机器学习_07 随机森林
本文主要讲解了随机森林的基本概念、随机森林模型的创建并训练以及模型评估等内容
目录
一、前言
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
二、基本概念
1、随机森林
(1)随机森林(Random Forest, RF)是一种由 决策树 构成的 集成算法 ,采用的是 Bagging 方法,他在很多情况下都能有不错的表现。
(2)假若随机森林的基学习器(个体学习器)如下:
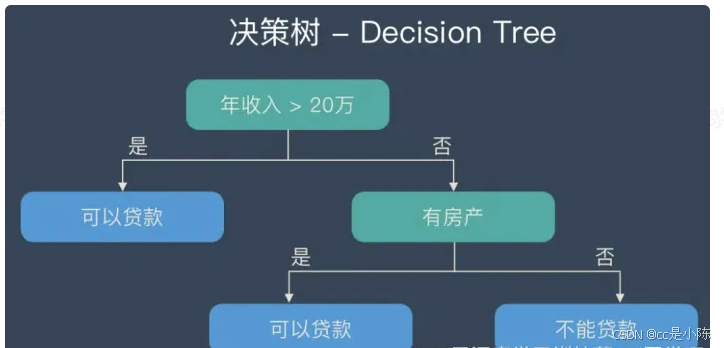
(3)那么随机森林则是如下结构,其是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
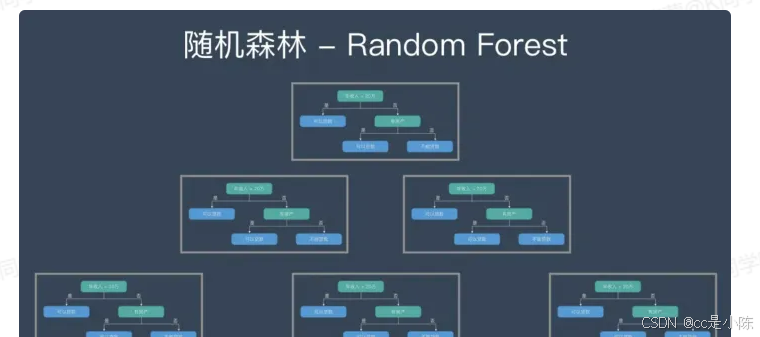
三、随机森林模型
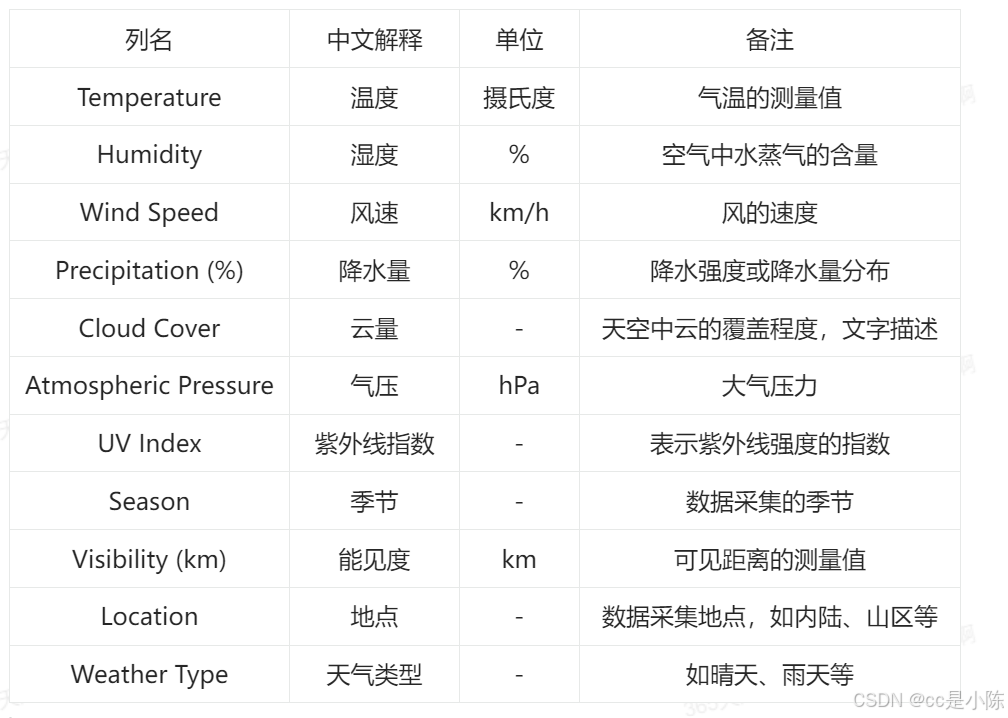
该案例使用了一个人工合成的天气数据集,模拟了雨天、晴天、多云和雪天四种类型,在分析过程中,对数据进行了异常值处理,并通过描述性统计对数据进行了初步探索,接着,构建了随机森林模型进行预测,并生成了模型的重要特征图,该项目适用于初学者学习如何进行全面的数据分析和机器学习模型构建。数据集字段详情如下:
1、导入库
#1、导入库
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
from matplotlib import pyplot as plt
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,confusion_matrix,classification_report
warnings.filterwarnings('ignore')
# 正常显示中文和负号
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False2、加载数据集
#2、加载数据
weather_data = pd.read_csv(r"D:\Desktop\CC是小陈\Machine Learning\weather_classification_data.csv")
print(weather_data.head())
print(weather_data.columns)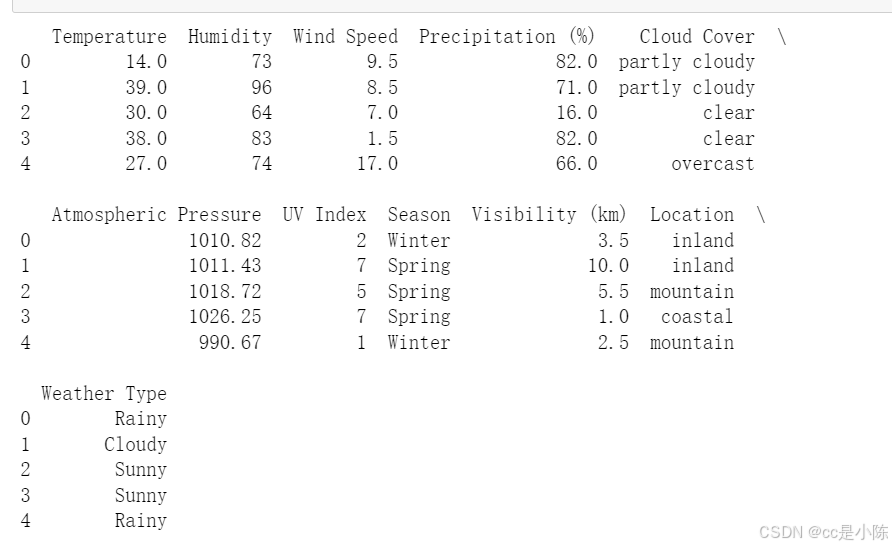
3、查看数据的基本信息
#3、查看数据基本信息
print(weather_data.info())
print(weather_data.shape)
print(weather_data.describe())
print(weather_data.isnull().sum())4、数据预处理
(1)查看分类型数据的唯一值
#4、数据预处理
#查看分类特征的唯一值
print(weather_data.columns)
charactor_columns = ['Cloud Cover','Season','Location','Weather Type']
for i in charactor_columns:
print(weather_data[i].unique())
print('*'*50)
(2)对数值型数据进行可视化
#对数值型数据进行可视化
feature_map = {
'Temperature': '温度',
'Humidity': '湿度百分比',
'Wind Speed': '风速',
'Precipitation (%)': '降水量百分比',
'Atmospheric Pressure': '大气压力',
'UV Index': '紫外线指数',
'Visibility (km)': '能见度'
}
plt.figure(figsize=(15,10))
#enumerate()函数:这个函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标
# 遍历字典,并打印位置、索引和值
# item()方法返回字典中的键和值
#1 用于指定索引值,即索引从1开始
for i,(col,col_name) in enumerate(feature_map.items(),1):
plt.subplot(2,4,i)
sns.boxplot(y=weather_data[col])
plt.title(f'{col_name}的箱线图',fontsize=12)
plt.ylabel('数值',fontsize=12)
plt.grid(linestyle='--',alpha = 0.2)
plt.tight_layout() #自动调整子图之间的参数,以最小化或消除子图之间的空白边距
plt.show()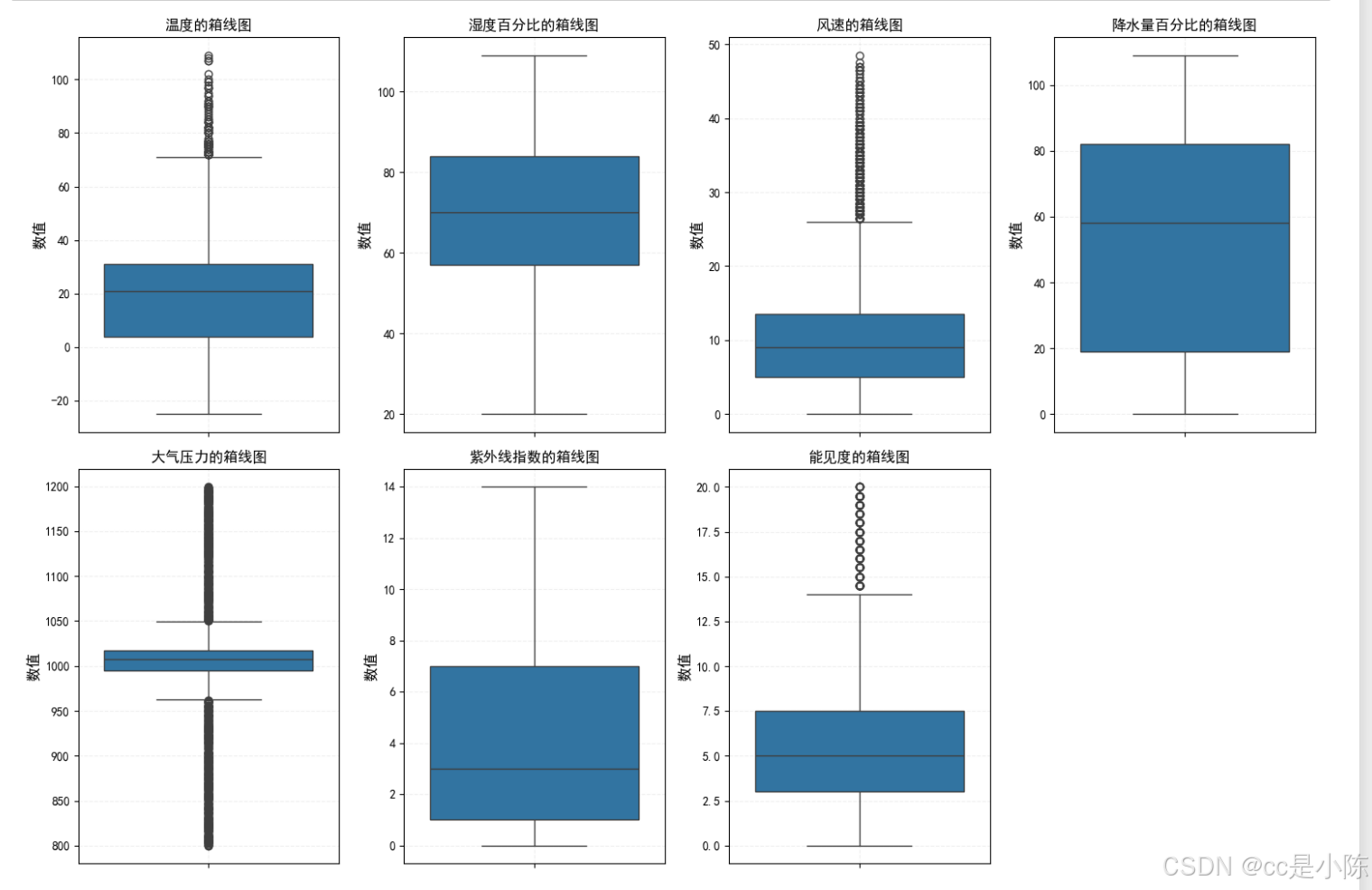
- 温度的异常值存在大量超出常识的温度,这里以超过60摄氏度认定为异常值,需要进行处理;
- 湿度百分比和降水量百分比,由于数值存在超过100%的值,认为超过100%的值为异常值,需要进行处理;
- 风速的高值可能是由于台风、龙卷风等极端天气事件,故不处理;
- 大气压力的异常值可能由于高海拔地区或气象现象(如低气压系统)引起;
- 能见度低可能是由于雾霾、雨雪等天气现象,这些异常值在特定条件下是正常的,故不处理;
(3)处理异常数据
print(f"温度超过60°C的数据量:{weather_data[weather_data['Temperature'] > 60].shape[0]}," # 以元组形式返回,然后获取总数
f"占比{round(weather_data[weather_data['Temperature'] > 60].shape[0] / weather_data.shape[0] * 100,2)}%。")
print(f"湿度百分比超过100%的数据量:{weather_data[weather_data['Humidity'] > 100].shape[0]},"
f"占比{round(weather_data[weather_data['Humidity'] > 100].shape[0] / weather_data.shape[0] * 100,2)}%。")
print(f"降雨量百分比超过100%的数据量:{weather_data[weather_data['Precipitation (%)'] > 100].shape[0]},"
f"占比{round(weather_data[weather_data['Precipitation (%)'] > 100].shape[0] / weather_data.shape[0] * 100,2)}%。")
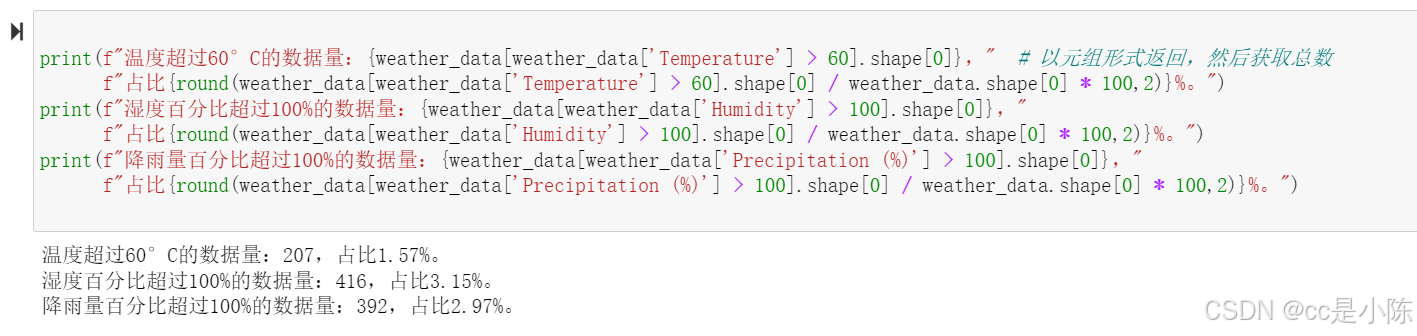
异常值占比很小,这里可以直接删除,或者将其赋值为100%,为了保持数据集的一致性和准确性,这里选择直接删除,可以避免它们对分析结果或模型训练产生负面影响。
#异常值处理
print("删前的数据shape:", weather_data.shape)
weather_data_new = weather_data[(weather_data['Temperature'] <= 60) & (weather_data['Humidity'] <= 100) & (weather_data['Precipitation (%)'] <= 100)]
print("删后的数据shape:", weather_data_new.shape)
#删除异常值数据
weather_data.drop(weather_data[weather_data['Temperature']>60].index,inplace=True)
weather_data.drop(weather_data[weather_data['Humidity']>100].index,inplace=True)
weather_data.drop(weather_data[weather_data['Precipitation (%)']>100].index,inplace = True)
print(weather_data.shape)
5、数据分析
(1)查看数据基本信息
print(weather_data.describe(include='all'))
(2)对数据进行可视化
#对数据进行可视化
plt.figure(figsize=(20,15)) #设置画布的大小
plt.subplot(3,4,1)
sns.histplot(weather_data['Temperature'],kde=True,bins=20) # kde:核密度估计图
plt.title('Temperature')
plt.xlabel('Temperature')
plt.ylabel('Frequency')
plt.subplot(3,4,2)
sns.boxplot(y=weather_data['Humidity'])
plt.title('Humidity')
plt.xlabel('Humidity')
plt.ylabel('Humidity percentage')
plt.subplot(3,4,3)
sns.histplot(weather_data['Wind Speed'],kde=True,bins=20)
plt.title('Wind Speed')
plt.xlabel('Wind Speed')
plt.ylabel('Frequency')
plt.subplot(3,4,4)
sns.boxplot(y= weather_data['Precipitation (%)'])
plt.title('Precipitation')
plt.ylabel('Precipition Percentage')
plt.subplot(3,4,5)
sns.countplot(x = 'Cloud Cover',data = weather_data)
plt.title('Cloud Cover')
plt.xlabel('Cloud Cover')
plt.ylabel('Frequency')
plt.subplot(3,4,6)
sns.histplot(weather_data['Atmospheric Pressure'], kde=True,bins=10)
plt.title('Atmospheric Pressure')
plt.xlabel('Atmospheric Pressure')
plt.ylabel('Frequency')
plt.subplot(3,4,7)
sns.histplot(weather_data['UV Index'], kde=True,bins=14)
plt.title('UV Index')
plt.xlabel('UV Index')
plt.ylabel('Frequency')
plt.subplot(3,4,8)
Season_counts = weather_data['Season'].value_counts()
plt.pie(Season_counts, labels=Season_counts.index, autopct='%1.1f%%', startangle=140)
plt.title('Season')
plt.subplot(3,4,9)
sns.histplot(weather_data['Visibility (km)'], kde=True,bins=10)
plt.title('Visibility')
plt.xlabel('Visibility')
plt.ylabel('Frequency')
plt.subplot(3,4,10)
sns.countplot(x='Location', data=weather_data)
plt.title('Location')
plt.xlabel('Location')
plt.ylabel('Frequency')
plt.subplot(3,4,(11,12))
sns.countplot(x='Weather Type', data=weather_data)
plt.title('Weather Type')
plt.xlabel('Weather Type')
plt.ylabel('Frequency')
plt.tight_layout()
plt.show()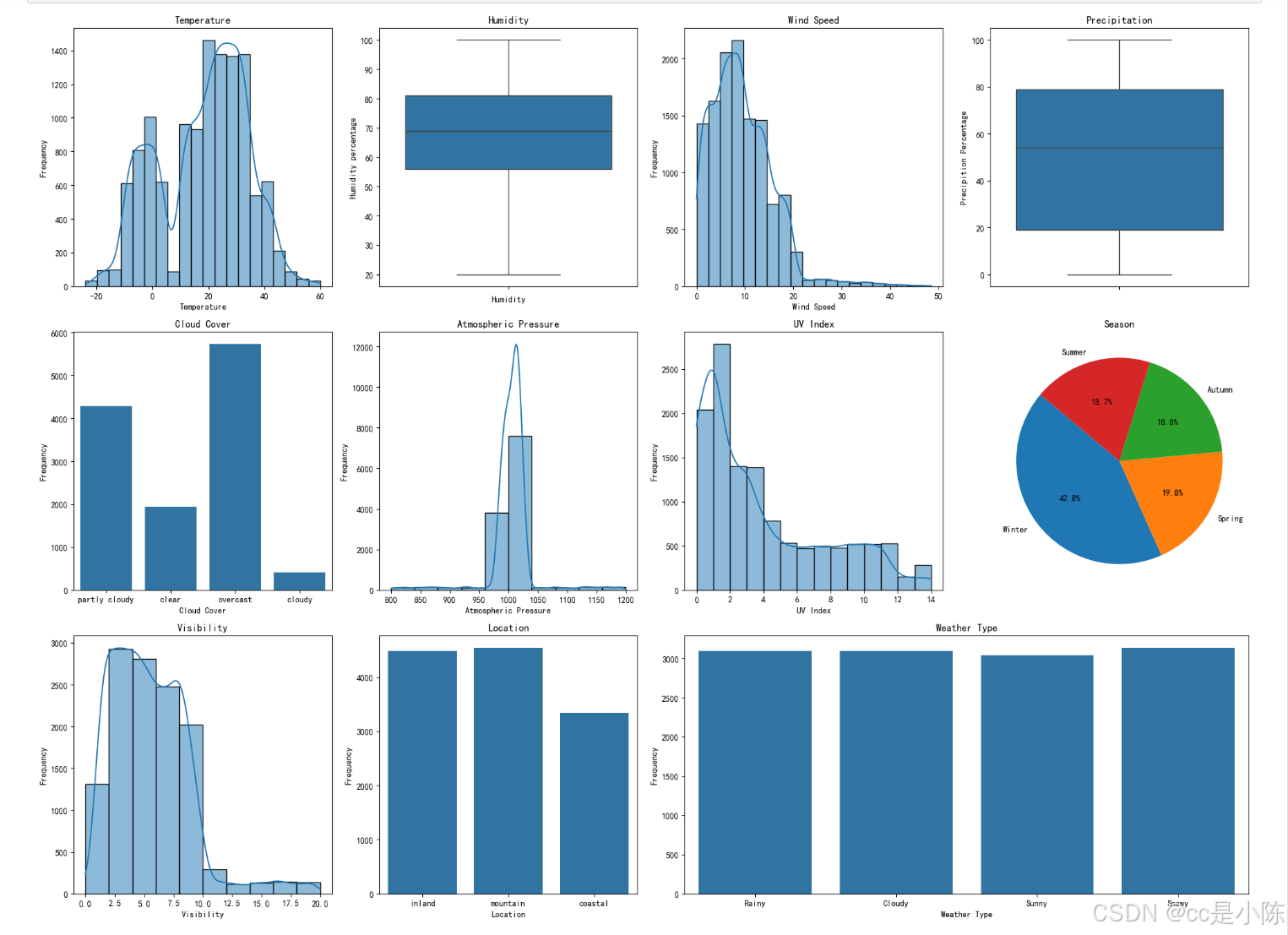
● 温度:温度数据集中在较合理的范围内(主要在0°C到40°C),极端高温(>60°C)的数据已被清理。整体分布稍微左偏,说明较低温度的情况较多。
● 湿度:湿度分布在合理范围内(20%到100%),中位数和平均值接近,说明数据分布相对对称。
● 风速:数据集中在较低的风速范围内(0-20 km/h),极端高风速事件少见,数据左偏,低风速情况更为常见。
● 降水量:降水量分布较均匀,中位数为54%,反映了各种天气条件下的降水概率。
● 大气压力:大气压力主要集中在标准范围(990-1020 hPa),数据分布正常,没有明显的异常值。
● 紫外线指数:紫外线指数大多较低,极端高指数的情况罕见,表明大部分时间的紫外线风险较低。
● 能见度:能见度数据大多集中在5 km左右,反映了多数情况下的中等能见度条件。
● 云量:多云(overcast)在数据集中出现频率较高。
● 季节分布:冬季数据最多,可能是数据采集季节或地区气候特征的反映。
● 地点分布:主要来自山区和内陆地区,这可能影响天气类型和其他气象特征的分布。
● 天气类型:分布比较均匀,没有单一类别占据绝对优势。
6、随机森林模型
(1)分类特征LabelEncoder
#对分类字段进行LabelEncoder编码
new_data = weather_data.copy()
label_encoder = {} # 创建字典用于表村标签编码的映射关系
categorical_columns = ['Cloud Cover','Season','Location','Weather Type']
for feature in categorical_columns: # 遍历分类特征
le = LabelEncoder() # 创建LabelEncoder队形
new_data[feature] = le.fit_transform(new_data[feature]) # 对数值进行编码
label_encoder[feature] = le #将LabelEncoder对象保存到字典中
for feature in categorical_columns:
print(f"'{feature}'的标签编码结果:")
for index,class_name in enumerate(label_encoder[feature].classes_): # 遍历类别
print(f"{index}:{class_name}")

(2)将数据拆分为训练集和测试集
#(1)将数据拆分为训练集和测试集
x = new_data.drop(['Weather Type'],axis =1)
y = new_data['Weather Type']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=42)(3)创建并训练模型
#(2)创建并训练模型
model = RandomForestClassifier(random_state=42)
model.fit(x_train,y_train)(4)预测模型
#(3)预测模型
y_pred = model.predict(x_test)(5)评估模型
#(4)评估模型
accuracy = accuracy_score(y_test,y_pred)
precision = precision_score(y_test,y_pred,average='weighted')
'''average参数是计算过程中可以采用的精度计算方法,
(1)weighted:对各类别进行加权平均,权重为各类别样本数
(2)micro:所有类别的平均值,权重为总样本数
(3)macro:各类别的平均值,权重为各类别样本数量的比例
(4)sample:各样本的平均值,权重为1
'''
recall = recall_score(y_test,y_pred,average='weighted')
f1 = f1_score(y_test,y_pred,average = 'weighted')
print("准确率:",accuracy)
print("精确率:",precision)
print("召回率:",recall)
print("F1_score:",f1)
(6)特征重要性分析
#(5)特征重要性分析
feature_importances = model.feature_importances_ # 获取特征重要性
feature_rf = pd.DataFrame({'feature':x.columns,'importance':feature_importances}) #将特征重要性转化为DataFrame格式
feature_rf.sort_values(by='importance',ascending=False,inplace=True)
plt.figure(figsize = (10,8))
sns.barplot(x='importance',y = 'feature',data=feature_rf)
plt.title('Feature Importance')
plt.xlabel('importance')
plt.ylabel('feature')
plt.show()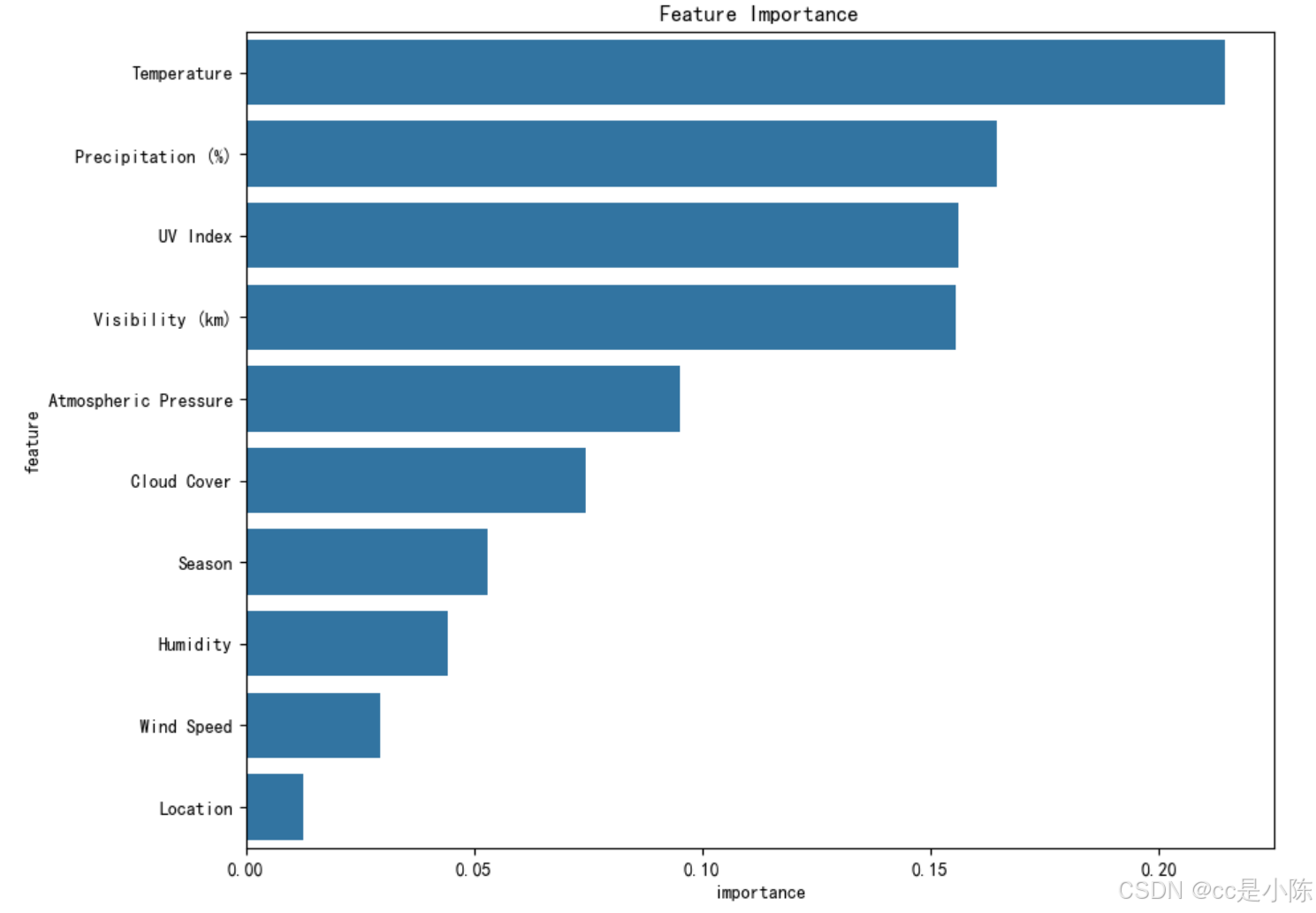
从第5步和第6步可以看出,随机森林模型的预测准确率很高,并且通过特征度分析,发现影响模型的主要因素有:温度、湿度、紫外线指数、能见度、大气压力。
四、总结
1、feature_importances_
在随机森林(Random Forest)算法中,feature_importances_ 是一个非常重要的属性,它用于评估每个特征在模型构建过程中的重要性。这个属性是通过计算每个特征在森林中所有决策树中的平均贡献度来得到的。具体来说,它衡量了每个特征在随机森林做出预测时,平均减少了多少模型的不纯度(如基尼不纯度或信息增益)。
2、随机森林在分类和回归问题下的工作原理
(1)分类问题
在分类问题中,随机森林是一个由多棵树组成的集成模型,每颗决策树都是一个二叉分类树,用于将输入数据划分为不同的类别。
工作原理:
- Bootstrap抽样:从训练数据集中有放回地随机选择样本,构建多个不同的训练数据集;
- 随机选择特征:在每个决策树的节点上,随机选择一部分特征来进行分裂,确保每棵树的特征选择具有随机性;
- 构建多棵决策树:根据以上两个步骤,构建多棵决策树,每棵树独立地学习数据的不同方面,但共同参与最终的分类决策;
- 综合预测结果:对于分类问题,随机森林通过多数投票的方式来确定最终的分类结果。即每棵树投票选择类别,最终选择得票最多的类别作为预测结果;
(2)回归问题
在回归问题中,随机森林同样是一个由多棵决策树组成的集成模型,但目标是预测连续数值输出而不是分类标签。
工作原理:
- Bootstrap抽样:从训练数据集中有放回地随机选择样本,构建多个不同的训练数据集;
- 随机选择特征:在每个决策树的节点上,随机选择一部分特征来进行分裂,确保每棵树的特征选择具有随机性;
- 构建多棵决策树:根据以上两个步骤,构建多棵决策树,每棵树独立地学习数据的不同方面,但共同参与最终的回归预测;
- 综合预测结果:对于回归问题,随机森林通常取多棵决策树的预测结果的平均值作为最终的回归预测值。这是因为平均值对连续数值输出更合适,它反映了模型对不同情况的平滑估计;
3、随机森林过拟合问题
随机森林通过一系列随机机制来处理过拟合问题,这使得它在许多情况下对抗过拟合表现得十分出色。
- Bootstrap抽样(随机选择样本):从训练数据集中有放回地随机选择样本,这意味着每颗决策树得训练数据都是不同的,且可能包含重复的样本。较少了模型对训练数据的敏感性,从而降低了过拟合的风险;
- 随机选择特征:在每棵决策树的节点上,随机森林只考虑样本特征的子集来进行分裂。这个子集大小是可以调节的。这种随机选择特征的方法减少了模型对某些特征的过度依赖,提高了模型的泛化能力;
- 多棵决策树的组合:随机森林不是单一的决策树,而是由多棵决策树组成。通过将多棵树的预测结果进行综合,如多数投票或平均值,随机森林可以减少单个决策树的错误和过拟合风险;
- 树的生长限制:随机森林通常限制每棵树的生长,可以通过设置最大深度、叶子节点的最小样本数或分裂节点所需的最小样本等参数来控制。这种方式防止单棵树过于复杂,进而降低了模型过拟合的可能性;
👏觉得文章对自己有用的宝子可以收藏文章并给小编点个赞!
👏想了解更多统计学、数据分析、数据开发、机器学习算法、深度学习等有关知识的宝子们,可以关注小编,希望以后我们一起成长!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)