VIT模型解读(附源码+论文)
(建议看我的,因为我都整理好了,而且代码注释的很详细。想看源码的话可以去官网)传统的图像处理都是用的卷积,直到多头注意力机制横空出世,NLP取得飞跃发展。有机智的学者发现,将其应用到图片处理…Vision Transformer (ViT) 是一种基于 Transformer 的图像分类模型,其核心思想是将图像切分成小的 patch(图像块),然后将每个 patch 当作序列输入 Transfor
代码链接:VIT(建议看我的,因为我都整理好了,而且代码注释的很详细。想看源码的话可以去官网)
论文链接:[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
官方链接:vit-pytorch
传统的图像处理都是用的卷积,直到多头注意力机制横空出世,NLP取得飞跃发展。有机智的学者发现,将其应用到图片处理…
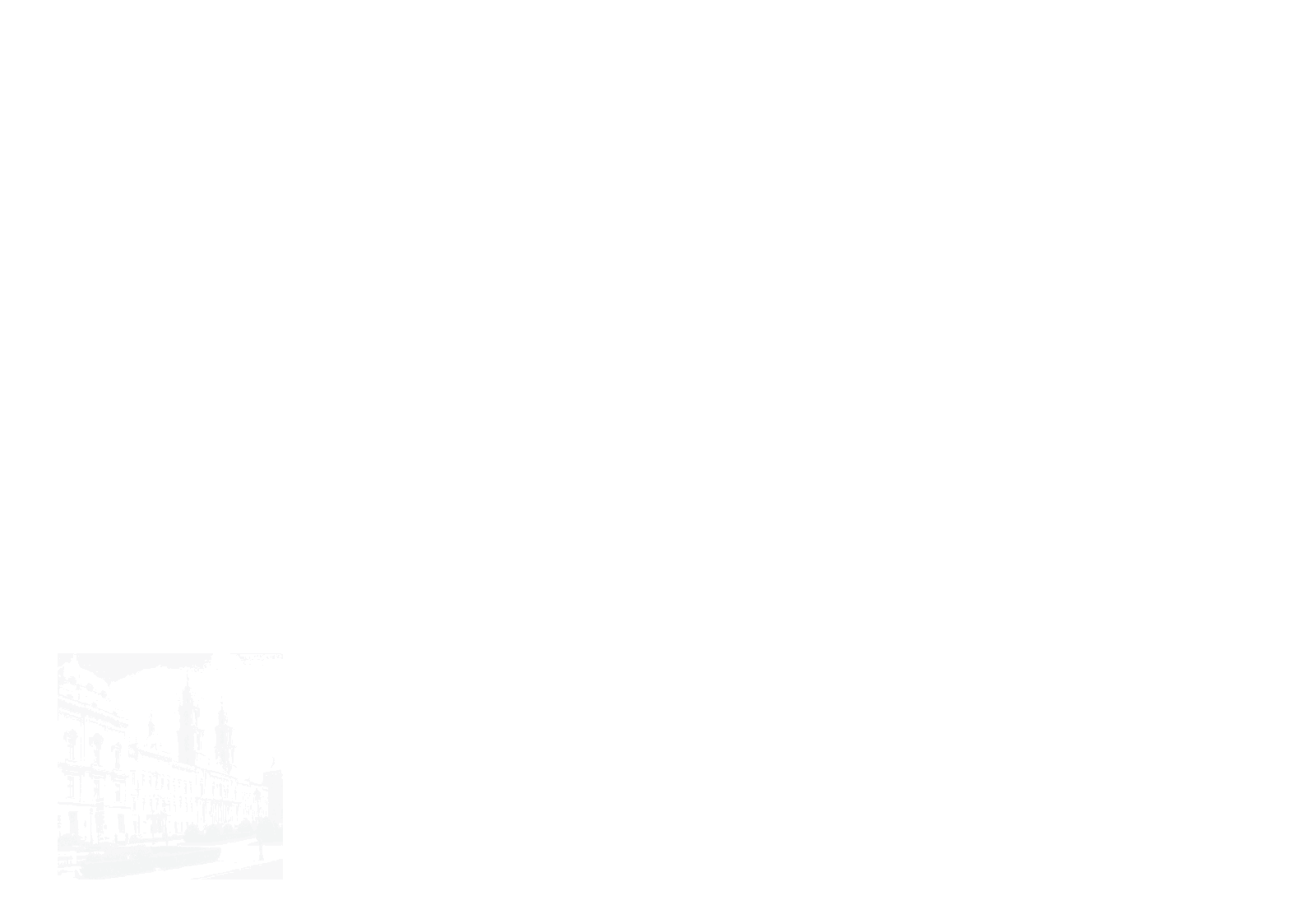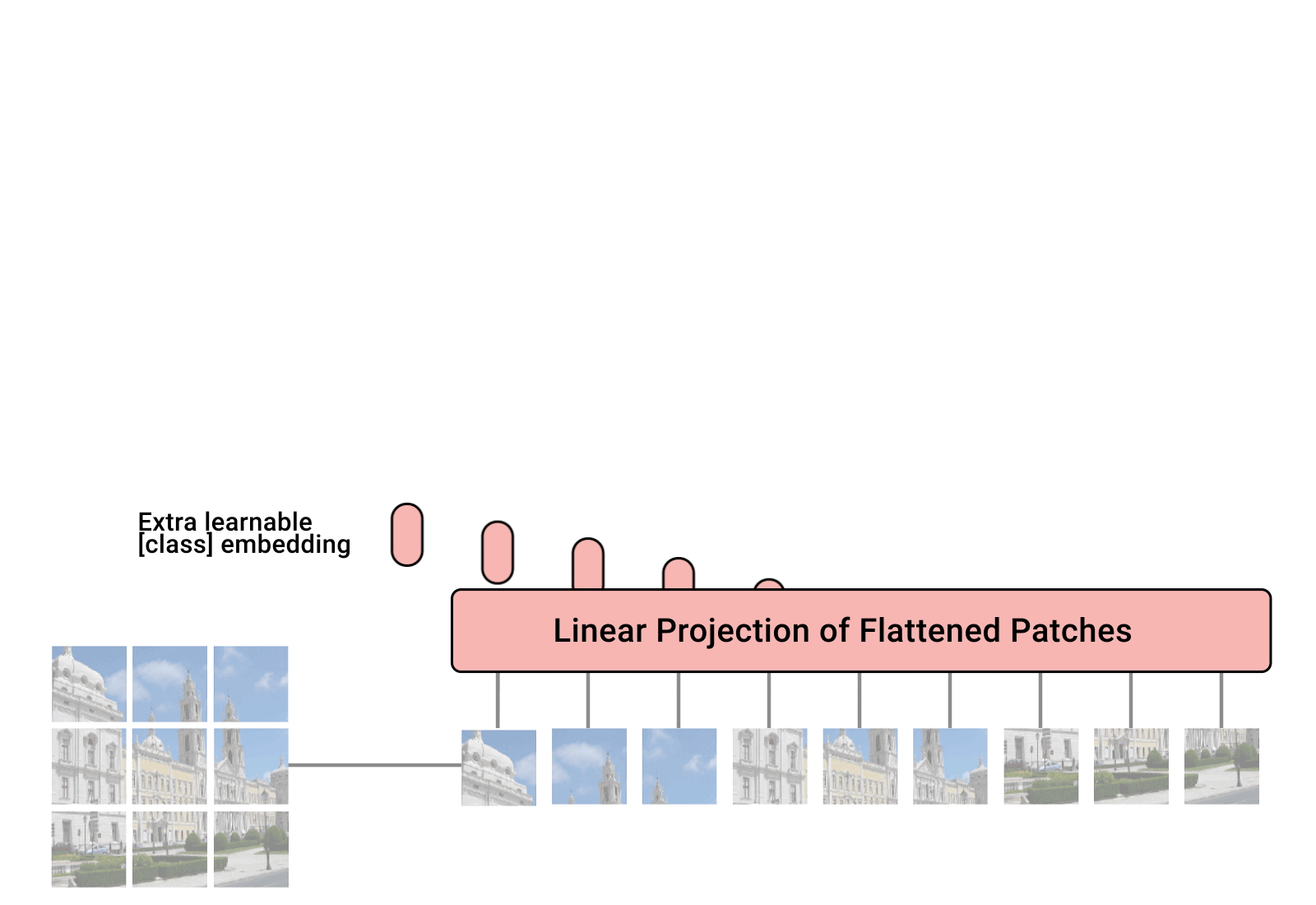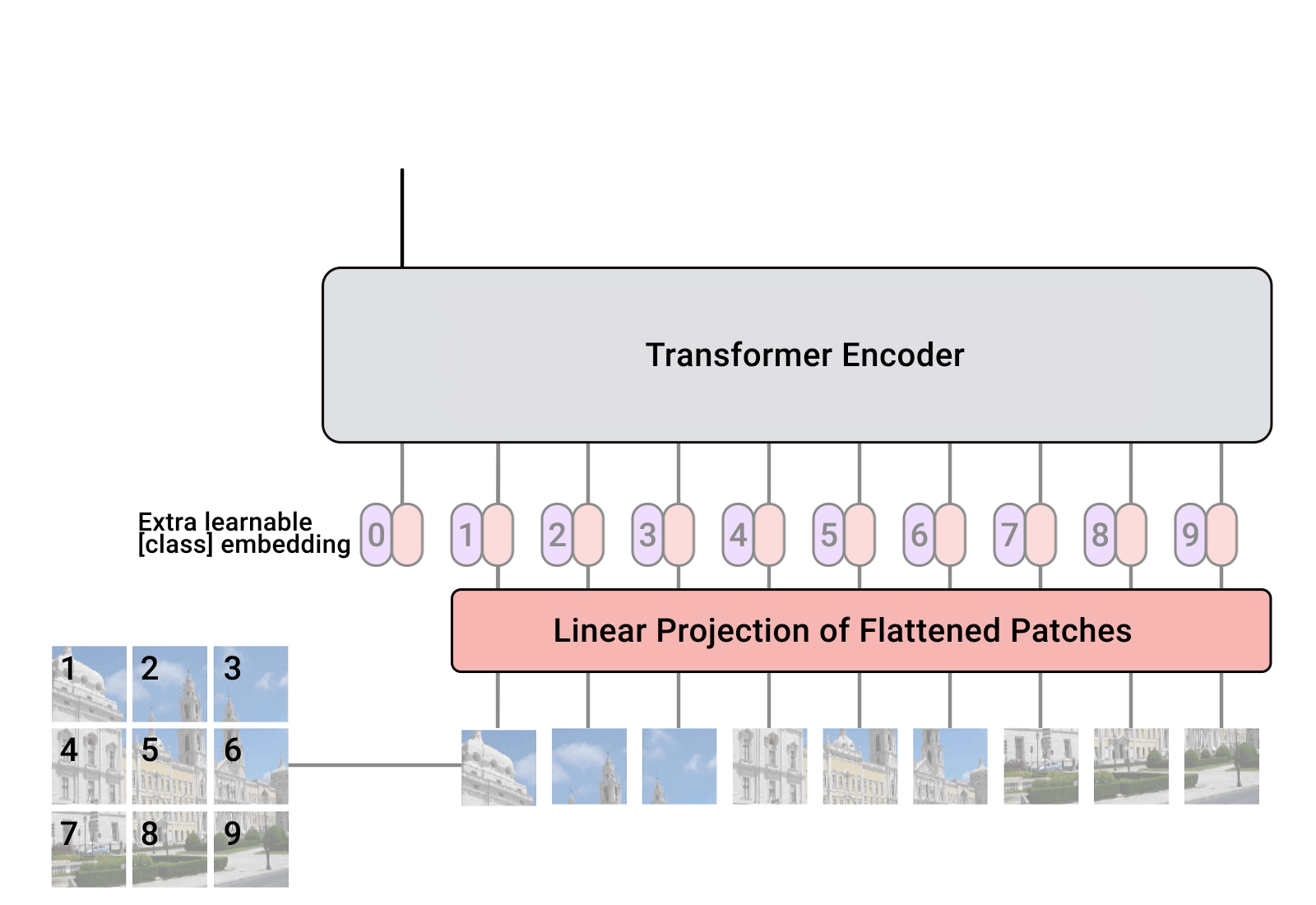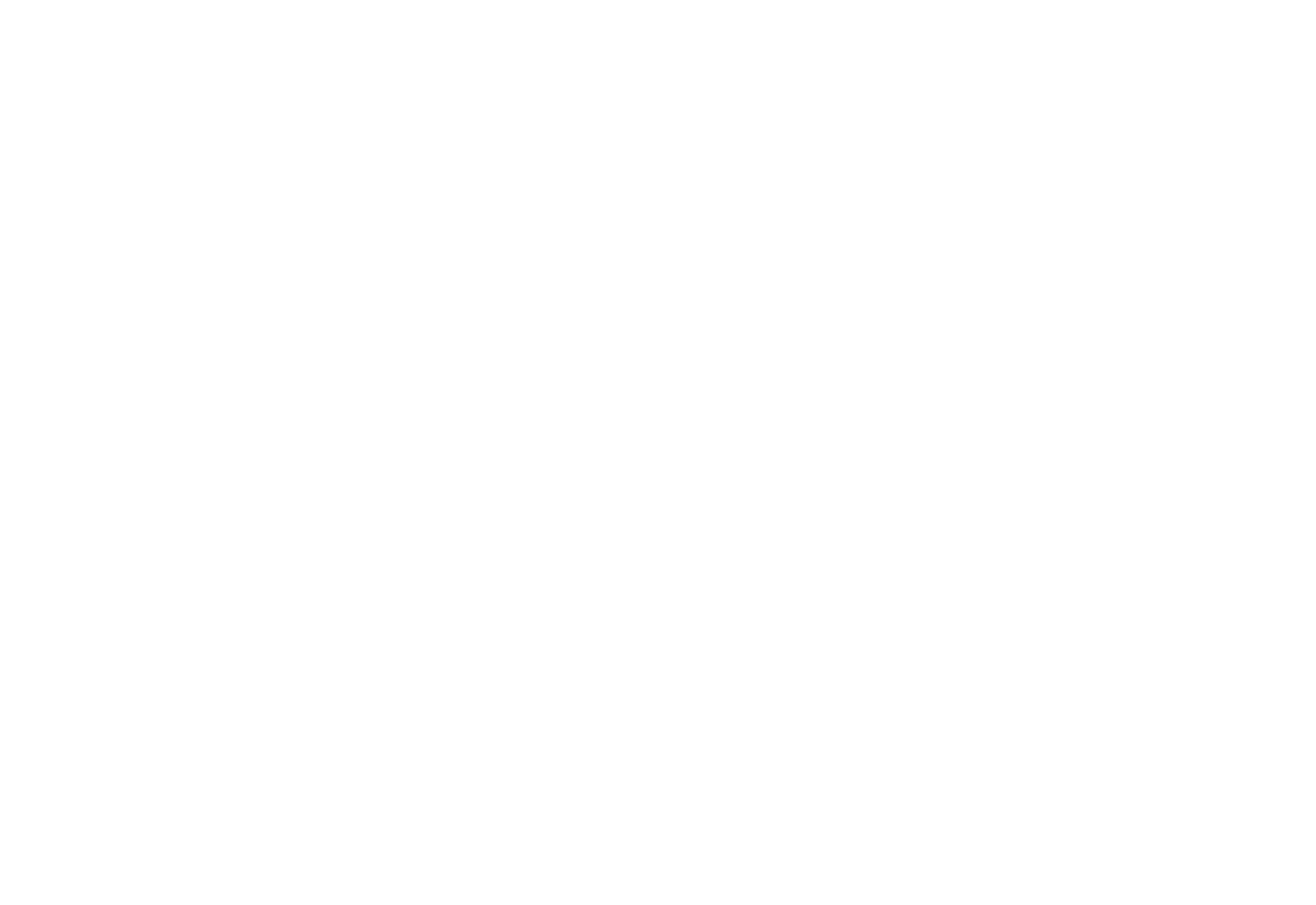
Vision Transformer (ViT) 是一种基于 Transformer 的图像分类模型,其核心思想是将图像切分成小的 patch(图像块),然后将每个 patch 当作序列输入 Transformer 模型进行处理,这张图应该看的很明白。
这里通俗的讲一下流程(为啥别人写的文章排版那么好看,我写的像个老年人,所以文章开头用白话文补救一下)
- 把一张图片切成许多个小块,比如一张 224x224 的图像会被分成14个 16x16 的小方块。每个小方块会被拉平成一个一维向量,就像把图片内容展平成数字列表。
- 每块小方块都需要一个“身份标签”(位置编码)来表明它在原图中的位置,这样模型就知道哪个小方块是哪里来的。
- 现在每块小方块都是一个向量,带有内容信息和位置信息。ViT 把这些向量送进 Transformer 模型,就像处理自然语言序列那样。Transformer 会通过 Query、Key、Value 的机制来理解这些小方块之间的关系。它会学到哪个小方块和哪个小方块更相关,逐步整合全局的信息。可以理解为像拼拼图一样,Transformer 会看每两块拼图之间的关系,决定哪些块应该放在一起。
- 在 Transformer 的最后,有一个专门的“特殊向量”(CLS Token),它负责总结整个图片的全局信息,类似于大脑对整幅图形成了“印象”。可以理解为CLS Token 是“总指挥”,它看完所有拼图后告诉我们“这张图是什么”。
- 最后一步,ViT 把 CLS Token 交给一个全连接层,预测这幅图属于哪一类,比如“猫”或“狗”。
1、图像预处理
-
切分图像为 Patch:
输入图像尺寸为 H×W×C(高、宽、通道数)。ViT 将图像划分为大小为 P×P 的小块(patches),得到N=(H×W)/P^2 ,每个 patch 的大小为 P×P×C。
每个 patch 被展平为一个向量,形成大小为P^2×C的向量。 -
线性映射(Patch Embedding):
使用一个全连接层将每个 patch 向量映射到一个固定维度 hidden_dim。这一步的输出是一个大小为 N×hidden_dim 的 patch embedding 矩阵。
config.patches = ml_collections.ConfigDict({'size': (16, 16)})
这是 ViT 的关键步骤之一:将输入图像分割成大小为 16×16 的小块(Patch),然后将这些 Patch 转化为序列输入 Transformer。
2、位置编码
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches + 1, config.hidden_size))
embeddings = x + self.position_embeddings
由于 Transformer 本身不考虑输入序列的顺序信息,ViT 引入了位置编码来保留每个 patch 的位置信息。具体步骤:
- 学习一个可训练的位置编码向量,维度为(batch_size, N+1,hidden_dim)。每个数据前还要加个cls_token,所以N+1
- 将位置编码与 patch embedding 相加,得到最终的序列表示。
这里提一嘴,VIT的位置编码用的是绝对位置。作者实验结果是,用相对位置的效果比用绝对位置的效果居然还低一点点。是不是理论上不应该,但是神经网络就是这样,不可解释性的东西太多了。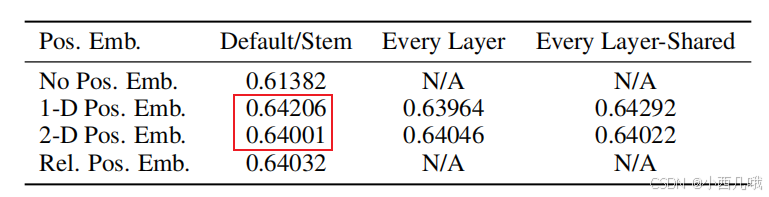
3、Embeddings(编码器)的初始化
def __init__(self, config, img_size, in_channels=3):
super(Embeddings, self).__init__()
self.hybrid = None
img_size = _pair(img_size)
if config.patches.get("grid") is not None:
grid_size = config.patches["grid"]
patch_size = (img_size[0] // 16 // grid_size[0], img_size[1] // 16 // grid_size[1])
n_patches = (img_size[0] // 16) * (img_size[1] // 16)
self.hybrid = True
else: # 直接基于 Patch 分割输入图像,不使用额外的 CNN 特征提取器
patch_size = _pair(config.patches["size"])
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
self.hybrid = False
if self.hybrid:
self.hybrid_model = ResNetV2(block_units=config.resnet.num_layers,
width_factor=config.resnet.width_factor)
in_channels = self.hybrid_model.width * 16
self.patch_embeddings = Conv2d(in_channels=in_channels,
out_channels=config.hidden_size,
kernel_size=patch_size, # 等于 Patch 的大小,确保每个 Patch 的信息被映射到一个嵌入向量中
stride=patch_size) # 等于 Patch 的大小,保证不重叠分割
# 提供序列位置信息,用于帮助 Transformer 区分不同的 Patch 顺序. n_patches + 1:包含 CLS Token 的位置
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches + 1, config.hidden_size)) # 绝对位置
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.dropout = Dropout(config.transformer["dropout_rate"])
数据流示例
假设输入图像大小为 224×224,Patch 大小为 16×16,隐藏维度为 768:
- 输入图像被分为 14×14=196 个 Patch。
- 经过卷积后,每个 Patch 转换为维度为 768 的嵌入。
- 加入一个 CLS Token,总序列长度变为 196+1=197。
- 为序列添加位置嵌入。
- 将序列输入 Transformer 进行处理。
4.注意力机制
self.query = Linear(config.hidden_size, self.all_head_size)
self.key = Linear(config.hidden_size, self.all_head_size)
self.value = Linear(config.hidden_size, self.all_head_size)
Transformer里最重要的就是query、key、value,分别表示当前位置的查询向量、所有位置的键向量、所有位置的值向量,就三个全连接层。
感觉很难解释它们之间相互作用的一个关系,我就通俗点解释吧。
假设你在图书馆找一本书,场景如下:
- Query: 你问图书管理员:“我要找和深度学习相关的书。”
- Key: 图书管理员看每本书的主题标签,找出符合“深度学习”主题的书。(全局搜索)
- Value: 图书管理员拿出这些书的内容,并告诉你书中的具体信息。(key的内容)
它们如何协作?
def forward(self, hidden_states):
mixed_query_layer = self.query(hidden_states)
mixed_key_layer = self.key(hidden_states)
mixed_value_layer = self.value(hidden_states)
# 将数据转换为适合多头注意力操作的形状 eg: 768 -> 12*64 将768条数据分配给12个注意力头
query_layer = self.transpose_for_scores(mixed_query_layer)
key_layer = self.transpose_for_scores(mixed_key_layer)
value_layer = self.transpose_for_scores(mixed_value_layer)
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) # 注意力分数 = query 点积 key
attention_scores = attention_scores / math.sqrt(self.attention_head_size) # 序列越长分数越大,对其进行比例缩放
attention_probs = self.softmax(attention_scores) # 得到实际权重值
weights = attention_probs if self.vis else None
attention_probs = self.attn_dropout(attention_probs)
context_layer = torch.matmul(attention_probs, value_layer) # 把权重分配给value 每个位置信息从这一步开始考虑全局特征
context_layer = context_layer.permute(0, 2, 1, 3).contiguous() # 将12头注意力还原回原来维度
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(*new_context_layer_shape)
attention_output = self.out(context_layer) # 再经过一个全连接层MLP将数据再次汇总 (你问我为什么,经验所得)
attention_output = self.proj_dropout(attention_output)
return attention_output, weights
-
Query 和 Key 的匹配:
- 通过点积计算 Query 和所有 Key 的相似度,衡量 Query 和 Key 的关联程度。
-
生成注意力权重:
- 将点积结果通过 softmax 转化为注意力权重(概率分布),表示 Query 该关注每个 Key 的程度。
-
取 Value 的加权平均:
- 根据注意力权重对所有 Value 进行加权平均,得到 Query 最终获取的信息。
- 这里为什么要加权平均呢,因为如果你的数据序列越长,那它得到的分数也会越大,这样对序列短的就不公平
看看将注意力放在图片上的一个效果图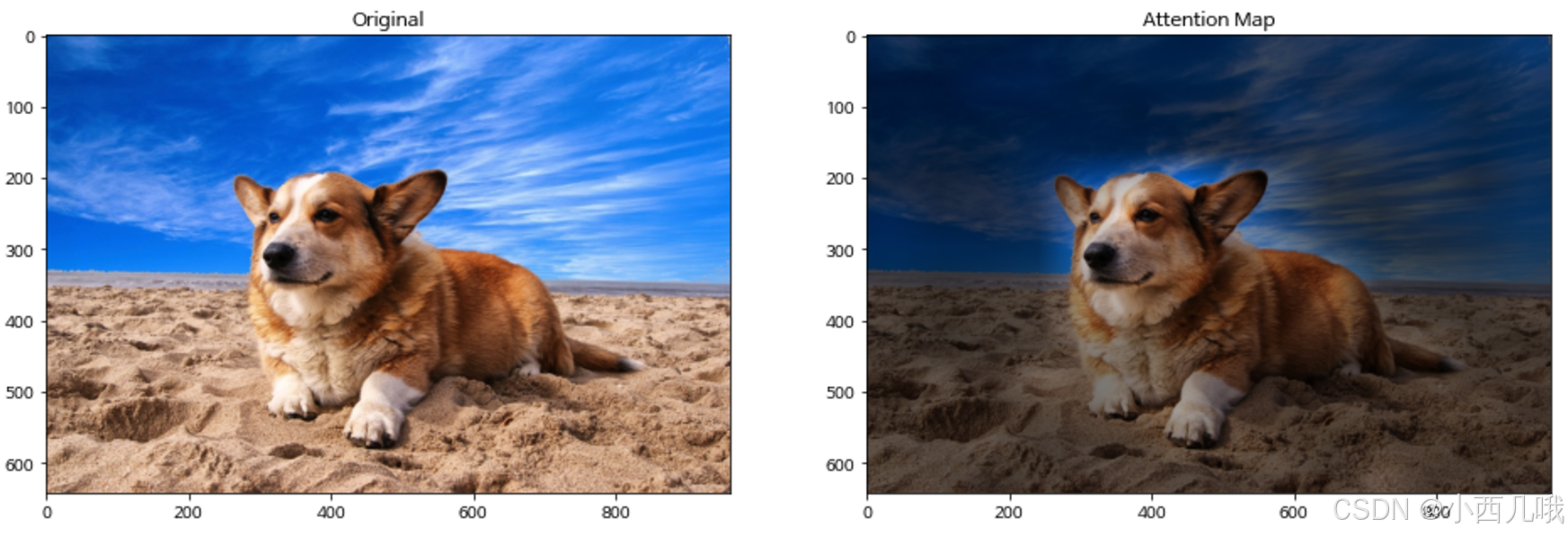
5. 总体流程
以下是完整的 ViT 结构流程:
- 输入图像 H×W×C。
- 切分为 N 个 patch,每个 patch 转换为大小为 hidden_dim 的向量。
- 加入 CLS token 和位置编码,得到大小为 (N+1)×hidden_dim 的序列。
- 经过 L 层 Transformer 编码器,每层包含 MHSA 和 FFN。
- 最终提取 CLS token 的输出表示,通过全连接层进行分类。
最后看看模型效果吧
输入图片 还是这只狗
输出结果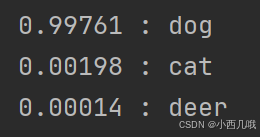

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)