什么是旋转位置嵌入(RoPE)?
这篇论文提出RoPE技术,利用了旋转矩阵的几何性质来处理位置信息
文献链接:https://arxiv.org/abs/2104.09864(🔈:第一次知道追一科技这个公司)
Transformer架构中的位置编码,有助于对序列中不同位置之间的依赖关系进行建模。这篇论文提出RoPE技术,利用了旋转矩阵的几何性质来处理位置信息,其重点是RoPE encodes the absolute position with a rotation matrix and meanwhile incorporates the explicit relative position dependency in self-attention formulation.
带RoPE技术的增强版Tranformer,被命名为RoFormer,该模型已被上传到HuggingFace中:https://huggingface.co/docs/transformers/model_doc/roformer
自注意力架构中位置编码
对自注意力机制做形式化描述:假设有带个token的输入序列
,对其进行词嵌入后得到
,其中
是token
不含位置信息的
维词嵌入向量(word embedding vector)。然后自注意力往其中加入位置信息(就
和
呐),并将其转化成查询、键和值,即
和
就会被用来计算注意力权重,以此对
进行加权求和得到输出,即
结合下面这张图就能更好地理解上述流程了(以多头注意力架构为例)
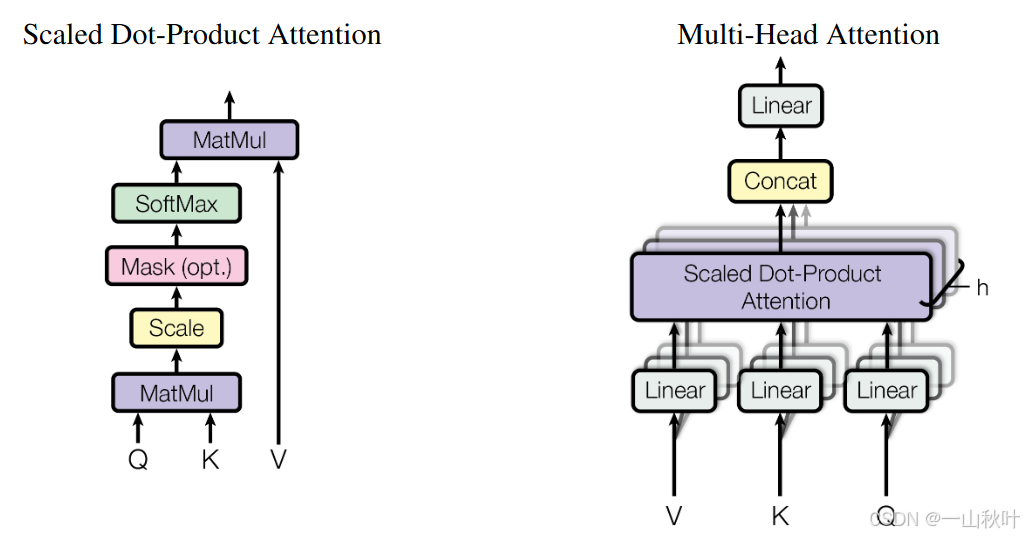
前人工作
编码 绝对位置 的经典设置是,其中
是依赖于
的绝对位置的向量,它和
这两个矩阵怎么取值就看具体实现了。
有的工作采用一个可训练的向量集合,其中L是最大的序列长度。也有使用正弦函数进行生成的
其中是d维向量
的第2t个元素。正弦这个想法还是很直觉的。
编码 相对位置 时有篇工作对Q、K、V的获取运用下列式子:
其中、
都是可训练的相对位置的嵌入向量,
代表位置
和
之间的相对距离,做了裁剪(clip)是觉得精确的相对距离在超出一定范围后就没有意义了。
还有一篇工作沿用、
的经典设置,代入
,得到(全文中的“
分式”均指代下列式子)
核心思想是对 “分式” 进行改造,将绝对位置编码
替换成相对位置的正弦编码
,
替换成两个与查询位置无关的可训练的向量
和
,
被分为基于内容
的向量
和基于位置
的向量
,得到
值得注意的是其设置,值这一项中的位置信息被抹除了。后续还有很多工作沿用了这一设置,只是将相对位置信息编码到了注意力权重中。但也有工作直接将 “
分式” 改造成下式:
其中是一个可训练的偏置项。
有工作研究过 “分式” 的中间两项,发现在绝对位置和单词之间的关联很小。另一篇工作提出用不同的投影矩阵对一对单词或位置进行建模:
再一篇工作却认为两个token之间的相对位置只能用 “分式” 中间两项完全建模,于是绝对位置向量
和
被简单地替换成了相对位置向量
:
上面对 “分式” 的四种变体,有比对说最后一种最高效。它们都在放缩点积自注意力设置下对
进行解构,以调整 “
分式” ,将位置信息添加到上下文表示中。
这并不适合线性自注意力架构(可见博客中的相关介绍)。线性注意力通过核近似、线性重排避免显式构造的注意力矩阵,但同时也破坏了位置编码的逐对交互传播路径。关键矛盾就在于位置编码需要显式的位置感知交互,而线性注意力旨在消除这种交互以提升效率,便需要设计位置信息与线性计算兼容的机制(如核函数融合或隐式编码)。
为何会将向量写成复数形式?
复数形式将二维向量的长度和方向“打包”成一个数,可极大简化某些数学运算,尤其是涉及旋转、相位或周期性变化的问题。
1. 复数的几何意义
复数在复平面上表示一个向量,其中模长R对应向量长度,相位
对应向量的角度(从实轴正方向逆时针旋转),等价性:
2. 旋转计算
在笛卡尔坐标下,将一个向量逆时针旋转角,得到新向量需要矩阵乘法:
而复数解法直接乘以即可:
适用于机器人运动学(关节旋转)、计算机图形学(物体旋转)、信号处理(相位调制)……
3. 相位差(相对角度)计算
利用复数的共轭内积
其中模长部分表示向量长度的影响,相位部分
直接给出角度差。
适用于Transformer的位置编码(RoPE)、通信信号解调(载波同步)、量子力学(波函数相位)
4. 简化震动和波动问题
描述简谐振动,
用复数表示:。便可轻松得到
速度
加速度
适用于电路分析(交流电)、机器振动(弹簧-质量系统)、电磁波(光的偏振)
关于复数
一个n维的复数向量可以表示为
其中每个分量本身就是一个复数,包含独立的实部和虚部:
可以将拆分为两个实数向量:
这种拆分常用于数值计算或可视化(例如将复数向量映射到),然后便可将向量
表示为实向量和虚向量的线性组合:
对于两个高维复数向量,求内积需要对第二个向量取共轭:
逐分量相乘求和,最终结果是一个复数。常用实部(和实数向量内积一致)。为什么是共轭相乘呢?为了
模长为正:;Hermitian对称性:
高维复数向量常用于量子力学(量子态)、信号处理(多通道频域信号)、机器学习(复数神经网络或RoPE等位置编码中,高维复数运算能捕捉更复杂的变换),是许多数学和工程领域的基石。
旋转操作
前文中提到的会在不同位置的token之间知识传递,在此之前,如何添加位置信息?在RoPE中,并不是用加这类简单的方式,而是让每个词的表示向量像时钟指针一样随着位置旋转,通过旋转操作来实现位置嵌入。
考虑两个分别对应Q和K的词嵌入矩阵和
,位置分别是m和n,对应的位置编码是
假设存在函式来定义由
产生的向量间的内积:
、
、
这几个函数长什么样?以二维为例,利用向量在二维平面上的几何性质及其复数形式得到的结论就是
其中:复数
的实部;
:
的共轭复数;
:预设的非零常数。
证明:利用二维向量的几何意义及其复数形式做一个分解(将向量表示成极坐标的形式-》映射到复平面上-》表征一个复数):
其中和
分别代表
和
的径向分量(模长)和角向分量(相位)。复数域的内积定义为
(共轭相乘)(共轭转置的本质是对复数相位取负)(正确性),故
得到的内积结果是个复数(欧拉公式)(其实部就是经典的点积结果)(虚部是二维向量的叉积/面积),核心思想是通过极坐标分解,将内积的模和相位显式化(模长表示强度)(相位表示相对关系),以编码相对位置信息。结果就是(模长相乘)(相位相减):
另外还要求满足初始条件:、
,可看作是带空位置编码的向量,有:
其中和
分别代表
和
在二维平面上的径向部分和角向部分。假设
,把初始条件考虑进来,就会有:
说明径向函数与位置信息无关,有
同时由可知角向函数不依赖于是query还是key,那不如设置
(即query和key的旋转位置编码共享同一组旋转角度参数)(都定义为
)。将
看作位置m的函数
,与词嵌入向量
无关,即
当时,可以得到
等式右侧是一个与无关的数,故可将
视作一个等差序列
其中是常数,
非零,故总结下来就是
注意到前面并未加以限制呀,为了和经典设置对应起来,定义
再简单设置,最终得到
将写成矩阵乘法的形式(逆时针旋转
角):
其中是
的二维坐标表示。通过旋转,相对位置编码也能被映射到向量空间中,自然地融入了相对位置信息。
从二维到高维
由于内积满足线性叠加性,故任意偶数维的RoPE都可以表示成二维情形的拼接:当向量维度为偶数时,将
维空间划分为
个子空间(第
个子空间的二维向量逆时针旋转
角),再利用内积的线性性质将它们结合起来。有
其中旋转矩阵的通式为
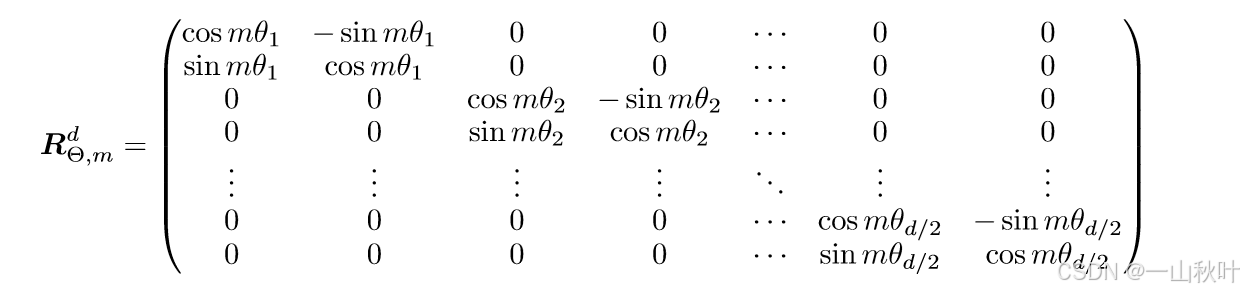
预先定义,为什么要对每组特征分配不同的频率基呢?
希望不同维度的特征能捕捉不同粒度的位置模式,实现多尺度位置感知。高频基(大角度旋转)用来捕捉位置变化(如相邻token的位置差异);低频基(小角度旋转)用来捕捉全局位置关系(如长期依赖),避免特征冗余或表达能力受限,就像信号处理中需要不同维度的正弦波组合才能完整表示一个信号。
RoPE的关键性质在于两个向量的内积仅依赖于它们的相对位置,要求每组特征的旋转角度是独立的(不同频率基),且频率基足够分散。
RoPE作者实验也发现,使用指数衰减的频率基比单一频率基或线性分布的基更有效。消融研究也得出共享频率基会导致模型在长序列任务上的性能显著下降。
RoPE实现
将RoPE应用到自注意力架构上,就会得到
其中。图解如下
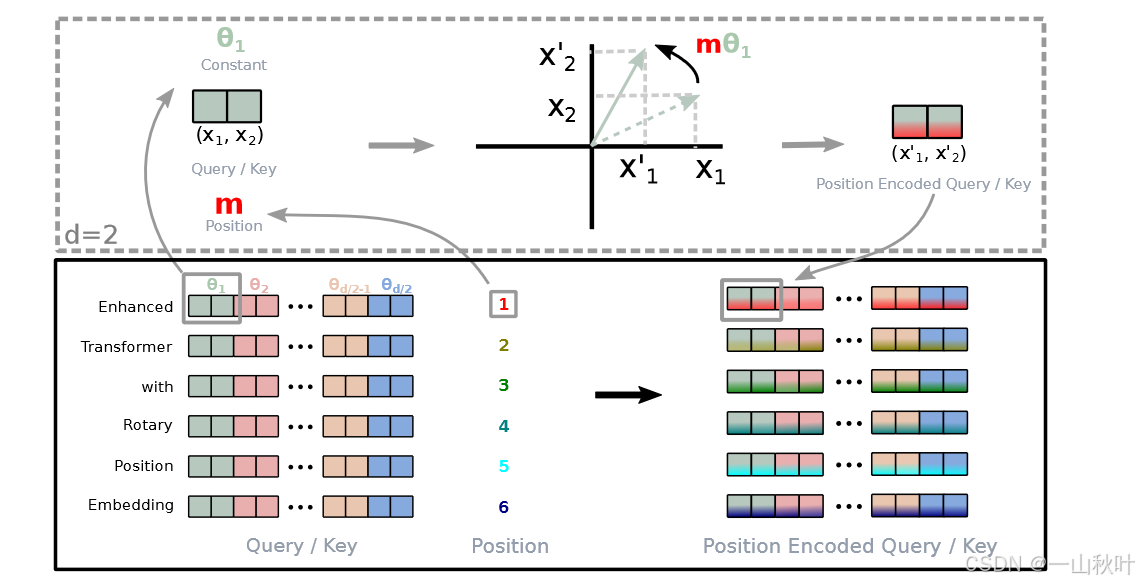
明显是一个正交矩阵,确保了在位置编码过程中的稳定性。正交矩阵是一个实数方阵,其列/行向量两两正交且长度为1,其逆矩阵等于转置矩阵,在几何意义上,其作用是旋转或反射向量,但不改变向量的长度(保范性)。对任意向量
,有
,便能避免在多层网络传递时位置编码对向量范数的干扰(如数值爆炸或消失);正交变换不会扭曲向量空间的结构,两个词向量的夹角(相似度)仅由位置差决定,与绝对位置无关;在长文本中,正交变换能保持位置编码的数值范围一致,无论位置m多大,
的数值都不会剧烈变化。
但由于的稀疏性,将其整体直接应用到矩阵乘不见得计算高效,一种计算
和
之间乘积更有效地方法是
其中是逐位对应相乘,即Numpy、Tensorflow等计算框架中的*运算。从这个实现也可以看到,RoPE可以视为某种乘性位置编码的变体。
PS:有时候看到下列的实现也不要奇怪,只要同一个下标的只跟两种下标的
产生关联就好了
就是组成一个复数的两个维度不一定相邻,也可以是按其它规律排布,比如说隔固定位置。
LlaMA注意力中的代码实现单独摘出来,初始化了一个样例看看吧:
# 旋转位置编码代码解析
batch_size = 2
seq_len = 4
last_len = 2
num_heads = 4
num_kv_heads = 2
head_dim = 8
import torch
from torch import nn
import torch.nn.functional as F
# 定义旋转嵌入层
class LlamaRotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embedding=2048, base=10000, device=None):
super().__init__()
self.dim = dim # 嵌入层维度大小(int)
self.max_position_embeddings = max_position_embedding
self.base = base
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq)
self._set_cos_sin_cache(seq_len=max_position_embedding, device=self.inv_freq.device, dtype=torch.get_default_dtype(),)
def _set_cos_sin_cache(self, seq_len, device, dtype):
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=self.inv_freq.dtype)
# 使用Einsum求和约定,计算张量t和self.inv_frea的外积,输出形状为[seq_len, dim/2] (m*theta)
freqs = torch.einsum("i,j->ij", t, self.inv_freq)
# [32, 8]
emb = torch.cat((freqs, freqs), dim=-1)
# 为了兼容不同的应用场景和高效的广播计算,缓存时添加batch_size和num_heads两个维度 [1, 1, 32, 8]
self.register_buffer("cos_cached", emb.cos()[None, None, :, :].to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin()[None, None, :, :].to(dtype), persistent=False)
def forward(self, x, seq_len=None):
if seq_len > self.max_seq_len_cached:
self._set_cos_sin_cache(seq_len=seq_len, device=x.device, dtype=x.dtype)
# 返回当前序列部分 [1, 1, 6, 8]
return(
self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype)
)
def rotate_half(x):
x1 = x[..., : x.shape[-1]//2]
x2 = x[..., x.shape[-1]//2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
cos = cos.squeeze(1).squeeze(0)
sin = sin.squeeze(1).squeeze(0)
# 索引position_ids[batch_size=2, seq_len=4],被索引者cos[kv_seq_len=6, head_dim=8]
# 索引张量A只会对被索引张量B的第一个维度进行索引,结果的形状就是将B的第一个维度替换为A的维度
# [2, 4, 8]->unsqueeze->[2, 1, 4, 8]
cos = cos[position_ids].unsqueeze(1)
sin = sin[position_ids].unsqueeze(1)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
kv_seq_len = seq_len + last_len # 完整序列的长度
query_states = torch.rand(batch_size, num_heads, seq_len, head_dim)
key_states = torch.rand(batch_size, num_kv_heads, seq_len, head_dim)
value_states = torch.rand(batch_size, num_kv_heads, seq_len, head_dim)
position_ids = torch.arange(seq_len, dtype=torch.long).unsqueeze(0).expand(batch_size, -1)
rotary_emb = LlamaRotaryEmbedding(head_dim, max_position_embedding=32)
cos, sin = rotary_emb(value_states, seq_len=kv_seq_len)
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)RoPE的性质
1. 长期衰减:
前文说过,我们设置,当相对位置增加时内积会衰退,和我们认为隔得越远的token之间联系越少的直觉是吻合的。
对向量和
的元素进行两两分组,将RoPE的内积写成复数乘法:
其中代表query向量第2i和第2i+1维组成的复数(实部为
、虚部为
),
为key向量对应维度的共轭复数。记
、
,初始化
、
,利用Abel变换(分部求和公式),重写求和式子:
下式求的是一个复数的模的相对上界,绝对值的作用是量化注意力分数的大小,反应query和key的匹配程度。声明一下,复数内积的结果的实部是最终的注意力分数,但模长
也表征了复数内积的强度,反应“潜在的最大相似度”。
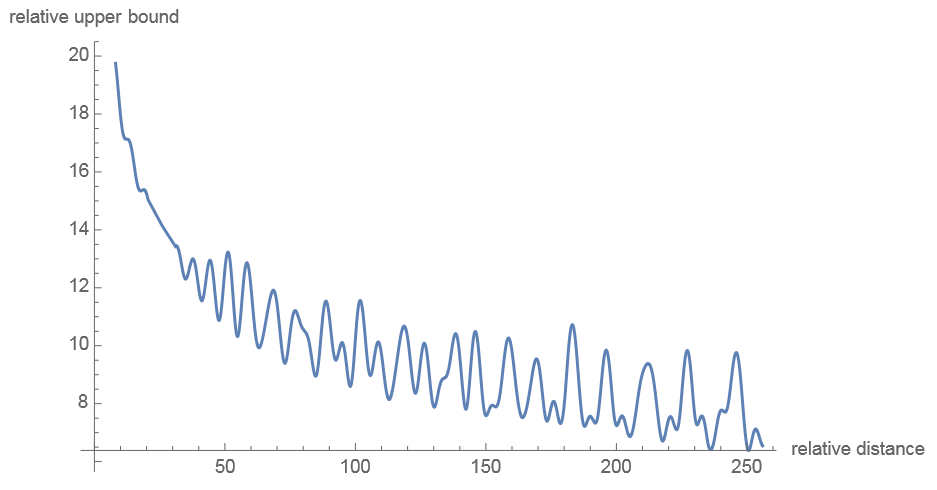
其中通过设置,
会随着相对距离
的增加而衰减,如下图:
若直接分析实部,需考虑相位对齐,推导更复杂(如),分析模长的优势就在于可以忽略相位,直接通过
的衰减特性给出普适性结论。
2. RoPE下的线性注意力
线性注意力机制可以被改写成更普适的形式:
原始自注意力选择,会计算每一对query和key的内积,造成复杂度
,20年有人提出线性注意力,将该式改写成:
其中通常是非负函数,当年那位作者提出
,利用矩阵的结合律优化计算。其中
21年有人提出在内积前分别对query和key做独立归一化处理,有、
。更多细节还是看原论文吧。
在这里,可以通过将旋转矩阵和非负函数的输出相乘,实现RoPE和线性注意力的结合:
分母保持不变是为了避免除零,在分子的求和项中允许包含负项,尽管式中每个值的权重并不是严格概率归一化的,但该计算仍可对值的重要性进行建模。
实验和评估
作者在各式NLP任务上评估了RoFormer。在机器翻译任务上,在预训练阶段比对了RoPE和BERT;在预训练模型的基础上,进一步在GLUE基准上对不同的下游任务进行评估;还用结合线性注意力的RoPE进行实验;最后在中文数据上做了额外的测试。所有实验都在两台带4张V100 GPU的云服务器上进行的。
机器翻译
先证明了RoFormer在Seq2seq语言翻译任务上的性能表现。
选择标准的WMT 2014英语-德语数据集,由大约4.5百万个句子对组成,以原始Transformer作为基线进行比对。作者在原始Transformer的自注意力层引入RoPE;源语言(英语)和目标语言(德语)共享一个37k的字词词汇表,减少未登录词(OOV)问题,提升罕见词处理能力;训练结束后,取最后5个检查点的模型参数平均作为最终模型,提升鲁棒性;采用束搜索,设置beam size=4,即每步保留 4 个最可能的候选序列,并设置length penalty=0.6
长度惩罚有什么用?
在标准的束搜索中,搜索目标是找到最大概率的序列:
这是一个乘法结构,或者说是对数下的累加结构:
较短的句子往往有更大的概率值(因为乘的小数少,或者说加的负数少),所以会倾向于生成短句,但在实际应用中(如机器翻译、文本生成),过短的句子往往不完整或不自然,故引入长度惩罚,目标变成:
其中表示生成序列的长度,
是表示惩罚力度的超参数,最优值需在开发集上调优。
代码是在PyTorch+Fairseq工具包的框架上实现的,模型采用Adam()优化器进行优化,学习率先进行线性预热(
到
),然后再按照逆平方根进行衰减(
),还采用了系数为0.1的标签平滑
什么是标签平滑?
一种正则化技术,用于缓解模型过度自信地预测某个类别的问题。在标准分类中通常采用ont-hot标签,标签平滑会把这个“硬标签”变成一个“软标签”,即对其它类别也分一点点概率,以避免模型认为某个答案是百分百正确。给定类别数为,平滑系数
,目标类别为
,则
采用BLUE分数作为最终的评估指标。结果就是RoFormer更好:

预训练语言建模
然后是验证方案在学习上下文表征方面的表现。
采用Huggingface数据库中的BookCorpus(主要用于图像描述任务,包含超过11000本英文小说,大部分是虚构类)和Wikipedia Corpus(所有英文维基百科页面的文本,经过清洗、去重和段落级组织)两个数据集进行预训练(两个数据集都是预训练语言模型的经典预料来源,它们的组合提供了多样的语言风格,前者提供自然能对话、小说式文本,后者提供事实性、知识性文本,预训练模型通过自监督学习在这些预料上学习语言规律),将这些语料按8:2划分训练和验证集。采用训练过程中带掩码的语言模型(masked language-modeling, MLM)损失值作为评价指标。以bert-base-uncased作为基线进行比对
什么是bert-base-uncased?
Bert有两个最常用的变体:
| 模型名 | 层数(Transformer) | 隐藏维度 | 注意力头数 | 参数量 |
| bert-base | 12 | 768 | 12 | 110M |
| bert-large | 24 | 1024 | 16 | 340M |
bert-base是一个中等规模版本,计算量较小,适合多数任务。“uncased”意味着词表中不区分大小写,所有英文文本输入前都会被转为小写。
在预训练阶段,将BERT原有的 正弦位置编码 替换为RoPE,修改自注意力机制。批量大小设为64、最大序列长度为512,训练100k步,采用AdamW优化器,学习率设为。
预训练期间MLM损失如下图,相较于原始的BERT,RoFormer收敛更快:
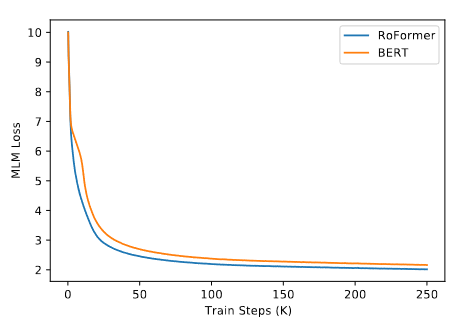
在GLUE任务上进行微调
通过不同的GLUE任务对预训练的RoFomer的权重进行微调,以评估其在下游NLP任务上的泛化能力。
查看了几个GLUE基准中的数据集,如MRPC(Microsoft research paraphrase corpus,判断两句话是否是同义句)、SST-2(Stanford Sentiment Treebank v2,判断电影评论句子的情感是正面还是负面)、QNLI、STS-B、QQP、MNLI。对数据集MRPC和QQP数据集采用F1-score作为评估指标、对STS-B采用spearman,其余的看准确率。
使用HF库对上述下游任务微调3个epoch,最大序列长度设为512、批量大小32、学习率在2、3、4、5e-5,在验证集上的最佳平均结果如下,在6个数据集中有3个性能是明显优于BERT:

带RoPE的Performer
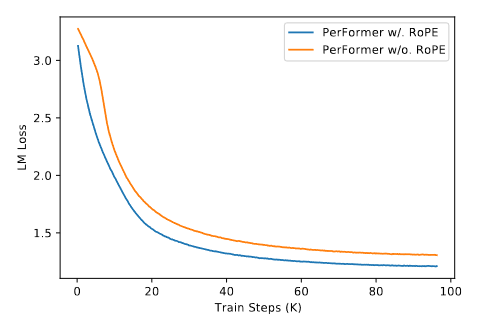
Performer引入了线性注意力机制,RoPE可以轻松集成到其中,在保持自注意力中线性扩展的复杂度的同时实现相对位置编码。作者在语言建模的预训练任务中展示了它的能力。
选用Enwik8数据集进行测试,其来自英文版维基百科,除英文文本外,还包括标记、特殊字符和其它语言的文本。将RoPE融入到一个具有12层、基于字符的PerFormer模型中,其隐藏维度为768,注意力头数为12。设置学习率1e-4、批量大小128、最大序列长度1024,比对在有无RoPE两种设置下预训练过程中的损失曲线如下,加了RoPE后在相同训练步数下收敛更快、损失更低:
在中文数据上的测评
除了在英文数据上进行实验外,作者也额外展示了在中文数据上的结果。为了证明RoFormer在长文本上的性能, 作者测试了一个长度超512个字符的长文本。
对WoBERT进行调整,用RoPE替换绝对位置编码,再拿来和其它基于Transformer的在中文上预训练的模型(BERT、WoBERT、NEZEA)进行交叉比对,它们的分词水平和位置嵌入信息如下:

从中文版维基百科、新闻和论坛上收集将近34GB数据用来预训练RoFormer,为了使模型适用不同场景,预训练分多个阶段进行,并调整批量大小和最大输入序列长度。结果如下,RoFormer的准确度随着最大序列长度增大而提升,证明了RoFormer在处理长文本上的能力,得益于RoPE出色的泛化能力。
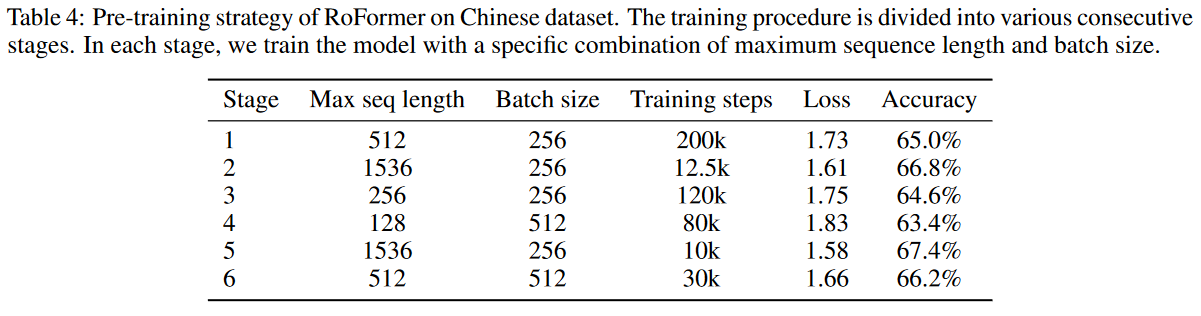
作者选择Chinese AI and Law 2019 Similar Case Matching (CAIL2019-SCM)数据集来说明RoFormer在处理长文本上的能力(例如语义文本匹配),CAIL2019-SCM均是来自于中国最高人民法院发布的案例,有8964个三元组,每个输入的三元组(A, B, C)对应三种对事实描述,任务就是,在预定义的相似度度量下,预测(A,B)是否比(A,C)更接近,之前的方法在这个数据集上表现大多因为文本长度(多数超过512个字符)表现一般。作者基于常见比例6:2:2划分训练、验证和测试集。
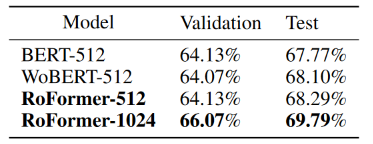
将预训练好的RoFormer应用到不同长度的CAIL-2019-SCM数据集上,和在相同预训练数据下的模型BERT、WoBERT进行比对。在像512这样的短文本下,RoFormer的结果可与WoBERT相当,略好于BERT,但当最大输入长度加到1024时,RoFormer比WoBERT绝对提高了1.5%
尽管有种种理论证明和实验结果验证,但这篇论文的内容还是有以下缺陷:
尽管旋转位置编码在数学上将相对位置关系格式化为2D子空间下的旋转,但对于它为什么比其它位置编码收敛更快,缺乏解释。
尽管作者已证明在计算查询(Query)和键(Key)向量之间的内积的过程中,RoFormer有不错的长期衰减性,其它位置编码机制类似,但为什么本方法在长文本中表现出更优的性能,作者没有解释。
RoFormer建立在Transformer架构之上,预训练还是需要一定的硬件资源。
结论
这篇工作提出了一种位置编码方法,在自注意力机制中结合显式的相对位置依赖关系,提升transformer架构性能;作者通过理论证明了相对位置信息可以在向量中自然形成,并通过旋转矩阵编码绝对位置信息;也从数学上分析了当它被应用到Transformer上时能带来的好处;最后,在中英文基准测试上的实验也证明了,旋转位置编能使预训练时更快收敛,在长文本任务上性能更好。
改进方向之动态NTK缩放
如何让预训练模型无需微调即可处理更长的序列呢?
预训练模型的RoPE位置编码通常有固定的最大长度,直接外推会导致性能下降。原来有:
它两一外积就能得到所有维度所有位置的旋转角度。
线性缩放(linear scaling)通过线性降低RoPE的频率,使得位置编码能覆盖更长的序列,同时保持相对位置关系。比如 。但是,简单的线性缩放虽能扩展长度,却会均匀压缩所有频率维度,导致高频位置信息丢失(影响局部注意力)。
Dynamic NTK Scaling源自神经切线核(Neural Tangent Kernel, NTK)理论,这个术语被GPT-NeoX、LLaMA、GPT-4技术栈中的工程实现广泛采用,其核心思想是:
- 高频维度:
较小,旋转角变化快,适合短程依赖,需保持高分辨率(不压缩或少压缩)
- 低频维度:
- 动态调整:根据当前输入序列长度,实时计算最优的base值
调整base(变大):
对于高频维度,由于较小,受到base变化的影响不大,而对于低频维度,由于
较大,调整后直接扩展了位置编码的有效范围。
上述动态调整base的式子源于Llama注意力部分的代码,该设置背后有很强的理论动机和经验支撑。代码实现LlamaRotaryEmbedding的子类LlamaLinearScalingRotaryEmbedding和LlamaDynamicNTKScalingRotaryEmbedding。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)