构建信用卡客户风险识别模型
实验名称 构建信用卡客户风险识别模型
实验目的 :
1、掌握异常值的识别与处理方法。
2、构建信用卡用户风险分析关键特征。
3、掌握 K-Means 聚类算法的应用。
4、掌握聚类算法结果分析的方法。
5、不得抄袭,发现后按0分处理
6、按照大三实验报告模板撰写实验报告
实验环境:
1、硬件要求:计算机一台
2、软件要求:Chrome浏览器、Anaconda
3、网络要求:能访问互联网
实验步骤和内容:
需求说明:为了推进信用卡业务良性发展减少坏账风险,各大银行都进行了信用卡客户风险识别的相关工作,减少坏账风险,各大银行都进行了信用卡客户风险识别的 相关工作。某银行研究的风险识别模型随时间推移不再适应业务发展需求,需要 重新进行风险识别模型构建。
实验内容
为了推进信用卡业务良性发展,减少坏账风险,台湾各大银行都进行了信用卡客户风险识别相关工作,建立了相应的客户风险识别模型。某银行因旧的风险识别模型随时间推移,不再适应业务发展需求,需要重新进行风险识别模型构建。
(一)处理信用卡数据异常值
实验步骤
(1) 读取信用卡数据。
(2) 丢弃逾期,呆账,强制停卡,退票记录,拒往记录为 1,瑕疵户为 2的记录。
(3) 丢弃呆账,强制停卡,退票为 1,拒往记录为 2 的记录。
(4) 丢弃频率为 5,刷卡金额不等于 1 的数据

图1 数据处理
(二) 特征选取
特征的轩主主要是以下三个方面。
- 根据特征瑕疵户,逾期,呆账,强制停卡,退票,拒往记录构建历史行为特征。
- 根据特征借款余额,个人月收入,个人月开销,家庭月收入和月刷卡金 额,构建出经济风险情况特征。
- 根据特征职业,年龄,住家,构建出收入风险情况特征。
- 将历史行为特征,经济风险情况特征以及风险情况特征分别进行降维。



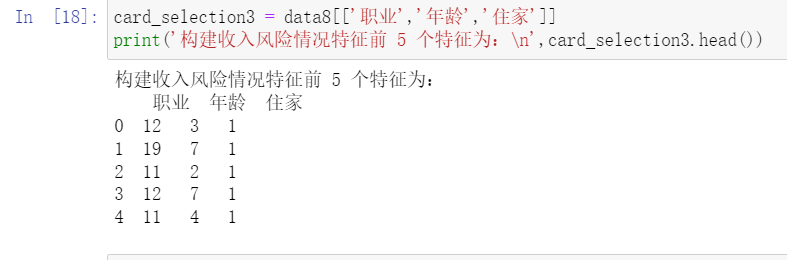
图2 特征提取
特征合并 。选取完所需的特征之后,将相关特征列合并
(三)构建模型
最近做了一个数据挖掘的项目,挖掘过程中用到了K-means聚类方法,但是由于根据行业经验确定的聚类数过多,并且并不一定是我们获取到数据的真实聚类数,所以,我们希望能从数据自身出发去确定真实的聚类数,也就是对数据而言的最佳聚类数。为此,我查阅了大量资料和博客资源,总结出主流的确定聚类数k的方法手肘法。手肘法的核心指标是SSE(sum of the squared errors,误差平方和),手肘法的核心思想是:随着聚类数k的增大,样本划分会更加精细,每个簇的聚合程度会逐渐提高, 那么误差平方和SSE自然会逐渐变小。并且,当k小于真实聚类数时,由于k的增大会大幅增加每个簇的聚合程度,故SSE的下降幅度会很大,而当k到达真实聚类数时,再增加k所得到的聚合程度回报会迅速变小,所以SSE的下降幅度会骤减,然后随着k值的继续增大而趋于平缓,也就是说SSE和k的关系图是一个手肘的形状,而这个肘部对应的k值就是数据的真实聚类数。当然,这也是该方法被称为手肘法的原因。对于K-Means方法,k的取值是一个难点,因为是无监督的聚类分析问题,所以不寻在绝对正确的值,需要进行研究试探。这里采用计算SSE的方法,尝试找到最好的K数值。编写函数如下:
构建 K-Means 聚类模型,聚类数为 4。
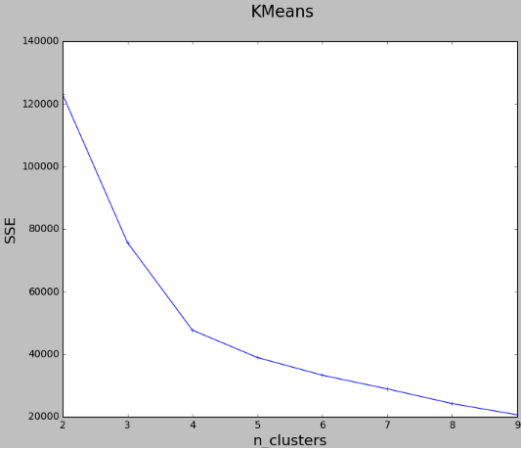
图3 手肘法
训练模型,求出聚类中心、每类的用户数目。
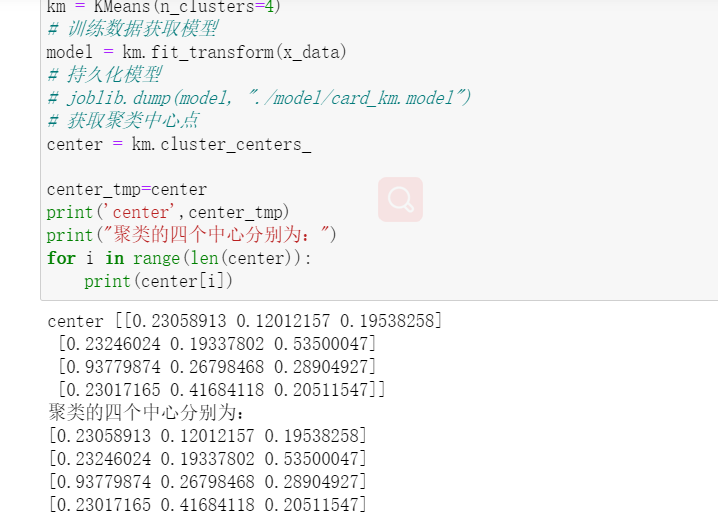
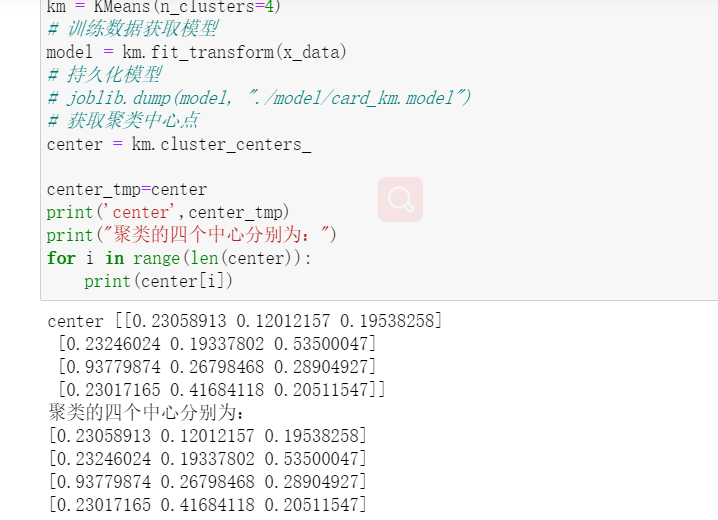
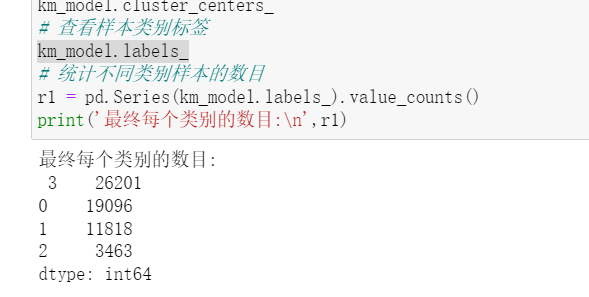
图4 求出聚类中心、每类的用户数目
(四)结果分析
雷达图
图5 雷达图
客户特征分析图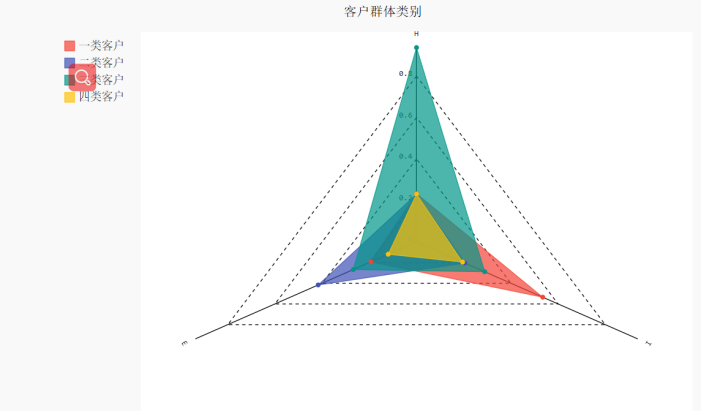
图6 客户特征分析图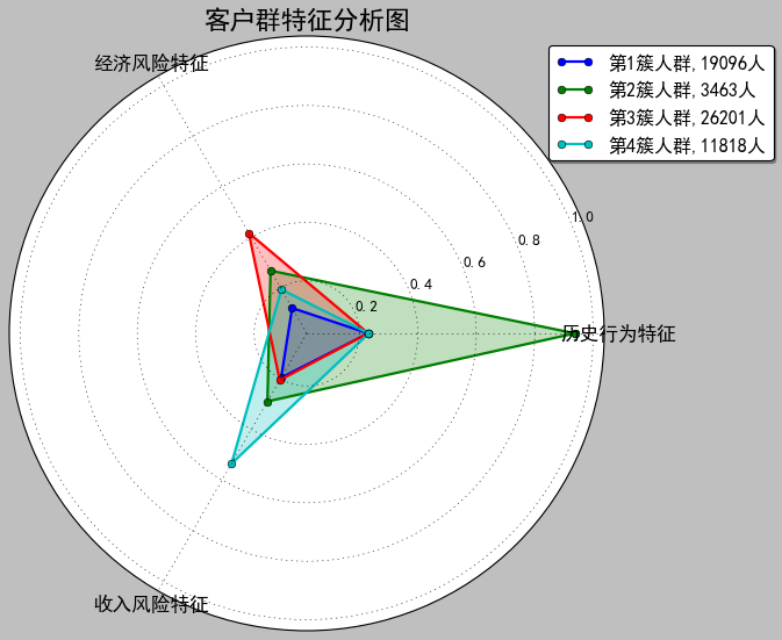
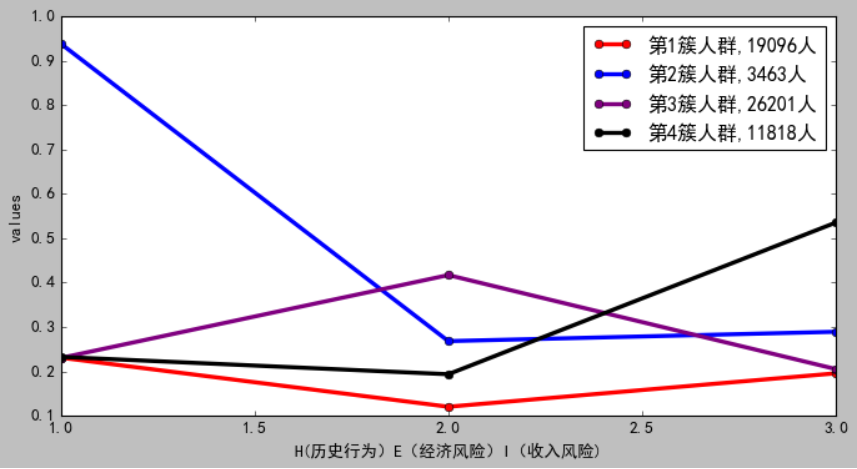
图6 客户特征分析图
根据 H(历史行为)E(经济风险)I(收入风险)数据,我们可以对客户进行评
价分析。
客户价值分析,我们希望用户是低H,高E和高I
我们重点关注的是 H,E,I,从 HEI 图中可以看到:
1、一类客户 [red] H,E,I,都很低,可以看做是一般客户
2、二类客户[blue] H很高,E,I,都很低, 可以看做是用户价值低客户
3、三类客户[purple] E很高,H,I,都很低,可以看做用户价值高客户,重点保持客户
4、四类客户[black] I 特别高,其余都较低,可以看作是重要发展客户
以下再结合具体的特征定义四个等级的客户类别,针对不同等级的客户,采取相
应的营销手段和策略,为信用卡客户风险的客户群管理提供参考(即业务分析)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)