机器学习实战案例——保险产品推荐(下)
书接上回(机器学习实战案例——保险产品推荐(上)),上回说到,由于任务的目的不同,单靠一个准确率去衡量一个模型的好坏是远远不够的,因此需要其他的指标去衡量模型的好坏。本案例的保险产品推荐,是一个二分类问题,因此有相当多的模型可供选择,不限于本篇博客所举例的,本篇博客主要带你了解机器学习实践的过程
文章目录
前言
书接上回(机器学习实战案例——保险产品推荐(上)),上回说到,由于任务的目的不同,单靠一个准确率去衡量一个模型的好坏是远远不够的,因此需要其他的指标去衡量模型的好坏
1.评价指标
对于分类任务,这里介绍以下五种:准确率、查全率(召回率)、查准率(精确率)、F1分数、AUC
1.1混淆矩阵
这里为了方便起见,首先介绍混淆矩阵的概念
混淆矩阵是一个二维矩阵,其行数和列数等于分类问题中的类别数量。它展示了模型预测结果与真实类别之间的对应关系,通过统计不同类别预测正确和错误的样本数量,直观地反映模型在各个类别上的分类表现。
| 预测\真实 | 正例 | 反例 |
|---|---|---|
| 正例 | TP | FP |
| 反例 | FN | TN |
- 真正例(True Positive,TP):实际类别为正例,模型预测也为正例的样本数量。
- 假正例(False Positive,FP):实际类别为负例,但模型预测为正例的样本数量,也被称为误报。
- 真反例(True Negative,TN):实际类别为负例,模型预测也为负例的样本数量。
- 假反例(False Negative,FN):实际类别为正例,但模型预测为负例的样本数量,也被称为漏报。
1.2准确率
准确率最简单,即预测正确的样本占总样本的比例
如果用混淆矩阵中的元素表示,公式如下
A c c u r a c y = T P + T N T P + F P + F N + T N Accuracy= \frac{TP+TN}{TP+FP+FN+TN} Accuracy=TP+FP+FN+TNTP+TN
- 适用场景:类别分布平衡时。
- 局限性:对类别不平衡问题不敏感(如 99% 正例 + 1% 反例时准确率可能很高但模型实际效果差,前面举过例子了)
1.3查全率
查全率,又称召回率,实际为正例的样本中被正确预测的比例,(关注 “不遗漏”)
用混淆矩阵中的元素表示,公式如下:
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
- 使用场景:适用于高漏判成本(如反欺诈)
1.4查准率
查准率,又称精确度,预测为正例样本中真正例的比例,(关注 “少错杀”)
用混淆矩阵中的元素表示,公式如下:
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
- 使用场景:适用于高误判成本(如医疗诊断)
1.5 F1分数
有时候单单凭借查准率和查全率并不能满足我们的需要,因此引入一个这种的一种表示F1值,它也可以引入一个比例因子,调整查全率和查准率的比例,即加权调和平均(这里不做介绍)
F1分数:精确率与召回率的调和 平均数,平衡两者
计算公式如下:
1 F 1 = 1 2 ( 1 R e c a l l + 1 P r e c i s i o n ) \frac{1}{F1}=\frac{1}{2}(\frac{1}{Recall}+\frac{1}{Precision}) F11=21(Recall1+Precision1)
1.6 AUC
AUC:通常指的是 ROC 曲线下的面积
ROC曲线:ROC 曲线是以假正率(False Positive Rate,FPR)为横轴,真正率(True Positive Rate,TPR)为纵轴绘制出的曲线。
真正例率(TPR)即查全率、召回率
T P R = T P T P + F N TPR=\frac{TP}{TP+FN} TPR=TP+FNTP
假正例率(FPR)
F P R = F P F P + T N FPR=\frac{FP}{FP+TN} FPR=FP+TNFP
2.评价指标函数
2.1回顾之前代码
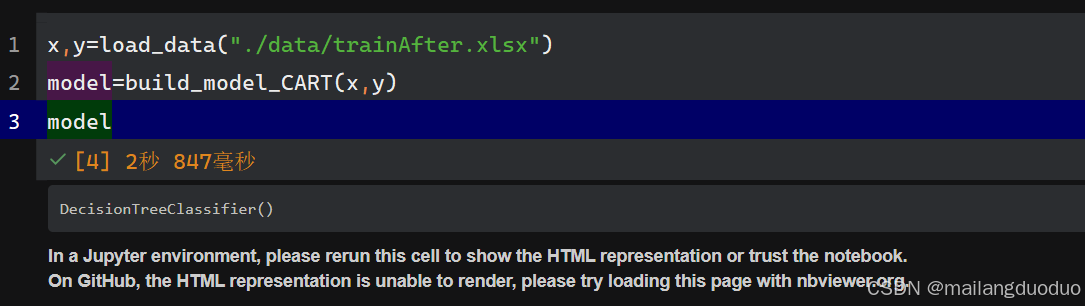
在之前我们训练了一个CART决策树模型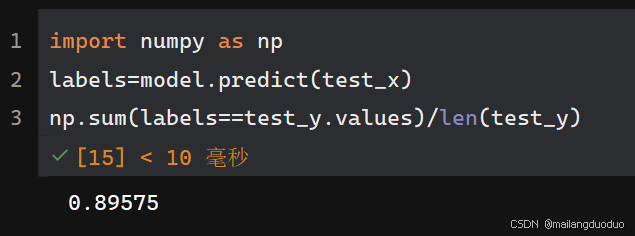
并实现了对准确率的计算,下面我们开始编写函数如何计算其他指标。
2.2函数编写
这些指标如何计算,已经封装在sklearn.metrics模块中,你也可以通过自定义函数编写实现,若是自己编写的话,这里给一点思路
# 准确率
A=np.sum(labels==test_y.values)/len(test_y)
# 查全率
R=np.sum(labels[labels==1]==test_y.values[labels==1])/np.sum(test_y.values[test_y.values==1])
# 查准率
P=np.sum(labels[labels==1]==test_y.values[labels==1])/np.sum(labels[labels==1])
# F1
F1=2*P*R/(P+R)
A,R,P,F1
运行结果: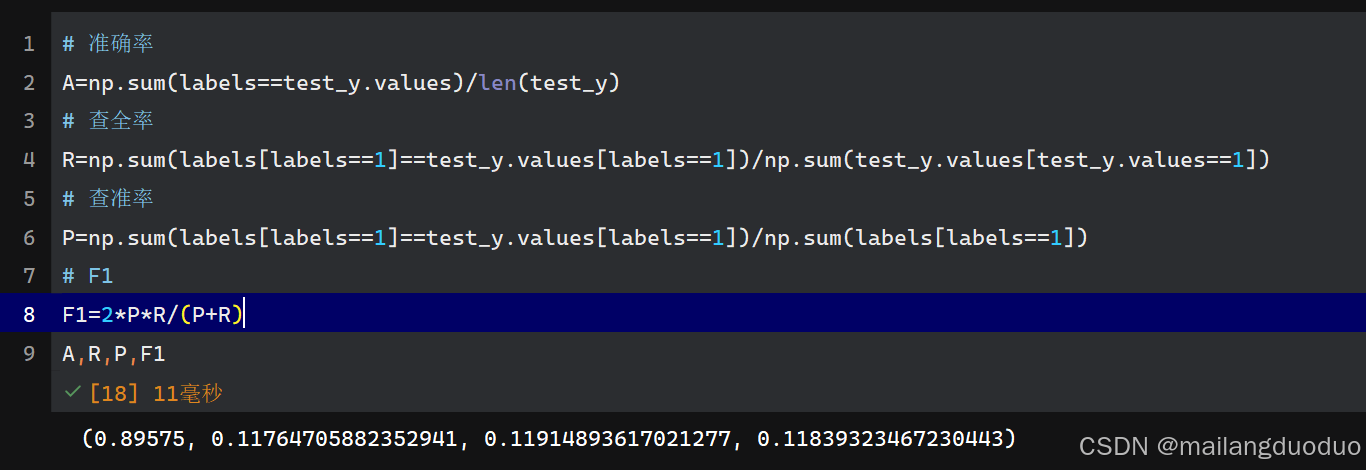
AUC实在写不出来,能力有限,我还是乖乖调封装好的函数吧
from sklearn.metrics import accuracy_score,recall_score,precision_score,f1_score,roc_auc_score
accuracy_score(test_y,labels),recall_score(test_y,labels),precision_score(test_y,labels),f1_score(test_y,labels),roc_auc_score(test_y,labels)
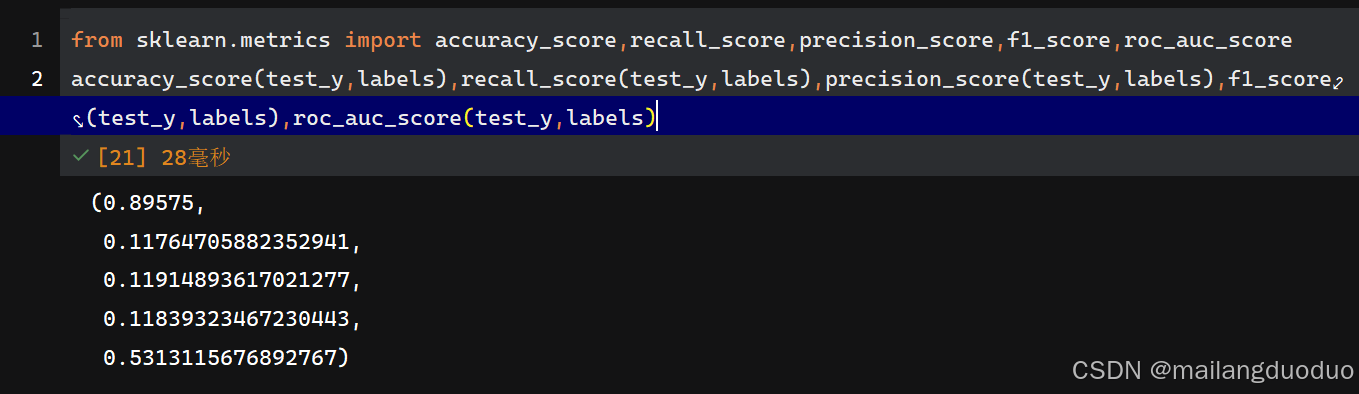
这里可以定义一个函数来评价该模型的预测结果
def get_score(y_true,y_pred):
A=accuracy_score(y_true,y_pred)
R=recall_score(y_true,y_pred)
P=precision_score(y_true,y_pred)
F1=f1_score(y_true,y_pred)
auc=roc_auc_score(y_true,y_pred)
return A,R,P,F1,auc
get_score(test_y,labels)
3.模型对比
我们之前定义的模型有CART决策树、ID3决策树、随机森林、多层感知机、KNN等五个模型,这里我们来对比一下他们的效果。
ten years later…
KNN出现了问题,好像是版本不兼容的原因,如有知道如何解决的欢迎评论区留言,这里就先跳过了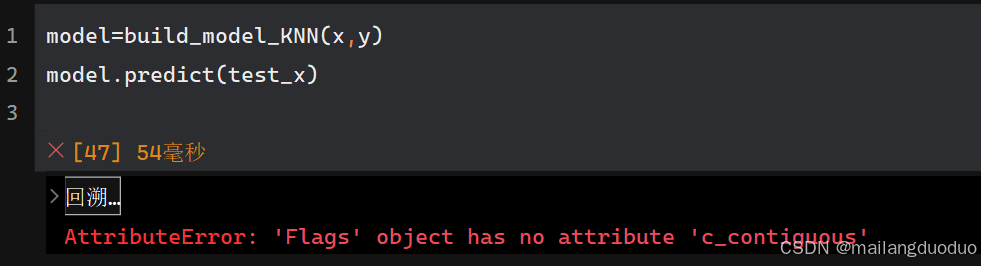
于是这里我就没有把KNN模型考虑进去,对比不同模型结果如下:
models=[build_model_CART,build_model_ID3,build_model_RF,build_model_MLP]
results = pd.DataFrame(columns=['Model', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
for model in models:
name=model.__name__.split('_')[-1]
model=model(x,y)
labels=model.predict(test_x)
A,R,P,F1,auc=get_score(test_y,labels)
row=pd.DataFrame([[name,A,R,P,F1,auc]],columns=['Model', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
results=pd.concat([results,row],ignore_index=True)
results
运行结果:
这里你也可以把KNN加进去,我的有问题,所以就没有添加
通过结果我们发现,不同模型均存在精度低和召回率低的现象,可能实验的数据出现了问题。再次分析实验的数据,发现样本集存在严重的不平衡问题,导致模型严重过拟合,因此需要平衡数据集。
4.平衡数据集
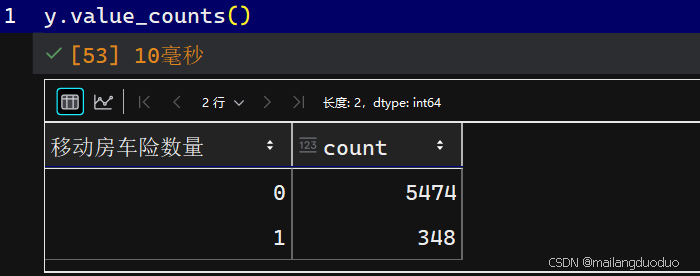
首先我们可以看一下各自的比例
y.value_counts()
4.1重采样调整类别比例
确实样本存在显著的不平衡,因此采用重采样的方式调整样本比例,将投保数上采样到未投保数
代码部分:
# 重采样
from sklearn.utils import resample,shuffle
train=pd.concat([x,y],axis=1)
train_0=train[train['移动房车险数量']==1]
train_1=train[train['移动房车险数量']==0]
train_0_upsampled=resample(train_0,replace=True,n_samples=len(train_1),random_state=123)
train_upsampled=pd.concat([train_0_upsampled,train_1])
train_upsampled=shuffle(train_upsampled)
train_upsampled['移动房车险数量'].value_counts()
运行结果: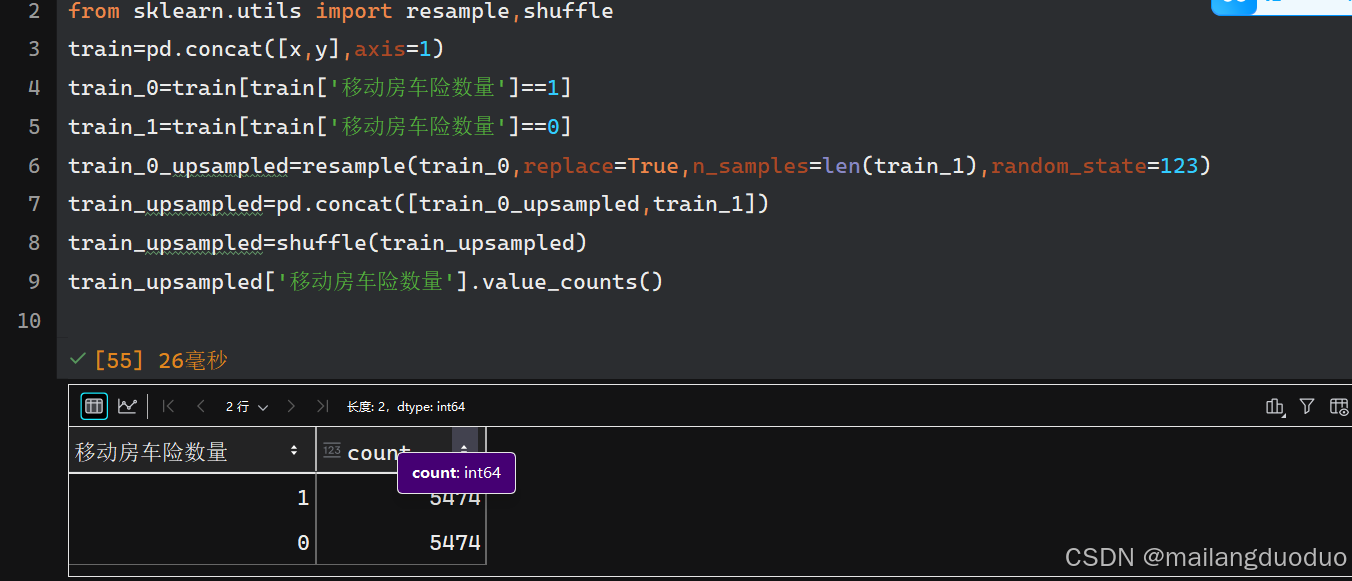
再次对模型进行训练,评估(注:训练前需要覆盖之前的x,y)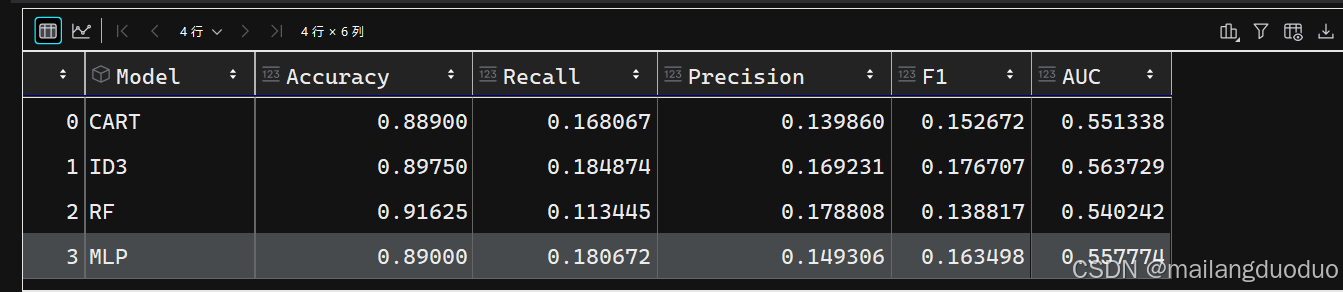
此时我们在对之前模型进行训练评估,貌似结果并不理想。这时可以尝试其他的比例
4.2参考书上的比例
这里举书上的例子:
将投保数上采样到原来的两倍,未投保数下采样原来的20%
# 重采样
from sklearn.utils import resample,shuffle
train=pd.concat([x,y],axis=1)
# train['移动房车险数量'].value_counts()
train_up=train[train['移动房车险数量']==1]
train_down=train[train['移动房车险数量']==0]
train_up_upsampled=resample(train_up,replace=True,n_samples=696,random_state=0)
train_down=resample(train_down,replace=False,n_samples=1095,random_state=0)
train_process=shuffle(pd.concat([train_up_upsampled,train_down]))
train_process['移动房车险数量'].value_counts()
运行结果: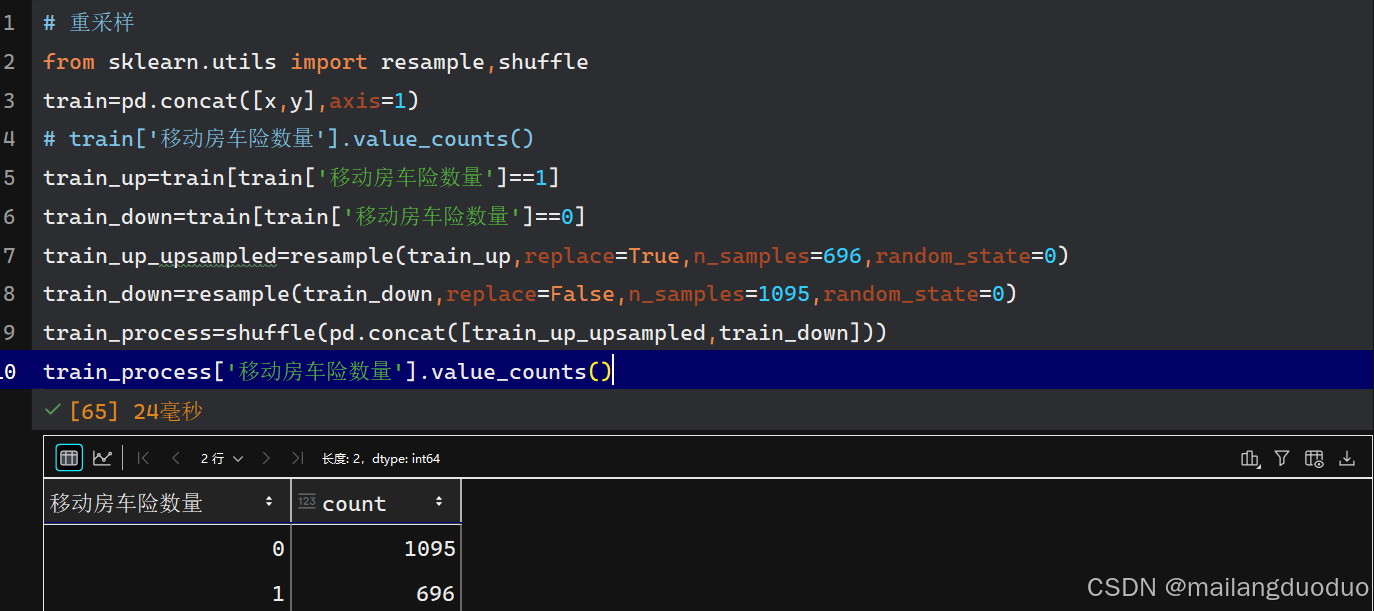
再次对模型进行训练,评估的如下结果:
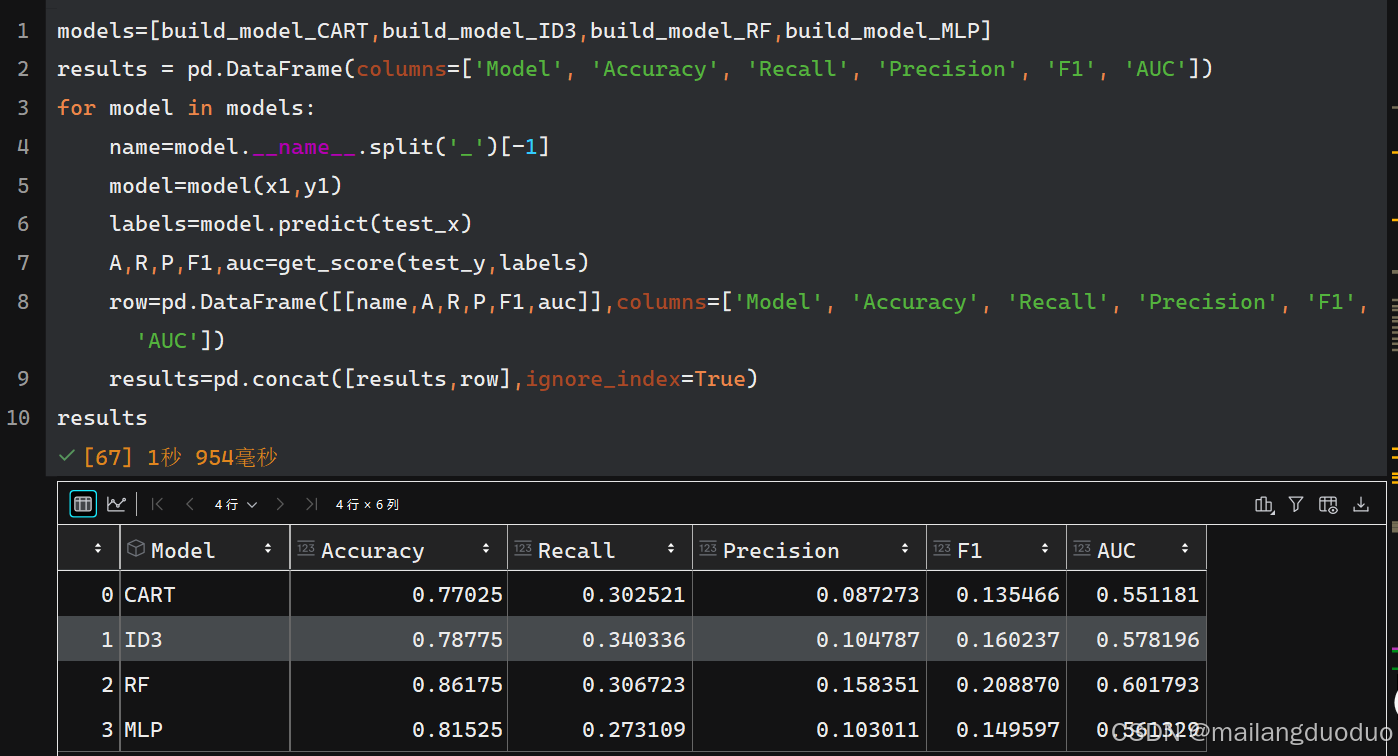
4.3备注
可能会有部分人参考某书籍的方法对模型评估时,使用了如下代码:
from sklearn.model_selection import cross_validate
classifier=build_model_RF(x1,y1)
scores = cross_validate(classifier, test_x, test_y, cv=5, scoring=('accuracy', 'precision', 'recall', 'f1', 'roc_auc'))
或者基于某AI修改的代码
scoring = {
'accuracy': make_scorer(accuracy_score),
'precision': make_scorer(precision_score, zero_division=0),
'recall': make_scorer(recall_score, zero_division=0),
'f1': make_scorer(f1_score, zero_division=0),
'roc_auc': make_scorer(roc_auc_score)
}
scores = cross_validate(classifier, test_x, test_y, cv=10, scoring=scoring)
然后对的结果取个平均,这种方式和我们上面定义的在结果上会有很大差异,目前还不太清楚什么原因,通过将测试集进行类平衡,效果会出现明显的改善,但从模型训练的角度考虑,不应该对测试集进行类平衡。如有知道原因,欢迎留言!!!
5.算法调参
平衡数据集后的模型已经有了较好的结果,但是我们尚未对模型进行调整,并不确定当前参数是否是较佳的参数,因此需要调整模型参数。
老师说:调参又称“炼丹”,觉得很有意思,就记下来了
此处仅举个别模型的参数调整过程(ID3决策树),其他的模型也是类似的过程
5.1参数查看
可以通过ctrl+鼠标左键或者ctrl+p查看该函数有哪些参数,决策树中可调节参数如下: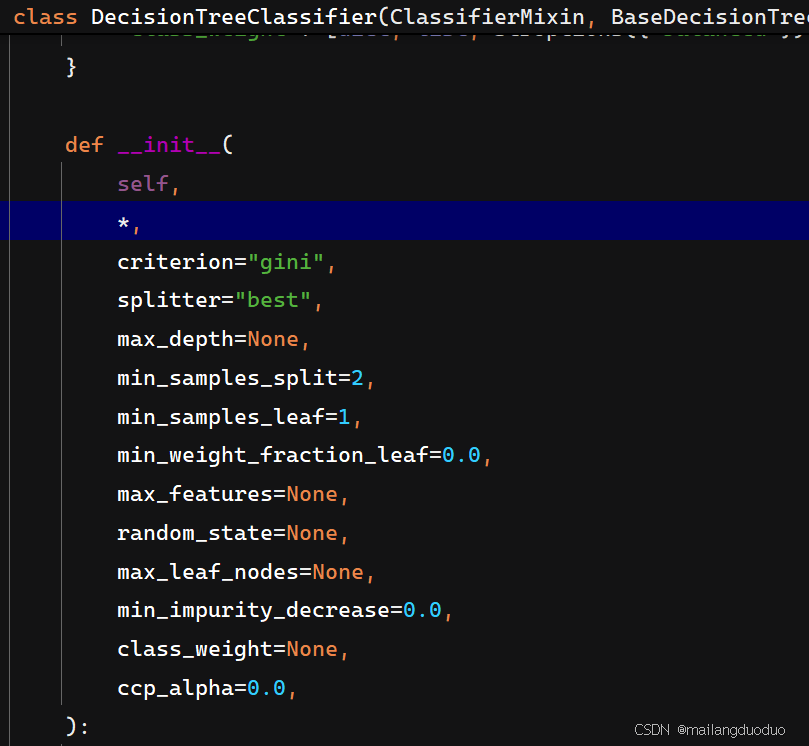
5.2参数解释
- criterion:指定特征分裂的不纯度度量标准。此处有默认值
“gini”,即默认CART决策树 - splitter:控制特征分裂的策略
- max_depth:限制树的最大深度
- min_samples_split:指定节点再分裂所需的最小样本数
- min_samples_leaf:定义叶节点所需的最小样本数
- min_weight_fraction_leaf:与 min_samples_leaf 类似,但基于样本权重总和的比例。叶节点样本权重和需不低于此值
- max_features:限制分裂时考虑的特征数量
- random_state:设置随机种子,确保模型训练结果可复现
- max_leaf_nodes:限制树的最大叶节点数量。
- min_impurity_decrease:设定分裂后不纯度(基尼值或信息熵)减少的阈值。若分裂带来的不纯度减少小于此值,放弃分裂。
- class_weight:处理类别不平衡问题。
- ccp_alpha:指定代价复杂度剪枝(CCP)的参数。值越大,剪枝力度越强,简化树结构以防止过拟合。
这些都可以通过查相关API查看,这里提供一个网站sklearn API
5.3调参
这里我们选择调节max_depth参数,调节过程如下:
from sklearn.tree import DecisionTreeClassifier
def build_model_ID3(x,y,param):
classifier=DecisionTreeClassifier(criterion='entropy',max_depth=param,random_state=0)
model=classifier.fit(x,y)
return model
maxdepth=list(range(1,30))
results = pd.DataFrame(columns=['max_depth', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
for depth in maxdepth:
model=build_model_ID3(x1,y1,depth)
labels=model.predict(test_x)
A,R,P,F1,auc=get_score(test_y,labels)
row=pd.DataFrame([[depth,A,R,P,F1,auc]],columns=['max_depth', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
results=pd.concat([results,row],ignore_index=True)
results
运行结果: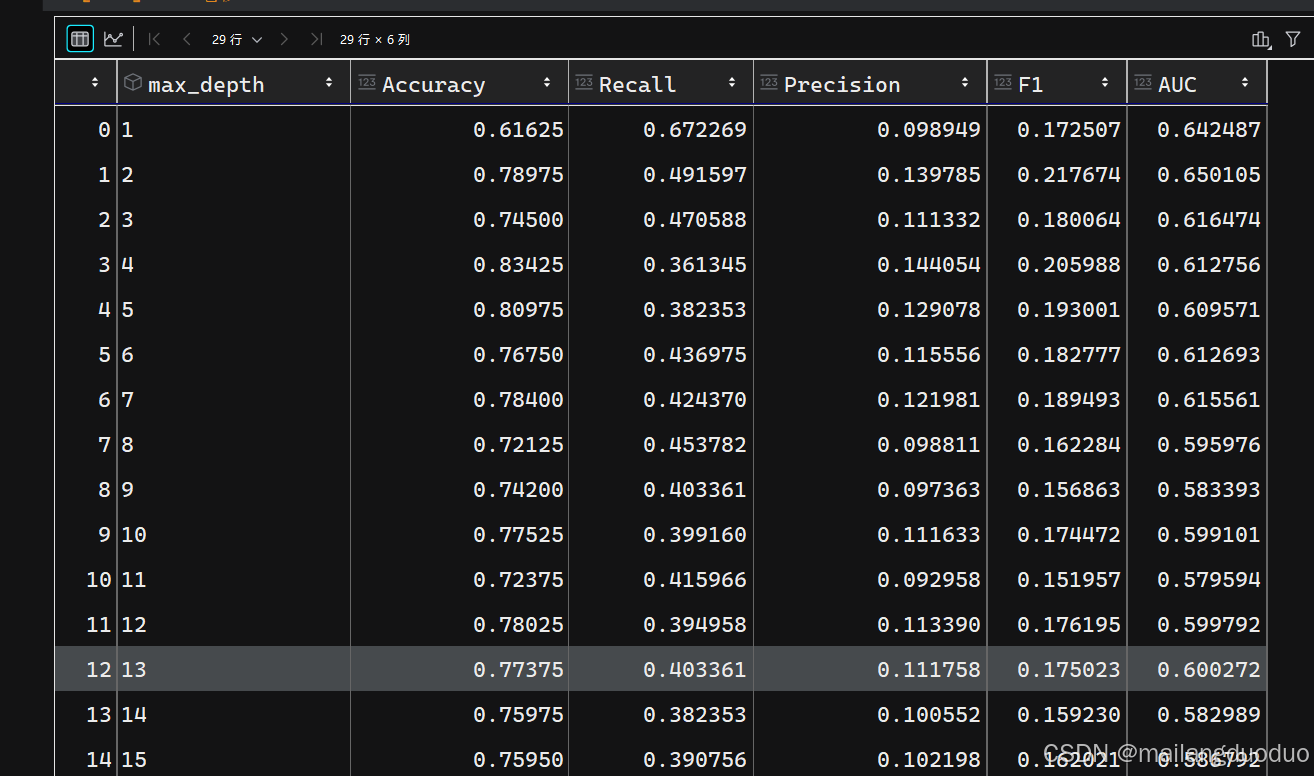
从结果上看,该参数设置在13时,效果最好
这时我们可以将max_depth固定在13,去调节其他的参数,比如说max_features,简单调整上述代码即可,
代码如下:
from sklearn.tree import DecisionTreeClassifier
def build_model_ID3(x,y,param):
classifier=DecisionTreeClassifier(criterion='entropy',max_depth=13,random_state=0,max_features=param)
model=classifier.fit(x,y)
return model
params=list(range(5,65))
results = pd.DataFrame(columns=['max_feature', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
for param in params:
model=build_model_ID3(x1,y1,param)
labels=model.predict(test_x)
A,R,P,F1,auc=get_score(test_y,labels)
row=pd.DataFrame([[param,A,R,P,F1,auc]],columns=['max_feature', 'Accuracy', 'Recall', 'Precision', 'F1', 'AUC'])
results=pd.concat([results,row],ignore_index=True)
results
运行结果:
从结果来看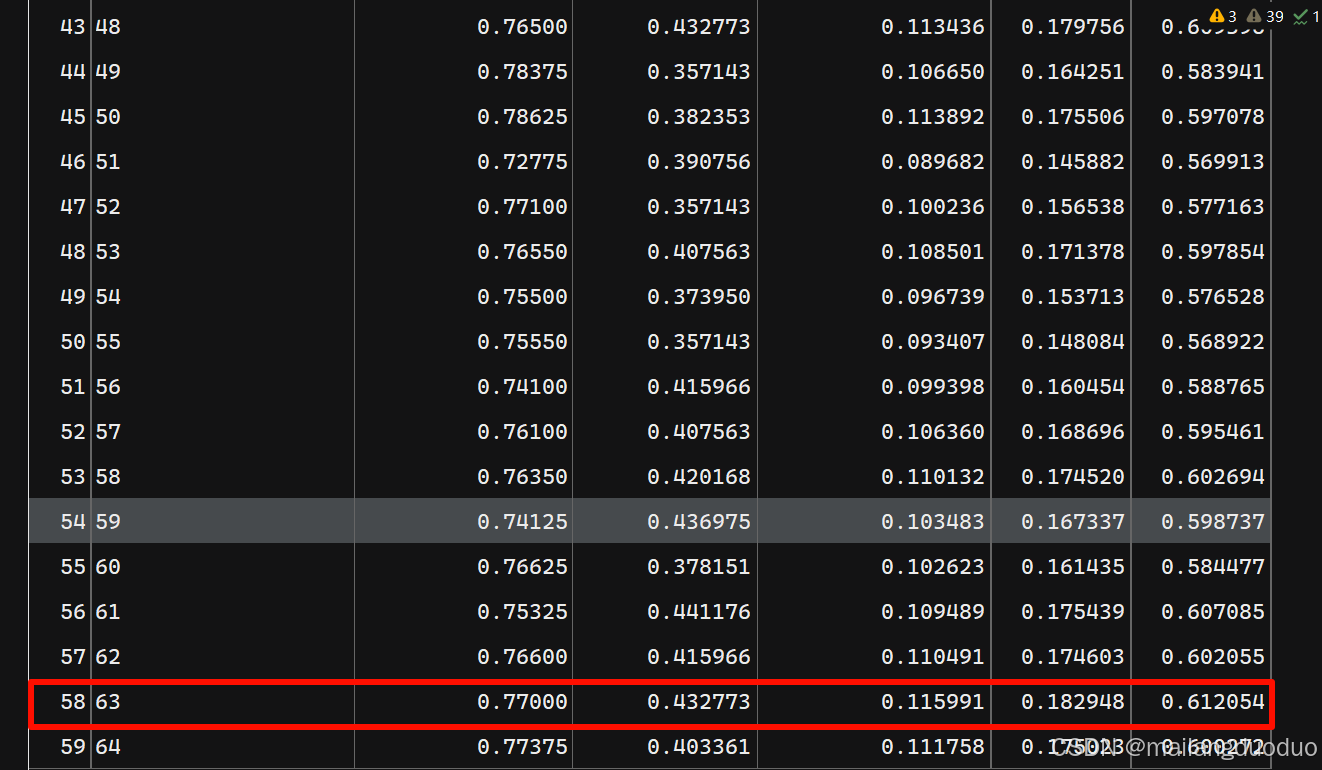
max_features=63时,效果最好
结语
本案例的保险产品推荐,是一个二分类问题,因此有相当多的模型可供选择,不限于本篇博客所举例的,本篇博客主要带你了解机器学习实践的过程,因为本人所学有限,也遇到了一些问题,欢迎交流!!!
本案例参考教材:《Python机器学习实战案例(第二版)》赵卫东、董亮

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)