(gMLP)Pay Attention to MLPs
摘要Transformers已经成为深度学习领域最重要的架构创新之一,并在过去几年实现了许多突破。在这里,我们提出了一个简单的无注意(attention-free)的网络架构,gMLP,仅基于mlp与门控,并表明它可以在关键语言和视觉应用领域和Transformers一样好。我们的比较表明,自我关注对vision transformers来说并不重要,因为gMLP可以达到同样的精度。在gMLP表现
摘要
Transformers已经成为深度学习领域最重要的架构创新之一,并在过去几年实现了许多突破。在这里,我们提出了一个简单的无注意(attention-free)的网络架构,gMLP,仅基于mlp与门控,并表明它可以在关键语言和视觉应用领域和Transformers一样好。我们的比较表明,自我关注对vision transformers来说并不重要,因为gMLP可以达到同样的精度。在gMLP表现较差的微调任务中,让gMLP模型大幅变大可以缩小与transformer之间的差距。总的来说,我们的实验表明,gMLP可以在增加的数据和计算中进行扩展。
1 Introduction
Transformers[1]在自然语言处理方面取得了许多突破(例如,[2,3,4,5,6]),并被证明在计算机视觉方面工作良好(例如,[7,8,9,10])。由于这一成功,transformer在很大程度上取代了LSTM-RNN[11]作为NLP的默认架构,并成为计算机视觉中ConvNets[12,13,14,15,16]的一个有吸引力的替代方案。
Transformer架构结合了两个重要的概念:(1)并行计算每个独立token的表示的无重复架构,(2)多头自注意块( multi-head self-attention blocks ),聚合跨token的空间信息。一方面,注意力机制[17]引入了归纳偏差,即模型可以根据输入表示动态参数化。另一方面,已知具有静态参数化的mlp可以表示任意函数[18]。因此,关于自我关注的归纳偏见是否对Transformer的显著效果至关重要仍然是一个悬而未决的问题。
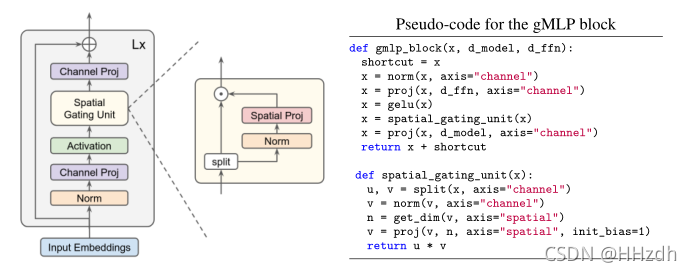
在这里,我们研究了自我注意模块在transformer的关键语言和视觉应用中的必要性,并提出了一个基于mlp的、无需注意的transformer替代方案,该方案包括通道投影、空间投影和门控(图1)。我们对类似mlp的结构进行了几个设计选择的实验,发现当空间投影是线性的,并与乘法门控配对时,效果很好。我们将该模型命名为gMLP,因为它是建立在带有门控的基本MLP层之上的。
我们将gMLP应用于图像分类,并在ImageNet上获得了较好的结果。在类似的训练设置中,gMLP实现了与DeiT[8]相当的性能,即通过改进正则化增强的Vision Transformer (ViT)[7]。用少66%的参数,一个gMLP模型比MLP-Mixer[19]精确3%。与Tolstikhin et al. [19], Melas-Kyriazi[20]和Touvron et al.[21]一起,我们的结果质疑了Vision Transformers中自我注意层的必要性。
在BERT[2]设置中,我们将gMLP应用到masked language建模(MLM)中,这是变Transformers最成熟的应用之一,我们发现它在减少预训练时的perplexity方面与Transformers一样好。我们的实验表明,perplexity只与模型容量相关,对注意力的存在不敏感。随着容量的增加,我们观察到gMLP的预训练和微调指标的提高速度与Transformers一样快。这是值得注意的,因为它表明gMLP的规模和Transformers一样好,尽管没有自我注意,任何性能差距总是可以通过增加数据和计算训练一个更大的模型来抵消。在原始BERT中使用标准的256批size×1M-step训练设置,我们的MLP类模型在MNLI上达到了86.4%的准确率,在SQuAD v1.1上达到了89.5%的F1准确率。注意,这些结果可与Devlin等人[2]使用transformer获得的结果相比较。
对于BERT的微调来说,在需要交叉句子对齐的任务上,Transformers实际上比gMLPs更有优势(例如,在MNLI上比gMLPs多1.8%),即使具有相似的能力和训练前的perplexity。这个问题可以通过使gMLP实质上更大来解决——3×as像Transformers一样大。一个更实用的解决方案是只加入一点点注意力——一个大小为128的单头注意力就足以使gMLP在我们用更好的参数效率评估的所有NLP任务中表现得比transformer更好。改进有时是非常显著的(例如,在我们的实验中,SQuAD 2.0比bertlarge4 +4.4%)。
gMLPs的有效性、自我注意在视觉上的益处的缺乏以及NLP中注意的个案依赖益处,都对不同领域注意的必要性提出了质疑。总的来说,我们的结果表明,自我关注并不是扩大机器学习模型的必要成分。随着数据和计算的增加,具有简单空间交互机制(如gMLP)的模型可以像Transformers一样强大,分配给自我关注的能力可以被删除或大幅减少。
2 Model
我们的模型gMLP由一个大小和结构相同的块堆栈组成。其中是具有序列长度和维数的token表示。每个块定义为:
其中σ为激活函数,如GeLU[22]。U和V定义沿通道尺寸的线性投影-与transformer的FFNs相同(例如,它们的形状为768× 3072, BERTbase为3072×768)。为了简洁起见,省略了捷径、规范和偏见。
上述公式的一个关键成分是s(·),一个捕捉空间交互作用的层(见下文)。当s恒等映射时,上述转换退化为常规的FFN,其中单个token被独立处理,而不需要任何跨token通信。因此,我们的主要重点之一是设计一种良好的能力,捕捉跨token的复杂空间交互。整体块布局的灵感来自 inverted bottlenecks[23],该 inverted bottlenecks将s(·)定义为空间深度卷积。注意,与transformer不同,我们的模型不需要位置嵌入(position embeddings),因为这些信息将在s(·)中捕获。
我们的模型使用与BERT(用于NLP)和ViT(用于视觉)完全相同的输入和输出格式。例如,在对语言任务进行微调时,我们将后跟填充的多个片段连接在一起,然后从保留的符号的最后一层表示推导出预测。尽管这些协议中有许多是为Transformer引入的,因此对于gMLP可能不是最优的,但严格遵循它们有助于避免我们的实验中的混淆因素,并使我们的层与现有的Transformer实现更兼容。
2.1 Spatial Gating Unit
要启用跨token交互,层s(·)必须包含空间维度上的收缩操作。最简单的选择是线性投影:
……(4)
其中是一个矩阵,其大小与序列长度n相同,b是一个可以是矩阵也可以是标量的偏差项。例如,如果输入序列有128个标记,那么空间投影矩阵的形状将是128×128。在这项工作中,我们将空间交互单元定义为其输入和空间转换输入的乘法:
……(5)
其中表示element-wise乘法。对于训练的稳定性,我们发现初始化W接近零值和b为1值是非常重要的,这意味着(5)式中定义的s(·)在训练开始时近似是一个单位映射。这种初始化确保了每个gMLP块在训练的早期阶段就像一个常规的FFN一样行为,其中每个token都是独立处理的,只是在token之间逐渐注入空间信息。
乘法门控可以看作是一种利用空间信号“调制”单个token表示的机制。换句话说,可以根据门控功能快速调整Z中每个元素的大小。
我们进一步发现,沿着通道尺寸将其分裂成两个独立的部分(Z1,Z2),用于门控功能和乘法旁路,就像在GLUs中通常做的那样:
……(6)
我们还将输入归一化,这从经验上提高了大型自然语言处理模型的稳定性。这为我们提供了如图1所示的单元,在本文的其余部分中,我们将其称为空间门控单元(SGU)。在表3中,我们提供了消融研究,将SGU与s(·)的其他几个变体进行了比较,结果表明,SGU效果更好,并缩小了与自我注意的性能差距。
Remark
SGU的总体公式与门控线性单元(GLUs)密切相关[24,25,26]。一个关键的区别是,我们的门槛是基于空间(交叉token)维度而不是通道(每个token)维度计算的。在元素乘法交互方面,它也类似于Squeeze-and-Excite块[27],但SGU不是做池,而是允许可学习的空间转换。SGU中的空间投影可以学习表达浅层深度卷积——与典型的基于信道特定滤波器的深度卷积不同,SGU只学习跨信道共享的单一变换。最后,我们注意到,SGUs提供了一种替代方法来捕捉高阶关系,而不是自我注意。具体来说,方程(5)的输出最多包含二阶相互作用(例如,),而自注意的输出(假设没有非线性)最多包含三阶相互作用(例如,
)。在计算成本方面,SGU有
,与
的 dot-product注意力相当。它们都是对输入通道大小的线性和对序列长度n的二次。
3 Image Classification
本文在没有额外数据的情况下,将gMLP应用于ImageNet上的图像分类任务,从而对视觉域的gMLP进行了研究。我们比较了我们的无注意力模型和最近的基于vanilla Transformer的卷积网络的专注模型,包括Vision Transformer (ViT)[7]、DeiT[8](改进正则化的ViT)等几种代表性卷积网络。
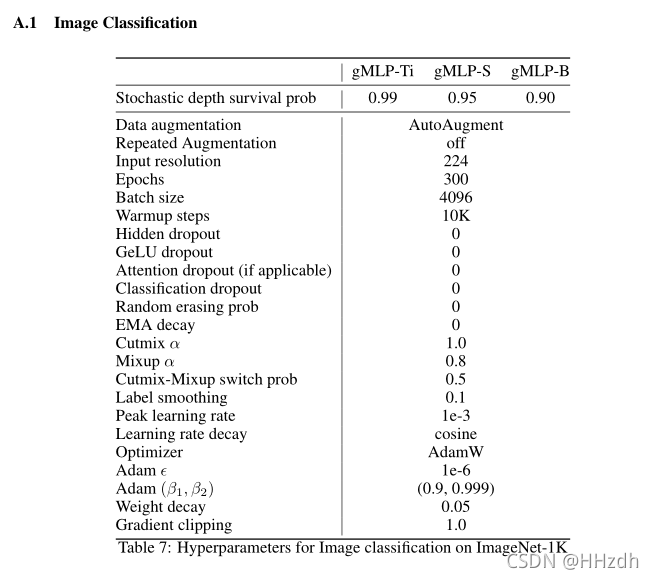
表1总结了我们的gMLP图像分类模型的配置。输入和输出协议遵循ViT/B16,原始图像在主干转换为16×16的patch。深度和宽度的选择,使模型在容量上可与ViT/DeiT相媲美。和Transformer一样,我们发现gMLP倾向于过度拟合训练数据。因此,我们使用与DeiT中使用的正则化配方相似的方法。为了避免大量的调整,我们在表1中从较小的模型移动到较大的模型时,只调整随机深度[28]的强度。所有其他超参数在我们的三个模型中都是共享的。可以查看Appendix A.1细节。

我们的ImageNet结果汇总在表1和图2中。有趣的是,gMLP与使用改进正则化训练的DeiT[8],即ViT[7]具有可比性。结果表明,在图像分类方面,无注意力模型的数据效率可以与Transformer 一样高。事实上,当这些模型被适当地规范化时,它们的准确性似乎更好地与能力而不是注意力的存在相关。此外,gMLP的精度参数/FLOPs的平衡超过了所有同时提出的类似MLP的架构[19,20,21],我们将其归因于我们的空间门控单元(Spatial Gating Unit)的有效性(见下一节的表3)。我们还注意到,虽然gMLP与 vanilla Transformers有竞争,但它们的性能落后于现有的最佳ConvNet模型(例如,[29,30])或混合注意力模型(例如,[31,10,32,33])。
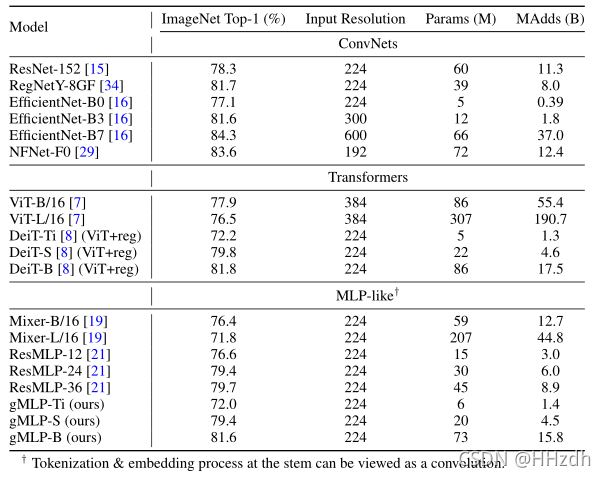
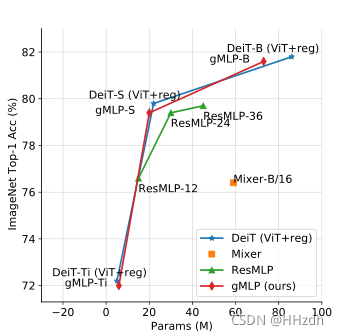
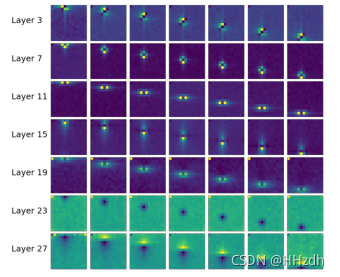
图3可视化了gMLP-B中的空间投影矩阵。值得注意的是,学习后的空间权值具有局部性和空间不变性。换句话说,每个空间投影矩阵有效地学习了与数据驱动的不规则(非方)核形状进行卷积。
4 Masked Language Modeling with BERT
5 Conclusion
自从Vaswani等人[1]的开创性工作以来,Transformers已经在NLP和计算机视觉中被广泛采用。这种采用已经产生了许多令人印象深刻的结果,尤其是在NLP方面。到目前为止,还不清楚是什么促成了这样的成功:是Transformers的前馈性质,还是Transformers中多重的自我关注层?
我们的工作深入研究了这个问题,并表明我们通常不需要太多的关注。我们发现gMLPs是MLPs的一个简单变体,带有门控,在BERT训练前的困惑和ViT的准确性方面可以与Transformers竞争。在数据和计算的可伸缩性方面,gMLP也可以与transformer相媲美。至于BERT微调,我们发现gMLP可以在没有注意力的情况下,在具有挑战性的任务上取得吸引人的结果,并且在某些情况下可以显著优于Transformers。我们还发现Transformer的多头自我注意的归纳偏差在需要交叉句子对齐的下游任务中是有用的。然而,在这些情况下,使gMLP大幅扩大缩小了与Transformer的差距。更实际的是,在gMLP中混合少量的单头注意力可以在不增加模型大小的情况下实现更好的架构。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)