机器学习——朴素贝叶斯
实验对西瓜数据集利用朴素贝叶斯分类器进行分类,实验预测结果与正确结果无误。叶贝斯分类器通过计算给定特征下每个类别的后验概率来进行分类,具有高效、易于实现等优点。不过我只测试了一个测试集,倘若测试集庞大,定会有误差出现,这是应该改进的地方。总的来说,由于西瓜数据集特征较少且属性之间相关性较弱,朴素贝叶斯分类器能够很好地处理这种情况,表现出了较好的分类性能。通过本次实验,验证了朴素贝叶斯分类器在西瓜数
目录
概念
朴素贝叶斯分类器是一种基于贝叶斯定理的机器学习算法,常用于文本分类和其他类型的分类问题。它被称为“朴素”,是因为它假设特征之间是相互独立的,这意味着给定分类的条件下,每个特征发生的概率都是独立的。尽管这个假设在现实中很少成立,但朴素贝叶斯仍然是一个强大且有效的分类器,特别是在文本分类等应用中表现出色。
原理
利用贝叶斯公式计算出后验概率作为分类的判断依据。
载入数据集
训练样本集:(采用西瓜书里的西瓜数据集)
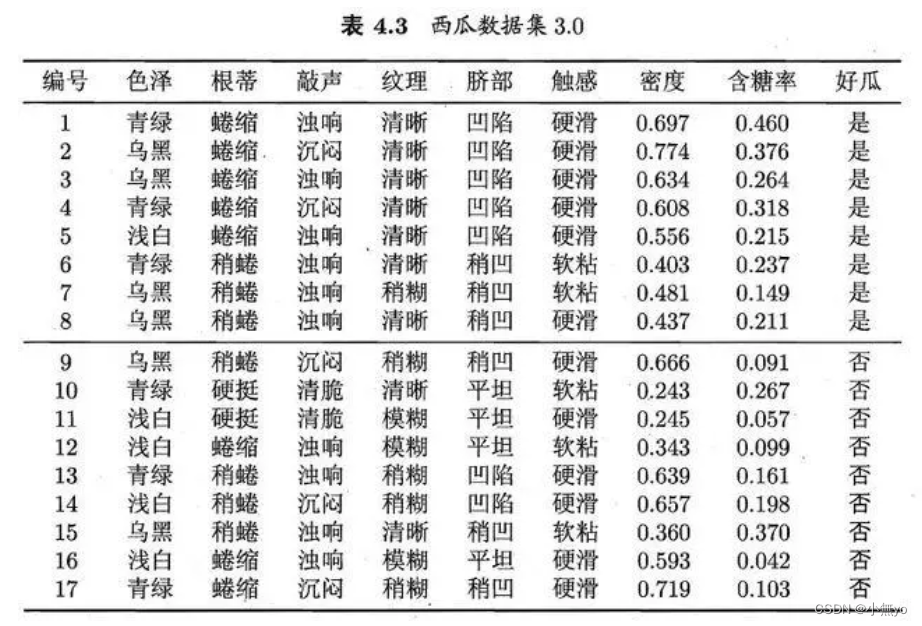
测试样本集选取编号17的特征为例:
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
| 1 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | ? |
代码创建西瓜数据集:
def create_DataSet():
#训练集
dataset = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
#测试集
testset = ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']
#特征
labels = ['色泽','根蒂','敲声','纹理','脐部','触感']
return dataset,testset,labels
数据集打印结果:

1.计算先验概率
先验概率:在没有任何其他信息的情况下,某个类别或事件发生的概率。在贝叶斯分类器中,先验概率通常通过统计训练数据集中各类别的出现频率来估计。
统计训练集中好瓜和坏瓜的个数,通过计算出现频率作为好瓜、坏瓜的先验概率。
#计算先验概率
def prior():
#载入数据集
dataset = create_DataSet()[0]
countG=0 #初始化好瓜数量
countB=0 #初始化坏瓜数量
countAll = len(dataset)
for i in dataset: #统计好瓜个数
if i[-1] == "好瓜": countG += 1
for i in dataset: #统计坏瓜个数
if i[-1] == "坏瓜": countB += 1
#计算先验概率P(c)
P_G = round(countG/countAll,3) #四舍五入为三位小数
P_B = round(countB/countAll,3)
return P_G,P_B结果展示:
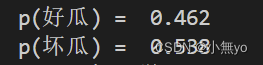
2.计算条件概率
条件概率:指在给定某个条件下,某一事件发生的概率。它表示了事件A在事件B已经发生的条件下发生的概率。
统计特征为x且为c类瓜的总数再除以c类瓜总数得到条件概率P(x,c)。
#计算条件概率 P(x|c)
def P(x,c):
#载入数据集
dataset,testset,labels = create_DataSet()
countG=0 #初始化好瓜数量
countB=0 #初始化坏瓜数量
for i in dataset: #统计好瓜个数
if i[-1] == "好瓜": countG += 1
for i in dataset: #统计坏瓜个数
if i[-1] == "坏瓜": countB += 1
#将数据集中满足类别和特征的项集合存储在列表lst中
lst = [item for item in dataset if (item[-1] == c) and (item[x] == testset[x])]
P = round(len(lst)/(countG if c=="好瓜" else countB),3)
return P测试集计算所有的条件概率:
P0_G = P(0,"好瓜") #P(青绿|好瓜)
P0_B = P(0,"坏瓜") #P(青绿|坏瓜)
P1_G = P(1,"好瓜") #P(蜷缩|好瓜)
P1_B = P(1,"坏瓜") #P(蜷缩|坏瓜)
P2_G = P(2,"好瓜") #P(沉闷|好瓜)
P2_B = P(2,"坏瓜") #P(沉闷|坏瓜)
P3_G = P(3,"好瓜") #P(稍糊|好瓜)
P3_B = P(3,"坏瓜") #P(稍糊|坏瓜)
P4_G = P(4,"好瓜") #P(稍凹|好瓜)
P4_B = P(4,"坏瓜") #P(稍凹|坏瓜)
P5_G = P(5,"好瓜") #P(硬滑|好瓜)
P5_B = P(5,"坏瓜") #P(硬滑|坏瓜)
print("P(青绿|好瓜) = ",P0_G, "P(青绿|坏瓜) = ",P0_B)
print("P(蜷缩|好瓜) = ",P1_G, "P(蜷缩|坏瓜) = ",P1_B)
print("P(沉闷|好瓜) = ",P2_G, "P(沉闷|坏瓜) = ",P2_B)
print("P(稍糊|好瓜) = ",P3_G, "P(稍糊|坏瓜) = ",P3_B)
print("P(稍凹|好瓜) = ",P4_G, "P(稍凹|坏瓜) = ",P4_B)
print("P(硬滑|好瓜) = ",P5_G, "P(硬滑|坏瓜) = ",P5_B)运行结果:

3.计算后验概率
后验概率:指在考虑了新的信息或证据后,重新计算某一事件发生的概率。它是基于先前的先验概率和新的证据,通过贝叶斯定理进行更新后得到的概率。
贝叶斯定理:
在该例中,后验概率为
P(好瓜|青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑) = P(青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑|好瓜)*P(好瓜)/P(青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑)
P(坏瓜|青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑) = P(青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑|坏瓜)*P(坏瓜)/P(青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑)
而计算P(青绿, 蜷缩, 沉闷, 稍糊, 稍凹, 硬滑|好瓜)只需要将每个条件概率P(xi|好瓜)相乘即得,坏瓜同理。
因为我们只需要比较二者的后验概率大小,而二者分母相同,因此我们直接将分子作为概率判断,所以P(好瓜|xi)简化为每个条件概率P(xi|好瓜)和先验概率P(好瓜)相乘。
#计算后验概率
#计算好瓜的后验概率P(好瓜|xi)
is_G = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G
#计算坏瓜的后验概率P(坏瓜|xi)
is_B = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B
print("P(好瓜|xi) = ",is_G)
print("P(坏瓜|xi) = ",is_B)
print("测试集特征为['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']的预测结果为:")
if is_G > is_B:
print("好瓜")
else:
print("坏瓜")运行结果:
P(好瓜|xi) = 0.0009702301025390625
P(坏瓜|xi) = 0.0019263775577686361
测试集特征为['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']的预测结果为:
坏瓜
最终结果是正确的。
完整代码:
def create_DataSet():
#训练集
dataset = [
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
#测试集
testset = ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']
#特征
labels = ['色泽','根蒂','敲声','纹理','脐部','触感']
return dataset,testset,labels
#数据集
dataset,testset,labels = create_DataSet()
'''
print("训练集:",dataset)
print("测试集:",testset)
print("特征:",labels)
'''
#计算先验概率
def prior():
#载入数据集
dataset = create_DataSet()[0]
countG=0 #初始化好瓜数量
countB=0 #初始化坏瓜数量
countAll = len(dataset)
for i in dataset: #统计好瓜个数
if i[-1] == "好瓜": countG += 1
for i in dataset: #统计坏瓜个数
if i[-1] == "坏瓜": countB += 1
#计算先验概率P(c)
P_G = round(countG/countAll,3) #四舍五入为三位小数
P_B = round(countB/countAll,3)
return P_G,P_B
P_G,P_B = prior()
'''
print("p(好瓜) = ",P_G)
print("p(坏瓜) = ",P_B)
'''
#计算条件概率 P(x|c)
def P(x,c):
#载入数据集
dataset,testset,labels = create_DataSet()
countG=0 #初始化好瓜数量
countB=0 #初始化坏瓜数量
for i in dataset: #统计好瓜个数
if i[-1] == "好瓜": countG += 1
for i in dataset: #统计坏瓜个数
if i[-1] == "坏瓜": countB += 1
#将数据集中满足类别和特征的项集合存储在列表lst中
lst = [item for item in dataset if (item[-1] == c) and (item[x] == testset[x])]
P = round(len(lst)/(countG if c=="好瓜" else countB),3)
return P
P0_G = P(0,"好瓜") #P(青绿|好瓜)
P0_B = P(0,"坏瓜") #P(青绿|坏瓜)
P1_G = P(1,"好瓜") #P(蜷缩|好瓜)
P1_B = P(1,"坏瓜") #P(蜷缩|坏瓜)
P2_G = P(2,"好瓜") #P(沉闷|好瓜)
P2_B = P(2,"坏瓜") #P(沉闷|坏瓜)
P3_G = P(3,"好瓜") #P(稍糊|好瓜)
P3_B = P(3,"坏瓜") #P(稍糊|坏瓜)
P4_G = P(4,"好瓜") #P(稍凹|好瓜)
P4_B = P(4,"坏瓜") #P(稍凹|坏瓜)
P5_G = P(5,"好瓜") #P(硬滑|好瓜)
P5_B = P(5,"坏瓜") #P(硬滑|坏瓜)
print("P(青绿|好瓜) = ",P0_G, "P(青绿|坏瓜) = ",P0_B)
print("P(蜷缩|好瓜) = ",P1_G, "P(蜷缩|坏瓜) = ",P1_B)
print("P(沉闷|好瓜) = ",P2_G, "P(沉闷|坏瓜) = ",P2_B)
print("P(稍糊|好瓜) = ",P3_G, "P(稍糊|坏瓜) = ",P3_B)
print("P(稍凹|好瓜) = ",P4_G, "P(稍凹|坏瓜) = ",P4_B)
print("P(硬滑|好瓜) = ",P5_G, "P(硬滑|坏瓜) = ",P5_B)
#计算后验概率
#计算好瓜的后验概率P(好瓜|xi)
is_G = P_G * P0_G * P1_G * P2_G * P3_G * P4_G * P5_G
#计算坏瓜的后验概率P(坏瓜|xi)
is_B = P_B * P0_B * P1_B * P2_B * P3_B * P4_B * P5_B
print("P(好瓜|xi) = ",is_G)
print("P(坏瓜|xi) = ",is_B)
print("测试集特征为['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']的预测结果为:")
if is_G > is_B:
print("好瓜")
else:
print("坏瓜")报错及解决
Traceback (most recent call last):
File "e:\机器学习\code\Bayesian_Classification.py", line 89, in <module>
P1_G = P(1,"好瓜") #P(蜷缩|好瓜)
File "e:\机器学习\code\Bayesian_Classification.py", line 82, in P
lst = [item for item in dataset if (item[-1] == c) and (item[x] == testset[x])]
File "e:\机器学习\code\Bayesian_Classification.py", line 82, in <listcomp>
lst = [item for item in dataset if (item[-1] == c) and (item[x] == testset[x])]
IndexError: list index out of range
报错原因:在你的代码中出现了列表索引超出范围的情况。
解决:
#原测试集
testset = [
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']
]
#修改后的测试集
testset = ['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑']
我错误地将列表写成嵌套列表的形式以至于 testset[x] 的索引与 item[x] 的索引不一致,导致了这个问题。
实验结果分析及总结
实验对西瓜数据集利用朴素贝叶斯分类器进行分类,实验预测结果与正确结果无误。叶贝斯分类器通过计算给定特征下每个类别的后验概率来进行分类,具有高效、易于实现等优点。不过我只测试了一个测试集,倘若测试集庞大,定会有误差出现,这是应该改进的地方。总的来说,由于西瓜数据集特征较少且属性之间相关性较弱,朴素贝叶斯分类器能够很好地处理这种情况,表现出了较好的分类性能。通过本次实验,验证了朴素贝叶斯分类器在西瓜数据集上的有效性和可行性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)