小白也能懂文本挖掘之词频统计和词云图绘制(附代码讲解)
词频统计和词云图绘制是文本分析中的常见任务,它们能够帮助我们快速理解文本中的关键信息和主题。词频统计是指对文本中出现的各个词汇进行计数,以了解每个词汇在文本中出现的频率。这是文本分析的基础步骤之一,有助于识别文本中的关键信息和主题。词云图是一种用来展现高频关键词的可视化表达。它通过文字、色彩、图形的搭配,产生有冲击力的视觉效果,并能够传达有价值的信息。
一、词频统计和词云图简介
词频统计和词云图绘制是文本分析中的常见任务,它们能够帮助我们快速理解文本中的关键信息和主题。
词频统计是指对文本中出现的各个词汇进行计数,以了解每个词汇在文本中出现的频率。这是文本分析的基础步骤之一,有助于识别文本中的关键信息和主题。
词云图是一种用来展现高频关键词的可视化表达。它通过文字、色彩、图形的搭配,产生有冲击力的视觉效果,并能够传达有价值的信息。
二、Py代码实操及讲解
1.读取文件
读取文件,使用pandas库的读取文件pd.read_excel函数

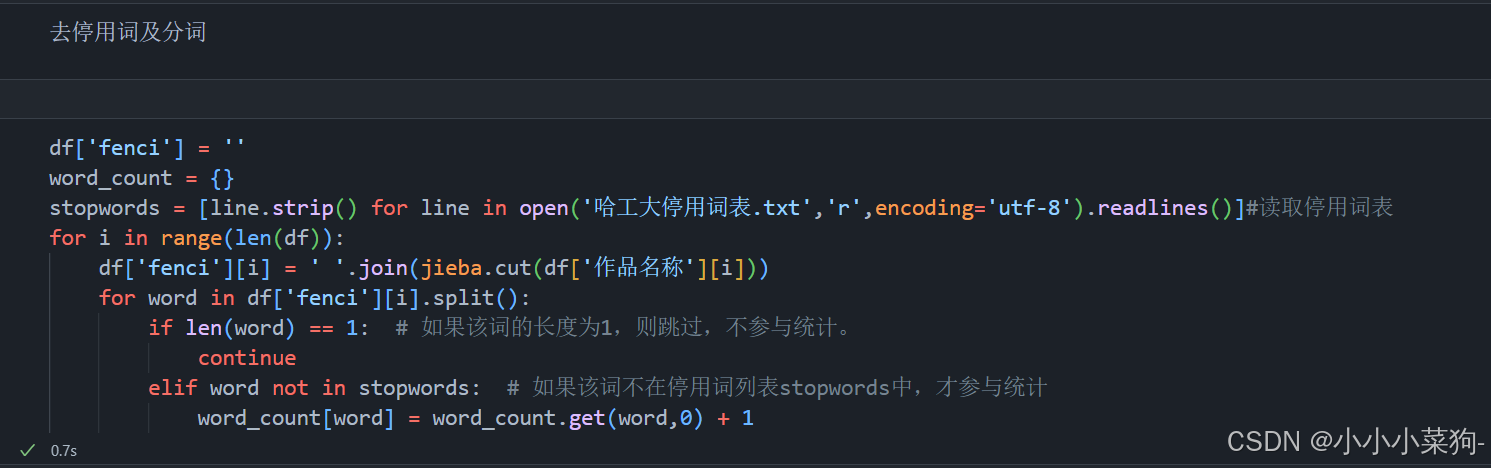
2.去停用词及分词
Stopwords即读取停用词表
后面的代码逻辑也比较简单,通过两层循环+两层判断,统计出每个词出现的次数
第一层循环,对所有的数据进行分词;
第二层循环,对分词后的数据进行循环判断,去除长度为1和在停用词表里的词,并进行统计
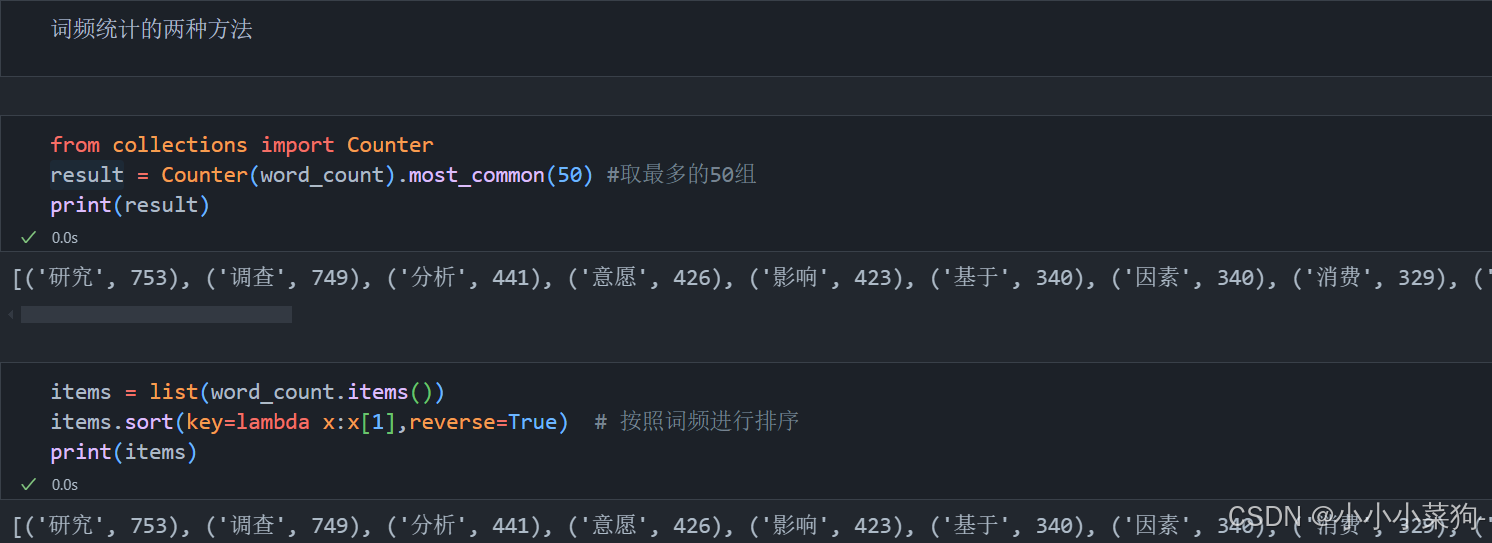
3.词频统计方法
(1)可以通过引用collections库中的Counter函数,对词频进行排序,并显示排序前50的词
(2)可以通过list函数进行排序,显示。二者的运行结果一样
4.绘制词云图
需要引入 wordcloud库中的WordCloud库进行词云图绘制
并通过matplotlib库中的pyplot库进行显示
也可以直接用WordCloud库中的wc.to_file()指令直接将词云图保存
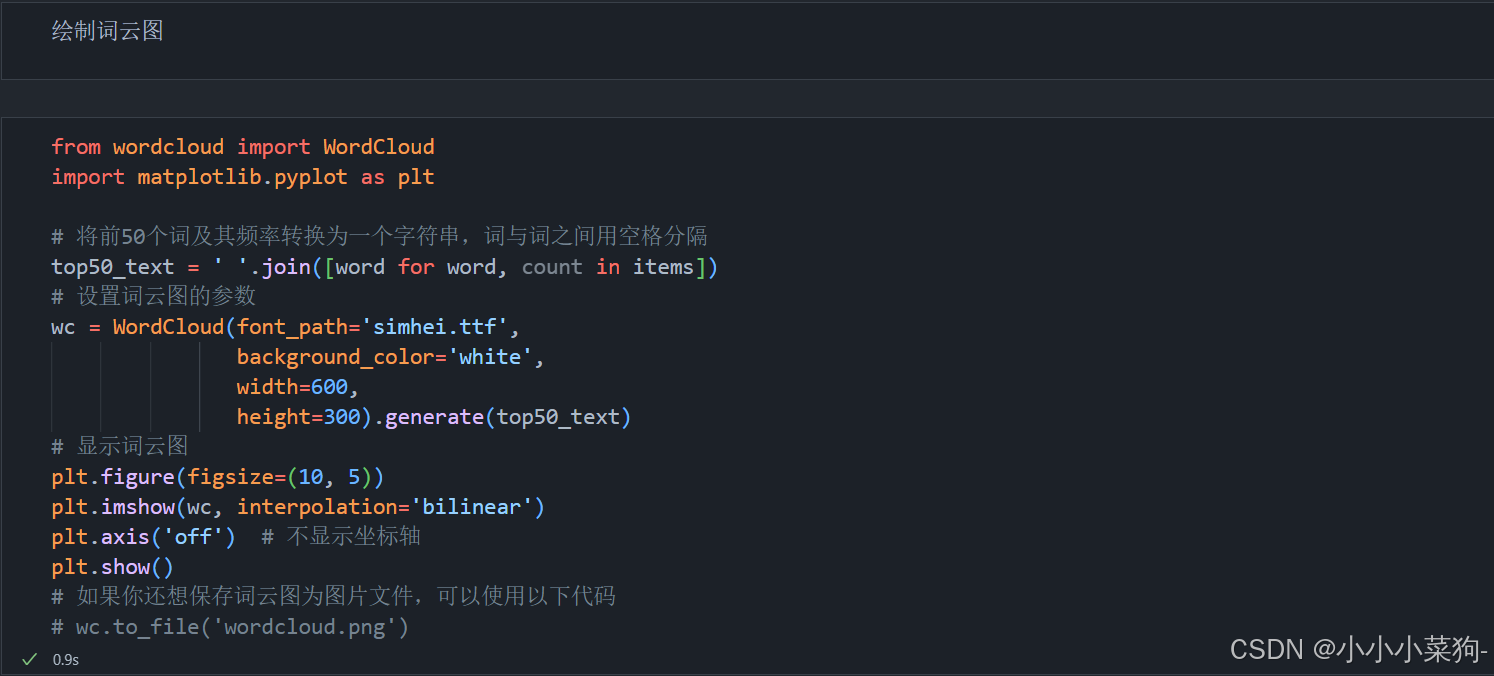
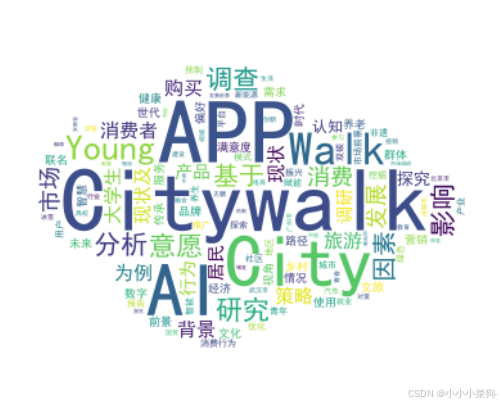
代码运行结果图

5.绘制特定形状的词云图
需要引入matplotlib库中的image函数,对图像进行读取处理
直接在WordCloud函数中,设置mask即可绘制出特定形状的词云图
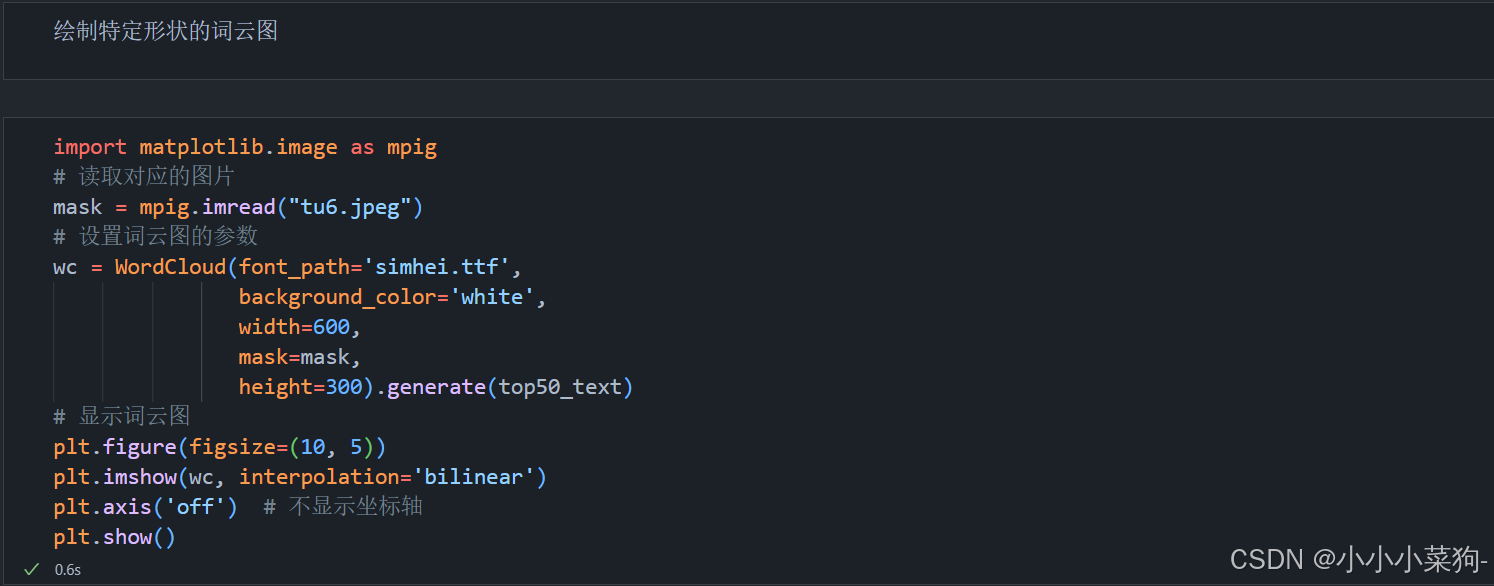
代码运行结果图

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)