推荐系统之隐语义模型(LFM)及Python实现
核心思想隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。比如,在推荐系统中它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。对于..
核心思想
隐语义模型LFM和LSI,LDA,Topic Model其实都属于隐含语义分析技术,是一类概念,他们在本质上是相通的,都是找出潜在的主题或分类。这些技术一开始都是在文本挖掘领域中提出来的,近些年它们也被不断应用到其他领域中,并得到了不错的应用效果。比如,在推荐系统中它能够基于用户的行为对item进行自动聚类,也就是把item划分到不同类别/主题,这些主题/类别可以理解为用户的兴趣。
对于一个用户来说,他们可能有不同的兴趣。就以作者举的豆瓣书单的例子来说,用户A会关注数学,历史,计算机方面的书,用户B喜欢机器学习,编程语言,离散数学方面的书, 用户C喜欢大师Knuth, Jiawei Han等人的著作。那我们在推荐的时候,肯定是向用户推荐他感兴趣的类别下的图书。那么前提是我们要对所有item(图书)进行分类。那如何分呢?大家注意到没有,分类标准这个东西是因人而异的,每个用户的想法都不一样。拿B用户来说,他喜欢的三个类别其实都可以算作是计算机方面的书籍,也就是说B的分类粒度要比A小;拿离散数学来讲,他既可以算作数学,也可当做计算机方面的类别,也就是说有些item不能简单的将其划归到确定的单一类别;拿C用户来说,他倾向的是书的作者,只看某几个特定作者的书,那么跟A,B相比它的分类角度就完全不同了。
显然我们不能靠由单个人(编辑)或team的主观想法建立起来的分类标准对整个平台用户喜好进行标准化。
实现这种方法,需要解决以下的问题:
(1)给物品分类
(2)确定用户兴趣属于哪些类及感兴趣程度
(3)对于用户感兴趣的类,如何推荐物品给用户
对于上述需要解决的问题,我们的隐语义模型就派上用场了。隐语义模型,可以基于用户的行为自动进行聚类,并且这个类的数量,即粒度完全由可控。
对于某个物品是否属与一个类,完全由用户的行为确定,我们假设两个物品同时被许多用户喜欢,那么这两个物品就有很大的几率属于同一个类。而某个物品在类所占的权重,也完全可以由计算得出。
原理
注:原理部分借鉴博客,博主画的图非常漂亮、形象,很容易理解。
下面我们就来看看LFM是如何解决上面的问题的?对于一个给定的用户行为数据集(数据集包含的是所有的user, 所有的item,以及每个user有过行为的item列表),使用LFM对其建模后,我们可以得到如下图所示的模型:(假设数据集中有3个user, 4个item, LFM建模的分类数为4)
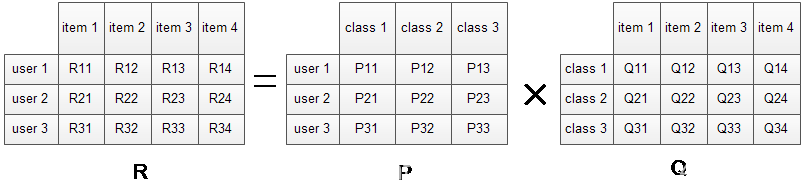
R矩阵是user-item矩阵,矩阵值Rij表示的是user i 对item j的兴趣度,这正是我们要求的值。对于一个user来说,当计算出他对所有item的兴趣度后,就可以进行排序并作出推荐。LFM算法从数据集中抽取出若干主题,作为user和item之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是user i对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是item j在class i中的权重,权重越高越能作为该类的代表。所以LFM根据如下公式来计算用户U对物品I的兴趣度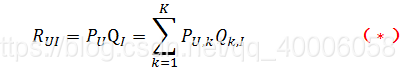
LFM有以下优势:
- 我们不需要关心分类的角度,结果都是基于用户行为统计自动聚类的,全凭数据自己说了算。
- 不需要关心分类粒度的问题,通过设置LFM的最终分类数K就可控制粒度,分类数K越大,粒度约细。
- 对于一个item,并不是明确的划分到某一类,而是计算其属于每一类的概率,是一种标准的软分类。
- 对于一个user,我们可以得到他对于每一类的兴趣度,而不是只关心可见列表中的那几个类。
- 对于每一个class,我们可以得到类中每个item的权重,越能代表这个类的item,权重越高。
那么,接下去的问题就是如何计算矩阵P和矩阵Q中参数值。一般做法就是最优化损失函数来求参数。在定义损失函数之前,我们需要准备一下数据集并对兴趣度的取值做一说明。
数据集应该包含所有的user和他们有过行为的(也就是喜欢)的item。所有的这些item构成了一个item全集。对于每个user来说,我们把他有过行为的item称为正样本,规定兴趣度RUI=1,此外我们还需要从item全集中随机抽样,选取与正样本数量相当的样本作为负样本,规定兴趣度为RUI=0。因此,兴趣的取值范围为[0,1]。
注:对于隐性反馈数据集,由于只有正样本,没有负样本,因此在应用LFM进行TopN推荐的时候第一个关键问题就是如何生成负样本。采样原则有以下两点:
- 对于每个用户,要保证正负样本均衡;
- 对于每个用户进行采样时,要选取那些热门但用户没有行为的物品。
采样之后原有的数据集得到扩充,得到一个新的user-item集K={(U,I)},其中如果(U,I)是正样本,则RUI=1,否则RUI=0。
通过优化以下损失函数来找到最合适的P,Q,损失函数如下: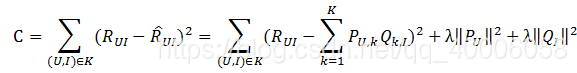
其中, λ||PU||2+λ||QI||2 为正则化项,防止过拟合,lambda通过试验获取。
通过随机梯度下降法优化损失函数C: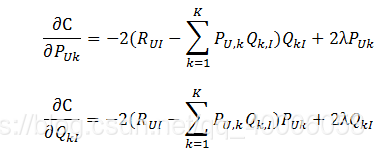
梯度下降优化,直至参数收敛: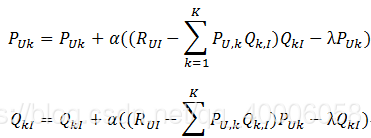
其中,α是学习速率,α越大,迭代下降的越快。α和λ一样,也需要根据实际的应用场景反复实验得到。《推荐系统实战》中,作者在MovieLens数据集上进行实验,他取分类数F=100,α=0.02,λ=0.01。
综上所述,执行LFM需要:
- 根据数据集初始化P和Q矩阵(采用随机初始化的方式,将p和q取值在[0,1]之间);
- 确定4个参数:分类数F,迭代次数N,学习速率α,正则化参数λ。
伪代码如下:
def LFM(user_items, F, N, alpha, lambda):
#初始化P,Q矩阵
[P, Q] = InitModel(user_items, F)
#开始迭代
For step in range(0, N):
#从数据集中依次取出user以及该user喜欢的iterms集
for user, items in user_item.iterms():
#随机抽样,为user抽取与items数量相当的负样本,并将正负样本合并,用于优化计算
samples = RandSelectNegativeSamples(items)
#依次获取item和user对该item的兴趣度
for item, rui in samples.items():
#根据当前参数计算误差
eui = eui - Predict(user, item)
#优化参数
for f in range(0, F):
P[user][f] += alpha * (eui * Q[f][item] - lambda * P[user][f])
Q[f][item] += alpha * (eui * P[user][f] - lambda * Q[f][item])
#每次迭代完后,都要降低学习速率。一开始的时候由于离最优值相差甚远,因此快速下降;
#当优化到一定程度后,就需要放慢学习速率,慢慢的接近最优值。
alpha *= 0.9
Python实现LFM模型
# https://blog.csdn.net/fjssharpsword/article/details/78262539
'''
实现隐语义模型,对隐式数据进行推荐
1.对正样本生成负样本
-负样本数量相当于正样本
-物品越热门,越有可能成为负样本
2.使用随机梯度下降法,更新参数
'''
import numpy as np
import pandas as pd
from math import exp
import time
import math
from sklearn import cross_validation
import random
import operator
class LFM:
'''
初始化隐语义模型
参数:*data 训练数据,要求为pandas的dataframe
*F 隐特征的个数 *N 迭代次数 *alpha 随机梯度下降的学习速率
*lamda 正则化参数 *ratio 负样本/正样本比例 *topk 推荐的前k个物品
'''
def __init__(self,data,ratio,F=5,N=2,alpha=0.02,lamda=0.01,topk=10):
self.data=data # 样本集
self.ratio =ratio # 正负样例比率,对性能最大影响
self.F = F # 隐类数量,对性能有影响
self.N = N # 迭代次数,收敛的最佳迭代次数未知
self.alpha =alpha # 梯度下降步长
self.lamda = lamda # 正则化参数
self.topk =topk # 推荐top k项
'''
初始化物品池,物品池中物品出现的次数与其流行度成正比
{item1:次数,item2:次数,...}
'''
def InitItemPool(self):
itemPool=dict()
groups = self.data.groupby([1])
for item,group in groups:
itemPool.setdefault(item,0)
itemPool[item] =group.shape[0]
itemPool=dict(sorted(itemPool.items(), key = lambda x:x[1], reverse = True))
return itemPool
'''
获取每个用户对应的商品(用户购买过的商品)列表,如
{用户1:[商品A,商品B,商品C],
用户2:[商品D,商品E,商品F]...}
'''
def user_item(self):
ui = dict()
groups = self.data.groupby([0])
for item,group in groups:
ui[item]=set(group.ix[:,1])
return ui
'''
初始化隐特征对应的参数
numpy的array存储参数,使用dict存储每个用户(物品)对应的列
'''
def initParam(self):
users=set(self.data.ix[:,0])
items=set(self.data.ix[:,1])
arrayp = np.random.rand(len(users), self.F) # 构造p矩阵,[0,1]内随机值
arrayq = np.random.rand(self.F, len(items)) # 构造q矩阵,[0,1]内随机值
P = pd.DataFrame(arrayp, columns=range(0, self.F), index=users)
Q = pd.DataFrame(arrayq, columns=items, index=range(0,self.F))
return P,Q
'''
self.Pdict=dict()
self.Qdict=dict()
for user in users:
self.Pdict[user]=len(self.Pdict)
for item in items:
self.Qdict[item]=len(self.Qdict)
self.P=np.random.rand(self.F,len(users))
self.Q=np.random.rand(self.F,len(items))
'''
'''
生成负样本
'''
def RandSelectNegativeSamples(self,items):
ret=dict()
for item in items:
ret[item]=1 # 所有正样本评分为1
negtiveNum = int(round(len(items)*self.ratio)) # 负样本个数,四舍五入
N = 0
#while N<negtiveNum:
#item = self.itemPool[random.randint(0, len(self.itemPool) - 1)]
for item,count in self.itemPool.items():
if N > negtiveNum:
break
if item in items: # 如果在用户已经喜欢的物品列表中,继续选
continue
N+=1
ret[item]=0 # 负样本评分为0
return ret
def sigmod(self,x):
y = 1.0 / (1 + exp(-x)) # 单位阶跃函数,将兴趣度限定在[0,1]范围内
return y
def lfmPredict(self,p, q, userID, itemID): # 利用参数p,q预测目标用户对目标物品的兴趣度
p = np.mat(p.ix[userID].values)
q = np.mat(q[itemID].values).T
r = (p * q).sum()
r = self.sigmod(r)
return r
'''
使用随机梯度下降法,更新参数
'''
def stochasticGradientDecent(self,p,q):
alpha=self.alpha
for i in range(self.N):
for user,items in self.ui.items():
ret=self.RandSelectNegativeSamples(items)
for item,rui in ret.items():
eui = rui - self.lfmPredict(p,q, user, item)
for f in range(0, self.F):
#df[列][行]定位
tmp= alpha * (eui * q[item][f] - self.lamda * p[f][user])
q[item][f] += alpha * (eui * p[f][user] - self.lamda * q[item][f])
p[f][user] +=tmp
alpha*=0.9
return p,q
def Train(self):
self.itemPool=self.InitItemPool() # 生成物品的热门度排行
self.ui = self.user_item() # 生成用户-物品
p,q=self.initParam() # 生成p,q矩阵
self.P,self.Q=self.stochasticGradientDecent(p,q) # 随机梯度下降训练
def Recommend(self,user):
items=self.ui[user]
predictList = [self.lfmPredict(self.P, self.Q, user, item) for item in items]
series = pd.Series(predictList, index=items)
series = series.sort_values(ascending=False)[:self.topk]
return series
'''
#items=self.ui[user]
p=self.P[:,self.Pdict[user]]
rank = dict()
for item,id in self.Qdict.items():
#if item in items:
# continue
q=self.Q[:,id];
rank[item]=sum(p*q)
#return sorted(rank.items(),lambda x,y:operator.gt(x[0],y[0]),reverse=True)[0:self.topk-1];
return sorted(rank.items(),key=operator.itemgetter(1),reverse=True)[0:self.topk-1];
'''
def recallAndPrecision(self,test):#召回率和准确率
userID=set(test.ix[:,0])
hit = 0
recall = 0
precision = 0
for userid in userID:
#trueItem = test[test.ix[:,0] == userid]
#trueItem= trueItem.ix[:,1]
trueItem=self.ui[userid]
preitem=self.Recommend(userid)
for item in list(preitem.index):
if item in trueItem:
hit += 1
recall += len(trueItem)
precision += len(preitem)
return (hit / (recall * 1.0),hit / (precision * 1.0))
def coverage(self,test):#覆盖率
userID=set(test.ix[:,0])
recommend_items = set()
all_items = set()
for userid in userID:
#trueItem = test[test.ix[:,0] == userid]
#trueItem= trueItem.ix[:,1]
trueItem=self.ui[userid]
for item in trueItem:
all_items.add(item)
preitem=self.Recommend(userid)
for item in list(preitem.index):
recommend_items.add(item)
return len(recommend_items) / (len(all_items) * 1.0)
def popularity(self,test):#流行度
userID=set(test.ix[:,0])
ret = 0
n = 0
for userid in userID:
preitem=self.Recommend(userid)
for item in list(preitem.index):
ret += math.log(1+self.itemPool[item])
n += 1
return ret / (n * 1.0)
if __name__ == "__main__":
start = time.clock()
#导入数据
data=pd.read_csv('D:\\dev\\workspace\\PyRecSys\\demo\\ratings.csv',nrows=10000,header=None)
data=data.drop(0)
data=data.ix[:,0:1]
train,test=cross_validation.train_test_split(data,test_size=0.2)
train = pd.DataFrame(train)
test = pd.DataFrame(test)
print ("%3s%20s%20s%20s%20s" % ('ratio',"recall",'precision','coverage','popularity'))
for ratio in [1,2,3,5]:
lfm = LFM(data,ratio)
lfm.Train()
#rank=lfm.Recommend('1')
#print (rank)
recall,precision = lfm.recallAndPrecision(test)
coverage =lfm.coverage(test)
popularity =lfm.popularity(test)
print ("%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (ratio,recall * 100,precision * 100,coverage * 100,popularity))
end = time.clock()
print('finish all in %s' % str(end - start))
LFM变形
1、加入偏置项后的LFM
2、SVD++

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)