简单学习定义循环神经网络(RNN)
与传统的前馈神经网络不同,RNN在每个时间步都会接收输入和前一时间步的隐藏状态,并输出当前时间步的隐藏状态和预测结果。这种循环结构使得RNN能够对序列中的上下文信息进行建模,从而更好地处理序列数据的特征和依赖关系。RNN的一个重要变体是长短期记忆网络(Long Short-Term Memory,LSTM),它通过引入门控机制解决了传统RNN在处理长序列时的梯度消失和梯度爆炸问题。RNN的核心思想
·
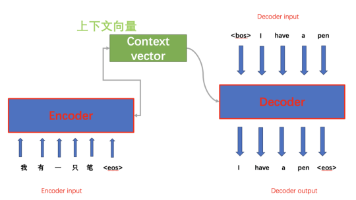
循环神经网络(Recurrent Neural Network,RNN)是一种具有循环结构的神经网络模型,主要用于处理序列数据。与传统的前馈神经网络不同,RNN在每个时间步都会接收输入和前一时间步的隐藏状态,并输出当前时间步的隐藏状态和预测结果。这种循环结构使得RNN能够对序列中的上下文信息进行建模,从而更好地处理序列数据的特征和依赖关系。 RNN的一个重要变体是长短期记忆网络(Long Short-Term Memory,LSTM),它通过引入门控机制解决了传统RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM通过遗忘门、输入门和输出门来控制信息的流动,从而能够更好地捕捉序列中的长期依赖关系。
循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络模型。与传统的前馈神经网络不同,RNN具有循环连接,可以在网络中保留并利用之前的信息。 RNN的主要特点是可以处理任意长度的输入序列,并且能够在序列中保持状态信息。这使得RNN非常适合处理语言、音频、时间序列等具有时序关系的数据。RNN的核心思想是通过循环连接将当前时刻的输入与上一时刻的隐藏状态进行结合,从而实现对序列信息的建模。 以下是一个简单的RNN的代码示例:
import numpy as np
# 定义RNN类
class RNN:
def __init__(self, input_size, hidden_size, output_size):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
# 初始化权重矩阵
self.Wxh = np.random.randn(hidden_size, input_size) * 0.01 # 输入到隐藏层的权重
self.Whh = np.random.randn(hidden_size, hidden_size) * 0.01 # 隐藏层到隐藏层的权重
self.Why = np.random.randn(output_size, hidden_size) * 0.01 # 隐藏层到输出层的权重
# 初始化偏置向量
self.bh = np.zeros((hidden_size, 1)) # 隐藏层的偏置
self.by = np.zeros((output_size, 1)) # 输出层的偏置
def forward(self, inputs):
# 初始化隐藏状态和输出
h = np.zeros((self.hidden_size, 1))
outputs = []
# 遍历输入序列
for x in inputs:
# 更新隐藏状态
h = np.tanh(np.dot(self.Wxh, x) + np.dot(self.Whh, h) + self.bh)
# 计算输出
y = np.dot(self.Why, h) + self.by
outputs.append(y)
return outputs
def backward(self, inputs, outputs, targets, learning_rate):
# 初始化梯度
dWxh = np.zeros_like(self.Wxh)
dWhh = np.zeros_like(self.Whh)
dWhy = np.zeros_like(self.Why)
dbh = np.zeros_like(self.bh)
dby = np.zeros_like(self.by)
dh_next = np.zeros_like(outputs[0])
# 反向传播
for t in reversed(range(len(inputs))):
# 计算输出误差
dy = outputs[t] - targets[t]
# 更新输出层权重和偏置的梯度
dWhy += np.dot(dy, outputs[t].T)
dby += dy
# 计算隐藏层误差
dh = np.dot(self.Why.T, dy) + dh_next
# 计算隐藏层的梯度
dh_raw = (1 - outputs[t] * outputs[t]) * dh
dbh += dh_raw
dWxh += np.dot(dh_raw, inputs[t].T)
dWhh += np.dot(dh_raw, outputs[t-1].T)
# 更新下一时刻的隐藏层误差
dh_next = np.dot(self.Whh.T, dh_raw)
# 更新权重和偏置
self.Wxh -= learning_rate * dWxh
self.Whh -= learning_rate * dWhh
self.Why -= learning_rate * dWhy
self.bh -= learning_rate * dbh
self.by -= learning_rate * dby
以上代码实现了一个简单的RNN类,包括前向传播和反向传播的过程。在前向传播过程中,通过循环遍历输入序列,更新隐藏状态并计算输出。在反向传播过程中,根据输出误差和隐藏层误差,计算权重和偏置的梯度,并更新它们。 需要注意的是,以上代码只是一个简化的示例,实际应用中可能需要考虑更多的细节和优化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)