图片热区定位的方法_CCF2019-基于OCR的身份证识别(四)文字定位

文章只针对比赛方法说出自己的想法,并没有不是对其他团队的方法贬低的意思,希望引入更多思考和讨论,推动大家一起进步。
开篇:为什么叫“文字定位”,而不是文字检测。原因很简单,因为“印章”的存在导致CPTN、EAST效果不理想,无法精确获取文字区域,只能通过一些传统的方法来解决问题。
- CPTN的检测效果(示例)
CPTN和EAST都已经很牛了,在自然场景中有很好的表现,放在这里表现其实也不错。下图是Unet处理后的CPTN效果,印章的干扰已经最小化。如果深入了解会发现,还是存在一些明显的问题,例如姓名部分,识别框明显变长了,身份证号码等固定文字也被识别了,等等。
※ 困难比我说的要多一些,这里只是抛砖引玉。



那存在其他更简单的方法来解决问题吗? 当然存在,其实这类问题都是“定式内容识别”问题,假设我们有一个“锚点”,那么我们完全可以推算出其他文字的相对位置,“锚点相对法”针对这个问题比CPTN更可靠、更高效、更快捷。所以Top1~5我记得都选了类似的方法。
- “锚点”的选择
锚点选择是个其实挺难的,这是一个“决策”问题,不是技术问题。选择大概从3个方向考虑:①业务的有效性 ,②方法的鲁棒性,③ 算法的效率
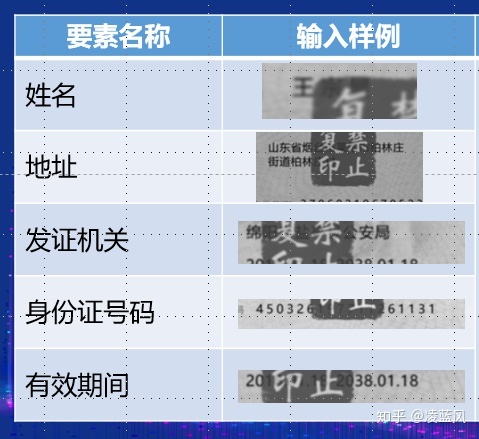
a. 特征定位法
特征定位其实就是,利用深度模型,针对图片中的一些 固定不变的“文字”或“图片”进行定位检测,方法有很多,没什么可讲的。比如我画的红圈位置,就是两个不错的点,选择这些特征时候要有几个要求:1.在图片中一定存在,2.这个区域干扰少,3.业务合理(没有特例)这些要求任何一个缺少,都可以认为决策有一定的“投机性”。


赛会为了区分“真实身份证”,所以在每幅图片左上角增加了:仅限DBCI比赛使用的文字。这个锚点符合两个要素:1.在图片中一定存在,2.这个区域干扰少。但是在真实业务中是不存在的。
我们回到赛题任务:探索对上述挑战中的任意一项设计解决方案,并验证其可行性
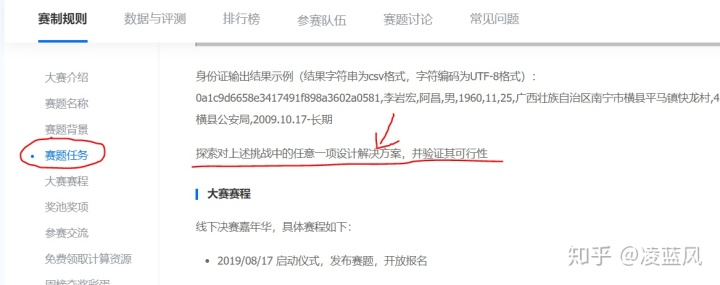
基于这个背景,“仅限DBCI比赛使用的文字”锚点的在业务合理性基本没有,比赛成绩提高的价值存在。
b. 边界定位法
说完了特征定位,我们来说说边界定位。边界定位是传统CV领域的方法,不需要模型。只需要将像素水平和垂直投影(把对应轴像素和)就可以了,可以容易获得“角点”。当然也有一些其他方法,欢迎大家讨论。

虽然可以获得四个角,但是选择哪个角还是有一些讲究的,毕竟相对位置的会存在一定误差,并且误差会累计,所以选择角的时候尽量靠近要找的相对区域。基于这个原则,选择左上角作为相对参照点,并对识别区域保持的余白(降低误差对结果的干扰)。这个点可以符合:三个要素:1.在图片中一定存在,2.干扰少,3.业务合理。除此之外还具备这些特性:鲁棒性、效率高、速度快。存在的不足:误差相比“仅限DBCI比赛使用的文字”定位略大,误差变大问题,是因为图片过于模糊,白纸颜色和身份证背景融合度比较高,这个不足可以在后面识别过程弥补。
※ 因为赛题没有畸变,所以不用担心图片的变形问题,真实场景需要考虑。
- 最终方案的选择
最终方案使用的边界定位法,为了克服一些精度问题,所以我们在切分图片时候,尽量保证宁愿多留余白,也不要切掉文字,因为切掉的文字基本无法弥补(比如:姓名)

总结:队友4人都已经步入工作岗位,参与竞赛不仅仅为了名次和奖金,更多是希望探索一下新方法、用这些比赛经验“反哺”自己的业务能力。也希望大家一起参与讨论,把这类问题弄明白,使算法在业务中可以"落地"。
分享知识不收费,也请“点赞”鼓励我,努力为大家呈现更多精彩内容:)
凌蓝风
2019年12月18日

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)