucker 分解
Tucker 分解
Tucker 分解法可以被视作一种高阶 PCA. 它将张量分解为核心张量在每个mode上与矩阵的乘积. 因此, 对三阶张量 X∈RI×J×K\mathcal{X}\in\mathbb{R}^{I \times J \times K}X∈RI×J×K ,我们有如下分解:
X≈G×1A×2B×3C=∑p=1P∑q=1Q∑r=1Rgpqr ap∘bq∘cr=[ [G ;A,B,C] ]\mathcal{X} \approx \mathcal{G}\times_1 \mathrm{A} \times_2 \mathrm{B} \times_3 \mathrm{C} = \sum_{p=1}^P\sum_{q=1}^Q\sum_{r=1}^R g_{pqr} \: \mathrm{a}_p\circ \mathrm{b}_q\circ \mathrm{c}_r = [\![\mathcal{G}\,;A,B,C]\!] X≈G×1A×2B×3C=p=1∑Pq=1∑Qr=1∑Rgpqrap∘bq∘cr=[[G;A,B,C]]
其中,A∈RI×P\mathrm{A}\in \mathbb{R}^{I\times P}A∈RI×P,B∈RJ×Q\mathrm{B}\in\mathbb{R}^{J\times Q}B∈RJ×Q 和 C∈RK×R\mathrm{C} \in \mathbb{R}^{K\times R}C∈RK×R 被称为因子矩阵,它们通常是正交的,可以视为沿相应 mode 下的主成分。张量 G∈RP×Q×R\mathcal{G} \in \mathbb{R}^{P \times Q \times R}G∈RP×Q×R 被称为核心张量,其每个数字元素代表了不同成分之间的互动程度。三阶张量的 Tucker 分解可以用下图表示:
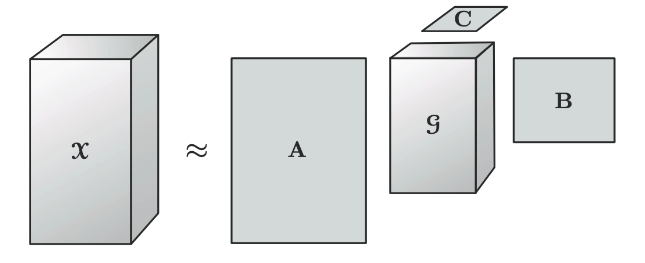
对于每个元素来说,Tucker 分解法可以写作
xijk≈∑p=1P∑q=1Q∑r=1Rgpqraipbjqckr,i=1,…,I,j=1,…,J,k=1,…,K x_{ijk} \approx \sum_{p=1}^P \sum_{q=1}^Q \sum_{r=1}^R g_{pqr}a_{ip}b_{jq}c_{kr} \quad , \quad i = 1,\dots,I, j =1,\dots,J, k=1,\dots,K xijk≈p=1∑Pq=1∑Qr=1∑Rgpqraipbjqckr,i=1,…,I,j=1,…,J,k=1,…,K
其中,P,Q,RP,Q,RP,Q,R 为对应因子矩阵里列的个数。
容易看出 CP 分解是 Tucker 分解的一种特殊形式,如果核心张量的为超对角张量而且 P=Q=RP=Q=RP=Q=R ,Tucker 分解就退化成了权重 CP 分解。
Tucker 分解可以写成如下的矩阵化形式:
X(1)≈AG(1)(C⊗B)T \mathrm{X}_{(1)} \approx \mathrm{A}\mathrm{G}_{(1)}(\mathrm{C}\otimes \mathrm{B})^\mathsf{T} X(1)≈AG(1)(C⊗B)T
X(2)≈BG(2)(C⊗A)T \mathrm{X}_{(2)} \approx \mathrm{B}\mathrm{G}_{(2)}(\mathrm{C}\otimes \mathrm{A})^\mathsf{T} X(2)≈BG(2)(C⊗A)T
X(3)≈CG(3)(B⊗A)T \mathrm{X}_{(3)} \approx \mathrm{C}\mathrm{G}_{(3)}(\mathrm{B}\otimes \mathrm{A})^\mathsf{T} X(3)≈CG(3)(B⊗A)T
Tucker 分解的高维推广
对于 NNN 维张量,Tucker 分解可以写作:
X=G×1A(1)×2A(2)⋯×NA(N)=[ [G;A(1),A(2),…,A(N)] ] \mathcal{X} = \mathcal{G} \times_1 \mathrm{A}^{(1)} \times_2 \mathrm{A}^{(2)}\dots \times_N \mathrm{A}^{(N)} = [\![\mathcal{G}; \mathrm{A}^{(1)}, \mathrm{A}^{(2)}, \dots , \mathrm{A}^{(N)}]\!] X=G×1A(1)×2A(2)⋯×NA(N)=[[G;A(1),A(2),…,A(N)]]
矩阵化可以写为:
X(n)=A(n)G(n)(A(N)⊗⋯⊗A(n+1)⊗A(n−1)⊗⋯⊗A(1))T \mathrm{X}_{(n)} = \mathrm{A}^{(n)}\mathrm{G}_{(n)}(\mathrm{A}^{(N)}\otimes \dots \otimes \mathrm{A}^{(n+1)}\otimes \mathrm{A}^{(n-1)}\otimes \dots \otimes \mathrm{A}^{(1)})^\mathsf{T} X(n)=A(n)G(n)(A(N)⊗⋯⊗A(n+1)⊗A(n−1)⊗⋯⊗A(1))T
Tucker 2 分解法
对于三阶张量,固定一个因子矩阵为单位矩阵,就可以得到 Tucker 分解的一个重要的特例,Tucker 2 分解。例如,固定 C=I\mathrm{C=I}C=I,若 I\mathrm{I}I 是 K×KK \times KK×K 的单位矩阵,则再使 G∈RP×Q×R\mathcal{G}\in\mathbb{R}^{P \times Q \times R}G∈RP×Q×R,那么我们就可以得到:
X≈G×1A×2B=[ [G ;A,B,I] ]\mathcal{X} \approx \mathcal{G}\times_1 \mathrm{A} \times_2 \mathrm{B} = [\![\mathcal{G}\,;\mathrm{A,B,I}]\!]X≈G×1A×2B=[[G;A,B,I]]
Tucker 1 分解法
更近一步,如果我们固定两个因子矩阵,只利用一个矩阵来分解,并将剩余矩阵设为单位矩阵。例如,如果设 B=C=I\mathrm{B=C=I}B=C=I,那么我们可以得到:
X≈G×1A=[ [G ;A,I,I] ]\mathcal{X} \approx \mathcal{G} \times_1 \mathrm{A} = [\![\mathcal{G}\,;\mathrm{A,I,I}]\!]X≈G×1A=[[G;A,I,I]]
这等价于一个标准的二维 PCA ,即:
X(1)=AG(1)\mathrm{X}_{(1)} = \mathrm{A}\mathrm{G}_{(1)}X(1)=AG(1)
n - rank (n 秩)
若 X\mathcal{X}X 是一个大小为 I1×I2×⋯×INI_1\times I_2 \times \dots \times I_NI1×I2×⋯×IN 的 NNN 阶张量,那么它的 n 秩为:X\mathcal{X}X 在 mode - n 矩阵化后得到的矩阵 X(n)\mathrm{X}_{(n)}X(n) 的列秩,表示为 rankn(X)\text{rank}_n(\mathcal{X})rankn(X) 。如果在 Tucker 分解中,令
Rn=rankn(X),n=1,2,⋯ ,NR_n=\text{rank}_n(\mathcal{X}), \quad n=1,2,\cdots ,NRn=rankn(X),n=1,2,⋯,N
那么就称张量 X\mathcal{X}X 是一个 rank−(R1,R2,…,RN)\text{rank}-(R_1,R_2,\dots,R_N)rank−(R1,R2,…,RN) 张量。
如果一个张量是 rank−(R1,R2,…,RN)\text{rank}-(R_1,R_2,\dots,R_N)rank−(R1,R2,…,RN) 张量,那么我们很容易找到一个 Rn=rankn(X)R_n=\text{rank}_n(\mathcal{X})Rn=rankn(X) 的精确 Tucker 分解。但是如果我们计算某些 nnn 满足 Rn<rankn(X)R_n<\text{rank}_n(\mathcal{X})Rn<rankn(X) 的 Tucker 分解,那么我们将必然无法获得精确的结果,即该分解不能精确地还原 X\mathcal{X}X 。
Tucker 分解法的计算
1. HOSVD (高阶 SVD)
该方法是利用 SVD 对每个 mode 做一次 Tucker 1 分解,其结果为将一个张量分解为一个核心张量和三个正交矩阵,HOSVD 是 Tucker 分解的一种特殊情况,其要求分解得到的因子矩阵必须为正交的,即
X=G×1U(1)×2U(2)×3U(3)\mathcal{X} = \mathcal{G}\times_1 \mathrm{U}_{(1)} \times_2 \mathrm{U}_{(2)} \times_3 \mathrm{U}_{(3)} X=G×1U(1)×2U(2)×3U(3)
其中,U(1),U(2),U(3)U_{(1)},U_{(2)},U_{(3)}U(1),U(2),U(3) 分别为先将张量进行 mode - n 矩阵化,得到 X(n)\mathcal{X}_{(n)}X(n) 矩阵,然后对得到的矩阵进行奇异值分解,使得
X(n)=U(n)ΣV(n)T\mathcal{X}_{(n)}= U_{(n)}\Sigma V_{(n)}^TX(n)=U(n)ΣV(n)T
对于不同的 mode 矩阵 X(n)\mathcal{X}_{(n)}X(n) ,我们可以得到上面的式子中的 U(n)U_{(n)}U(n) ,如果对三个 mode 矩阵都做上式的运算,就可以得到 U(1),U(2),U(3)U_{(1)},U_{(2)},U_{(3)}U(1),U(2),U(3) 。
根据
X=G×1U(1)×2U(2)×3U(3)\mathcal{X} = \mathcal{G}\times_1 \mathrm{U}_{(1)} \times_2 \mathrm{U}_{(2)} \times_3 \mathrm{U}_{(3)}X=G×1U(1)×2U(2)×3U(3)
我们可以得到:
G=X×1U(1)T×2U(2)T×3U(3)T\mathcal{G} = \mathcal{X} \times_1 \mathrm{U}_{(1)}^T \times_2 \mathrm{U}_{(2)}^T \times_3 \mathrm{U}_{(3)}^TG=X×1U(1)T×2U(2)T×3U(3)T
从而我们得到 HOSVD 的分解结果,即 G,U1,U2,U3\mathcal{G},U_1,U_2,U_3G,U1,U2,U3 。
如果至少存在一个 Rn<rankn(X)R_n<\text{rank}_n(\mathcal{X})Rn<rankn(X) ,则称为截断 HOSVD 。
HOSVD 不能保证得到一个较好的近似,但是 HOSVD 的结果可以作为一个其他迭代算法(如下面的 HOOI)的很好的初始解。
HOSVD 的另一种描述
我们定义一个张量 GGG 的 键约化矩阵 为
Jii′=∑jkGijkGi′jkJ_{ii'}=\sum_{jk}G_{ijk}G_{i'jk}Jii′=jk∑GijkGi′jk
由此我们可以引出对 TTT 进行 HOSVD 算法的另外一种求解方法:
-
计算各个指标的键约化矩阵
Iii′=∑jkTijkTi′jkI_{ii'}=\sum_{jk}T_{ijk}T_{i'jk}Iii′=jk∑TijkTi′jkJjj′=∑ikTijkTij′kJ_{jj'}=\sum_{ik}T_{ijk}T_{ij'k}Jjj′=ik∑TijkTij′k
Kkk′=∑ijTijkTijk′K_{kk'}=\sum_{ij}T_{ijk}T_{ijk'}Kkk′=ij∑TijkTijk′
-
计算每个键约化矩阵的本征值分解
I=UΩUTI=U\Omega U^TI=UΩUTJ=VΠVTJ=V\Pi V^TJ=VΠVT
K=WΥWTK=W\Upsilon W^TK=WΥWT
-
计算核张量
Gijk=∑abcTabcUaiVbjWckG_{ijk}=\sum_{abc}T_{abc}U_{ai}V_{bj}W_{ck}Gijk=abc∑TabcUaiVbjWck -
得到高阶奇异值分解
Tabc=∑ijkGijkUaiVbjWckT_{abc}=\sum_{ijk}G_{ijk}U_{ai}V_{bj}W_{ck}Tabc=ijk∑GijkUaiVbjWck
2. HOOI 迭代算法
HOOI 秩去计算 X(n)\mathrm{X}_{(n)}X(n) 的主奇异向量,并且运用 SVD 来代替特征值分解,或者只计算其主子空间的单位正交基底向量即可。
设 X\mathcal{X}X 是一个 I1×I2×⋯×INI_1 \times I_2 \times \dots \times I_NI1×I2×⋯×IN 尺寸的张量,那么我们可以将要分解问题转化为求:
min∣∣X−[ [G ;A(1),A(2),…,A(N)] ]∣∣\min \Big|\Big| \mathcal{X} - [\![\mathcal{G}\,;\mathrm{A}^{(1)},\mathrm{A}^{(2)},\dots,\mathrm{A}^{(N)}]\!] \Big|\Big|min∣∣∣∣∣∣X−[[G;A(1),A(2),…,A(N)]]∣∣∣∣∣∣
其中,G∈RR1×R2×⋯×RN\mathcal{G}\in\mathbb{R}^{R_1\times R_2 \times \dots \times R_N}G∈RR1×R2×⋯×RN ,矩阵 A(n)∈RIn×Rn\mathrm{A}^{(n)}\in \mathbb{R}^{I_n \times R_n}A(n)∈RIn×Rn 且列正交。
对于上式的最优解,显然其核心张量 G\mathcal{G}G 必须满足
G=X×1A(a)T×2A(2)T⋯×NA(N)T\mathcal{G} = \mathcal{X} \times_1 \mathrm{A}^{(a)\mathsf{T}} \times_2 \mathrm{A}^{(2)\mathsf{T}} \dots \times_N \mathrm{A}^{(N)\mathsf{T}}G=X×1A(a)T×2A(2)T⋯×NA(N)T
则目标函数的平方为:
∣∣X−[ [G ;A(1),(2),…,A(N)] ]∣∣2=∣∣X∣∣2−2⟨X,[ [G ;A(1),A(2), …,A(N)] ]⟩+∣∣G ;A(1),A(2),…,A(N)∣∣2=∣∣X∣∣2−2⟨X×1A(1)T⋯×NA(N)T,G⟩+∣∣G∣∣2=∣∣X∣∣2−2⟨G, G⟩+∣∣G∣∣2=∣∣X∣∣2−∣∣G∣∣2=∣∣X∣∣2−∣∣X×1A(1)T×2⋯×NA(N)T∣∣2 \begin{aligned} &\Big|\Big| \mathcal{X} - [\![\mathcal{G}\,; \mathrm{A}^{(1)}, \mathrm{(2)},\dots,\mathrm{A}^{(N)}] \!] \Big|\Big|^2 \\ &= ||\mathcal{X}{||}^2 - 2 \langle \mathcal{X}, [\![\mathcal{G}\,;\mathrm{A}^{(1)},\mathrm{A}^{(2)},\,\dots,\mathrm{A}^{(N)}]\!]\rangle + ||\mathcal{G}\,;\mathrm{A}^{(1)},\mathrm{A}^{(2)},\dots,\mathrm{A}^{(N)}{||}^2 \\ &= ||\mathcal{X}{||}^2 - 2\langle \mathcal{X} \times_1 \mathrm{A}^{(1)\mathsf{T}}\dots \times_N \mathrm{A}^{(N)\mathsf{T}},\mathcal{G}\rangle +||\mathcal{G}{||}^2 \\ &= ||\mathcal{X}{||}^2 - 2\langle \mathcal{G},\,\mathcal{G}\rangle + ||\mathcal{G}{||}^2 \\ &= ||\mathcal{X}{||}^2 - ||\mathcal{G}{||}^2 \\ &= ||\mathcal{X}{||}^2 - ||\mathcal{X}\times_1 \mathrm{A}^{(1)\mathsf{T}} \times_2 \dots \times_N \mathrm{A}^{(N)\mathsf{T}}{||}^2 \end{aligned} ∣∣∣∣∣∣X−[[G;A(1),(2),…,A(N)]]∣∣∣∣∣∣2=∣∣X∣∣2−2⟨X,[[G;A(1),A(2),…,A(N)]]⟩+∣∣G;A(1),A(2),…,A(N)∣∣2=∣∣X∣∣2−2⟨X×1A(1)T⋯×NA(N)T,G⟩+∣∣G∣∣2=∣∣X∣∣2−2⟨G,G⟩+∣∣G∣∣2=∣∣X∣∣2−∣∣G∣∣2=∣∣X∣∣2−∣∣X×1A(1)T×2⋯×NA(N)T∣∣2
如果使目标函数取值最小,那么我们可以使得上面结果的第二项取最大值,即
max∣∣X×1A(1)T×2A(2)T⋯×NA(N)T∣∣\max\Big|\Big|\mathcal{X}\times_1 \mathrm{A}^{(1)\mathsf{T}} \times_2 \mathrm{A}^{(2)\mathsf{T}}\dots \times_N\mathrm{A}^{(N)\mathsf{T}}\Big|\Big|max∣∣∣∣∣∣X×1A(1)T×2A(2)T⋯×NA(N)T∣∣∣∣∣∣
进一步,我们可以将上式写为
max∣∣A(n)TW∣∣ \max\Big|\Big|\mathrm{A}^{(n)\mathsf{T}}\mathrm{W}\Big|\Big| max∣∣∣∣∣∣A(n)TW∣∣∣∣∣∣
其中
W=X(n)(A(N)⊗⋯⊗A(n+1)⊗A(n−1)⊗⋯⊗A(1))\mathrm{W} = \mathrm{X}_{(n)} (\mathrm{A}^{(N)} \otimes \dots \otimes \mathrm{A}^{(n+1)}\otimes \mathrm{A}^{(n-1)} \otimes\dots\otimes\mathrm{A}^{(1)})W=X(n)(A(N)⊗⋯⊗A(n+1)⊗A(n−1)⊗⋯⊗A(1))
我们可以将 A(n)A^{(n)}A(n) 定义为 W\mathrm{W}W 的前 RnR_nRn 个左奇异向量就可以求出解。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)