今日学习卷积神经网络CNN
卷积神经网络是多层感知器(MLP)的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来。卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。卷积神经网络解决的问题:(1)将图像展开为向量会丢失空间信息;(2)参数过多效率低下,训练困难;(3)大量的参数会导致网络过拟合。
1. 概述
卷积神经网络是多层感知器(MLP)的变种,由生物学家休博尔和维瑟尔在早期关于猫视觉皮层的研究发展而来。
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一。
卷积神经网络解决的问题:
(1)将图像展开为向量会丢失空间信息;
(2)参数过多效率低下,训练困难;
(3)大量的参数会导致网络过拟合。
2. 卷积
2.1 卷积
考下面这篇文章:知乎:原来卷积是这么计算的 。
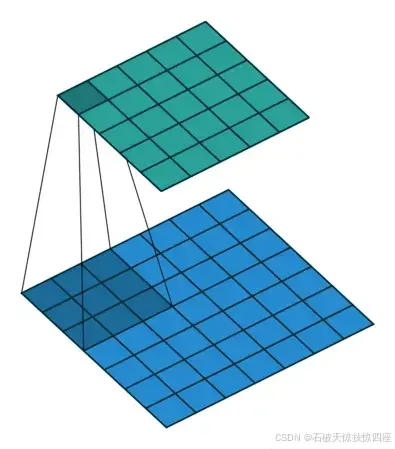
如上图1所示,卷积操作其实就是每次提取一个特定大小的矩阵F(图中矩阵中的阴影部分),然后将其对输入X(图中蓝色矩阵)依次扫描并进行内积的运算过程。可以看到,阴影部分每移动一个位置就会计算得到一个卷积值(绿色矩阵中的阴影部分),当F扫描完成后就得到了整个卷积后的结果Y(绿色矩阵)。
将这个特定大小的矩阵F称为卷积核,它可以是一个也可以是多个;将卷积后的结果Y称为特征图,并且每个卷积核卷积后都会得到一个对应的特征图;最后。对于输入X的形状,都会用三个维度来进行表示,即宽(width),高(high),通道(channel)。上图中输入X的形状为[7,7,1]。
2.2 多核卷积
对于同一个输入,通过两个不同的卷积核对其进行卷积特征提取,最后便能得到两个不同的特侦图,这就是多核卷积。
2.3 卷积的计算
2.3.1 单通道单卷积核
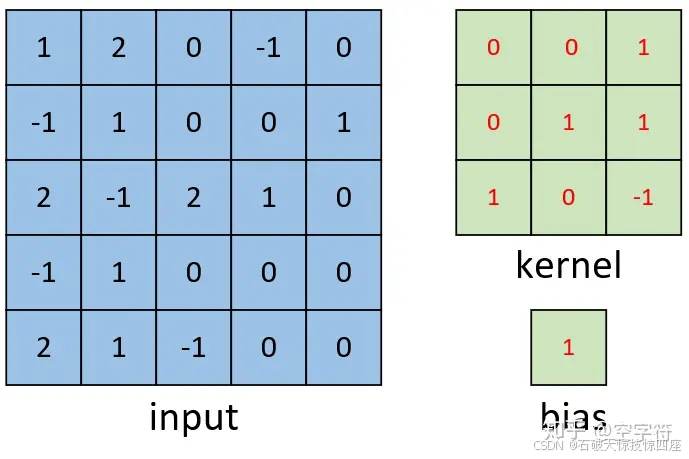
如上图2所示,现有一张形状为[5,5,1]的灰度图,需要用图2右边的卷积核对其进行卷积处理,同时再考虑到偏置的作用。
如图3所示,右边为卷积后的特征图,左边为卷积核对输入图片左上方进行卷积时的示意图。
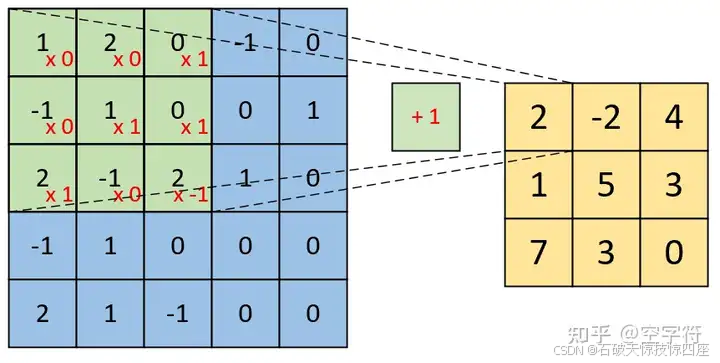
因此,对于最后的卷积的结果,得到的将是一个如上图3所示的形状为[3,3,1]的特征图。
2.3.2 单通道多卷积核
如图4所示,左边依旧为输入矩阵,现在要对右边所示的两个卷积核进行卷积处理。
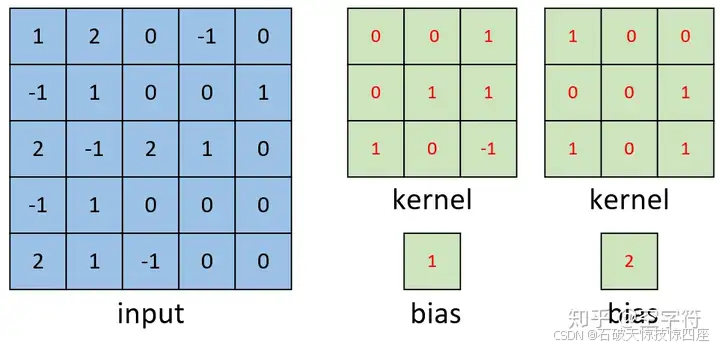
右边第一个卷积核如图3所示,对于右边第二个卷积核,计算过程如下图5所示:
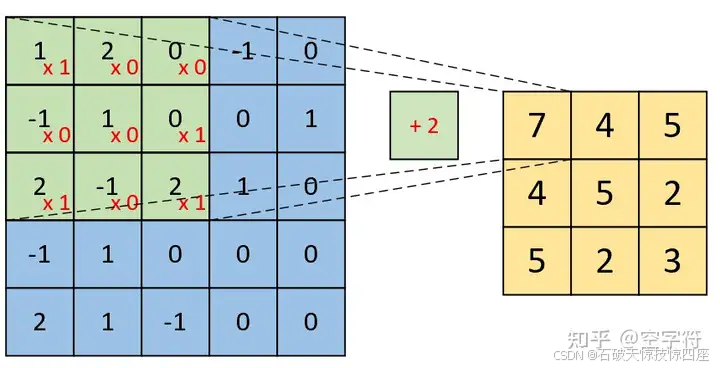
最后可以得到如下图6所示的,形状为[3,3,2]的卷积特征图,其中2表示两个特征通道。
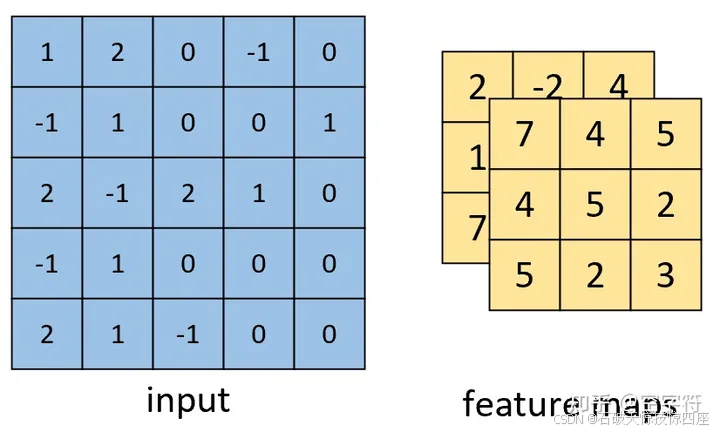
2.3.3 多通道单卷积核
对于多通道的卷积过程 ,总体上还是同单通道的一样,都是每次选取特定位置上的神经元进行卷积,然后依次移动直到卷积结束。
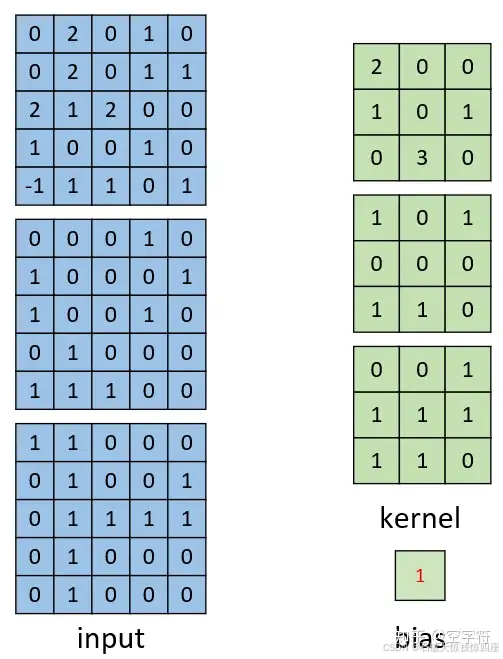
如图7所示,左边为包含有三个通道的输入,右边为一个卷积核和一个偏置。注意,强调一下右边的仅仅只是一个卷积核,不是三个。笔者看到不少人在这个地方都会搞错。因为输入是三个通道,所以在进行卷积的时候,对应的每一个卷积核都必须要有三个通道才能进行卷积。下面我们就来看看具体的计算过程。
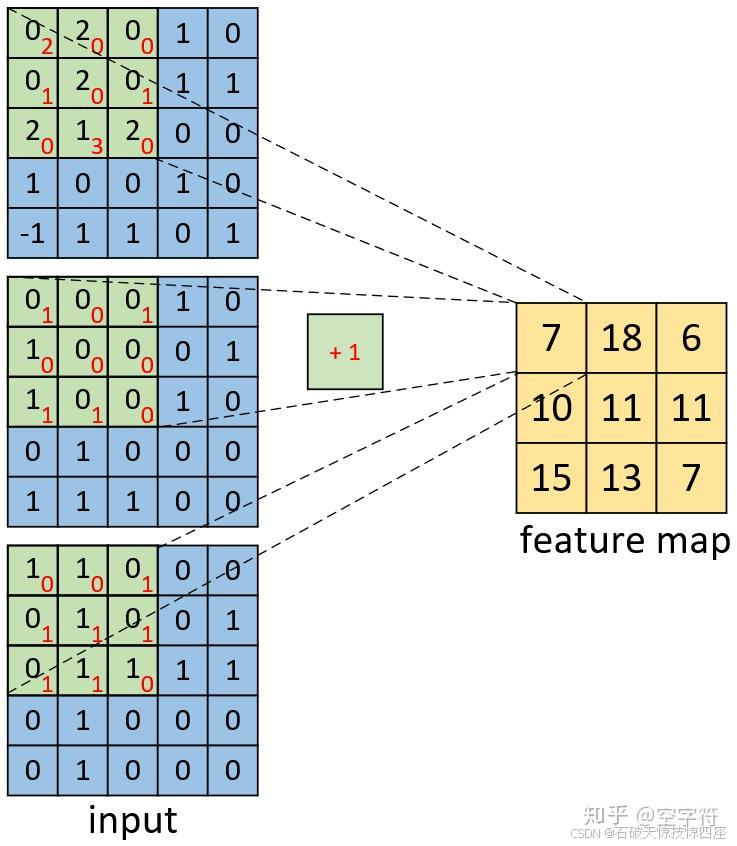
如上图8所示,右边为卷积后的特征图(feature map),左边为一个三通道的卷积核对输入图片左上放进行卷积时的示意图。同理,对于其它部分的卷积计算过程也类似于上述计算步骤。由此我们便能得到如图8右边所示卷积后的形状为[3,3,1]的特征图。
2.3.4 多通道多卷积核
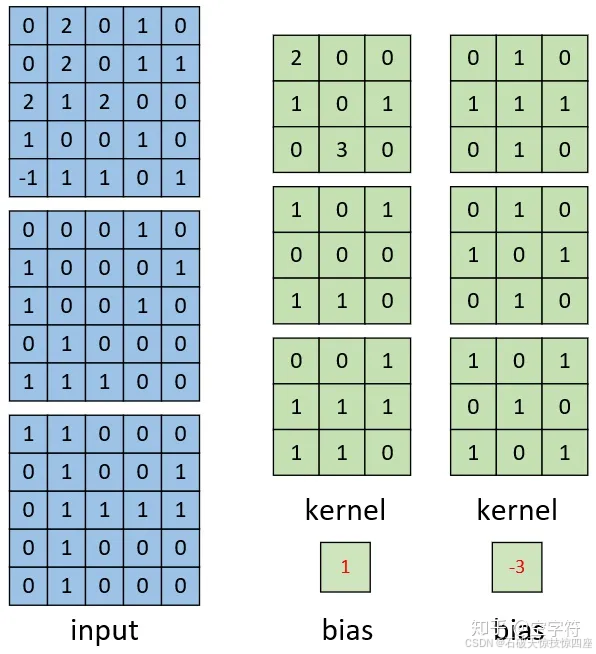
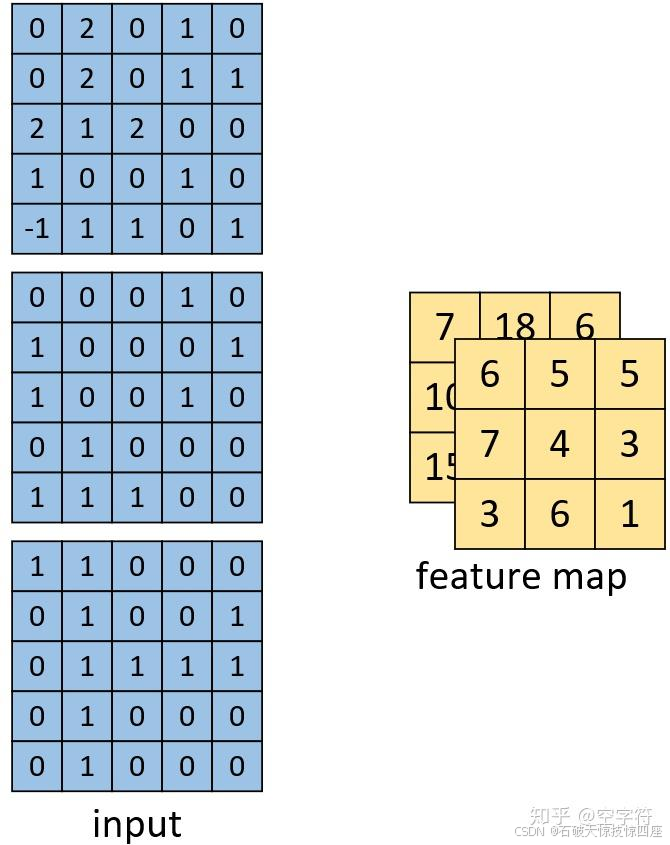
如图9所示,左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。同时可以看到,第一个卷积核就是图7中所示的卷积核,其结果如图8所示。对于第二个卷积核,其计算过程也类似,都是将每个通道上的卷积结果进行相加,最后再加上偏置。因此,最后我们便能得到如图10右边所示的,形状为[3,3,2]的卷积特征图,其中2表示两个特征通道。
同时,从上面单通道卷积核多通道卷积的计算过程可以发现:
(1)原始输入有多少个通道,其对应的一个卷积核就必须要有多少个通道,这样才能与输入进行匹配,也才能完成卷积操作。换句话说,如果输入数据的形状为[n,n,c],那么对应每个卷积核的通道数也必须为c。
(2)用k个卷积核对输入进行卷积处理,那么最后得到的特征图一定就会包含有k个通道。例如,输入为[n,n,c],且用k个卷积核对其进行卷积,则卷积核的形状必定为[w1,w2,c,k],最终得到的特征图形状必定为[h1,h2,k];其中w1,w2为卷积核的宽度,h1,h2为卷积后特征图的宽度。
2.4 深度卷积
所谓深度卷积就是卷积之后再卷积,然会再卷积。卷积的次数可以是几次也可以是几十、甚至可以是几百次。卷积操作可以看作是对上一次输入的特征提取,即用来抓取输入中是否包含有某一类的特征。但是,通常情况下,输入的图像数据都是由一系列特征横向和纵向组合叠加起来的。因此,对于同一层次(横向)的特征我们需要通过多个卷积核对输入进行特征提取;而对于不同层次(纵向)的特征我们需要通过卷积的叠加来进行特征提取。
简单一句话总结起来就是,在相邻空间位置上具有依赖关系的数据均可以通过卷积操作来进行特征提取。为什么?回顾一下图像数据最重要的属性是什么?不就是相邻位置上的像素之存在着空间上的依赖(space-correlation )关系吗?对于任意位置上的像素值来说,其周围的像素值或多或少都与其有着一定的关系,例如颜色的渐变过程。
因此,对于那些相邻空间位置存在着依赖关系的数据,我们都可以通过卷积操作来对其进行特征提取。
3. 神经元
神经元是人工神经网络的基本处理单元,一般是多输入单输出的单元,其结构如图11所示。
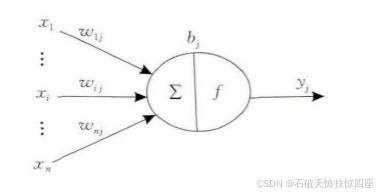
其中:表示输入信号;
个输入信号同时输入神经元
。
表示输入信号
与神经元
连接的权重值,
表示神经元的内部状态即偏置值,
为神经元的输出。输入输出之间的对应关系可以用下式表示:
为激励函数,其可以有很多种选择,可以是线性纠正函数(Rectified Linear Unit,ReLU),sigmoid函数、tanh(x)函数、径向基函数等。
4. 多层感知器
多层感知器(Multilayer Perceptron,MLP)是由输入、隐含层(一层或者多层)及输出层构成的神经网络模型,它可以解决单层感知器不能解决的线性不可分问题。图12是含有2个隐含层的多层感知器网络拓扑结构图。
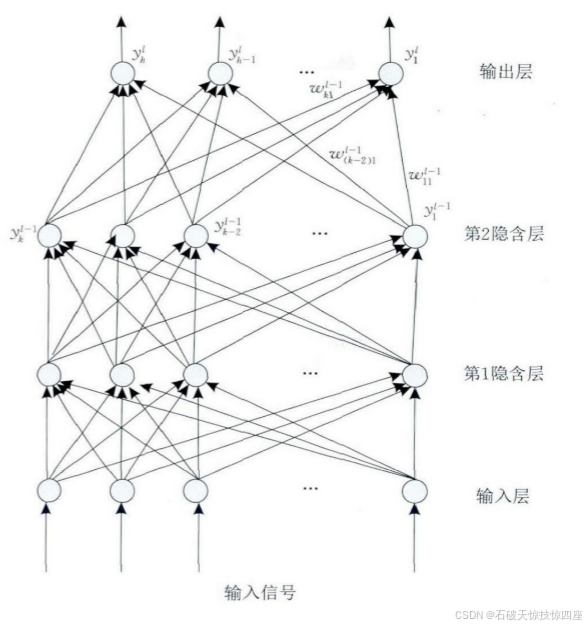
输入层神经元接收输入信号,隐含层和输出层的每一个神经元与之相邻层的所有神经元连接,即全连接,同一层的神经元之间不相连。图12中,有箭头的线段表示神经元间的连接和信号的传输方向,且每个连接都有一个连接权值。隐含层和输出层中每一个神经元的输入为前一层所有神经元输出值的加权和。假设是MLP中的第
层第
个神经元的输入值,
和
分别为该神经元输出值和偏置值,
为该神经元与第
层第
个神经元的连接权值,则有:
当多层感知器用于分类时,其输入神经元个数为输入信号的维数,输出神经元个数为类别数,隐含层个数即隐含层神经元你个数视具体情况而定。但在实际应用中,由于受到参数学习效率影响,一般使用不超过3层的浅层模型。
5.CNN
1962年,生物学家Hubel和Wiesel通过对猫视觉皮层的研究,发现在视觉皮层中存在一系列复杂构造的细胞。这些细胞对视觉输入空间的局部区域很敏感,它们被称为感受野。感受野以某种方式覆盖整个视觉域,它在输入空间中起到局部作用,因而能够更好地挖掘出存在于自然图像中强烈的局部空间相关性。
1980年,日本科学家福岛邦彦在论文《Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position》提出了一个包含卷积层、池化层的神经网络结构。
1998年,在这个基础上,Yann Lecun在论文《Gradient-Based Learning Applied to Document Recognition》中提出了LeNet-5,将BP算法应用到这个神经网络结构的训练上,就形成了当代卷积神经网络的雏形。
2012年,Imagenet图像识别大赛中,Hinton组的论文《ImageNet Classification with Deep Convolutional Neural Networks》中提到的AlexNet引入了全新的深层结构和dropout方法,一下子把error rate从25%以上提升到了15%,颠覆了图像识别领域。
随后2013年的ZFNet、2014年牛津大学VGG(Visual Geometry Group)提出的VGG-Nets和GoogLeNet都进一步把对卷积神经网络的研究推上新的高度。
2015年,何恺明推出的ResNet在网络结构上做了大创新,不再是简单的堆积层数,ResNet在卷积神经网络的新思路,是深度学习发展历程上里程碑式的事件。
自2015年ResNet提出后,ResNet的变种网络层出不穷,都各有特点,网络性能也有一定的提升。2017年提出的DenseNet,吸收了ResNet最精华的部分,并在此上做了更加创新的工作,是的网络性能进一步提升。DenseNet是一种具有密集连接的卷积神经网络,在该网络中,任何两层之间都有直接的连接,也就是说,网络的每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会直接传给其后面所有层作为输入。
CNN的基本结构由输入层、卷积层(convolutional layer)、池化层(pooling layer,也称为取样层)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再接一个卷积层,以此类推。由于卷积层中输出特征面的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此得名。
5.1 卷积层
卷积层由多个特征面(Feature Map)组成,每个特征面由多个神经元组成,它的每个神经元通过卷积核与上一层特征面的局部区域相连。卷积核是一个权值矩阵(如对于二维图像而言可为3*3或5*5矩阵)。CNN的卷积层通过卷积操作提取输入的不同特征,第一层卷积层提取低级特征如边缘、线条、角落,更高层的卷积层提取更高级的特征。为了更好地理解CNN,下面以一维CNN (1DCNN)为例,二维和三维CNN可依次进行拓展。图13所示为一维CNN的卷积层和池化层结构示意图,最顶层为池化层,中间层为卷积层,最底层为卷积层的输入层。
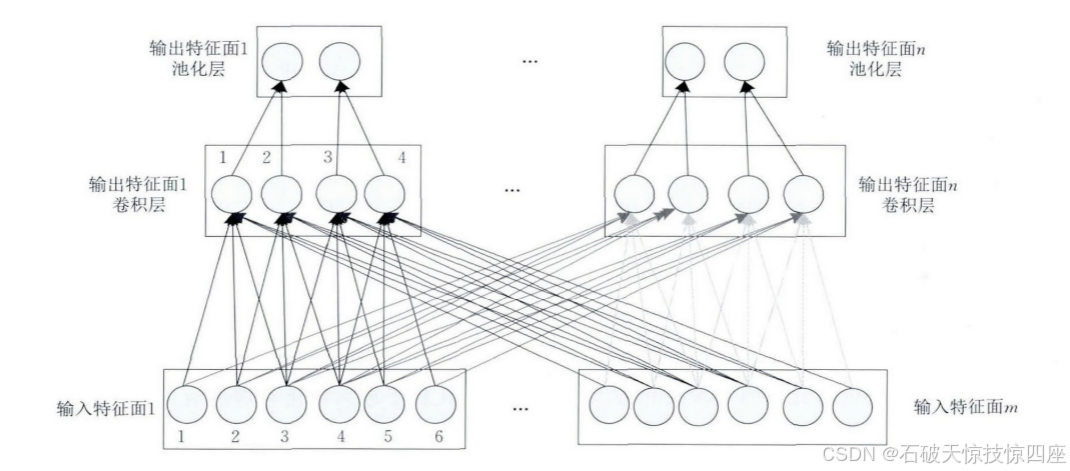
由图13可看出卷积层的神经元被组织到各个特征面中,每个神经元通过一组权值被连接到上一层特征面的局部区域,即卷积层中的神经元与其输入层中的特征面进行局部连接。然后将该局部加权和传递给一个非线性函数如ReLU函数即可获得卷积层中每个神经元的输出值。在同一个输入特征面和同一个输出特征面中,CNN的权值共享,如图13所示,权值共享发生在同一层当中,不同层权值不共享。通过权值共享可以减小模型复杂度,使得网络更易于训练。
5.2 池化层
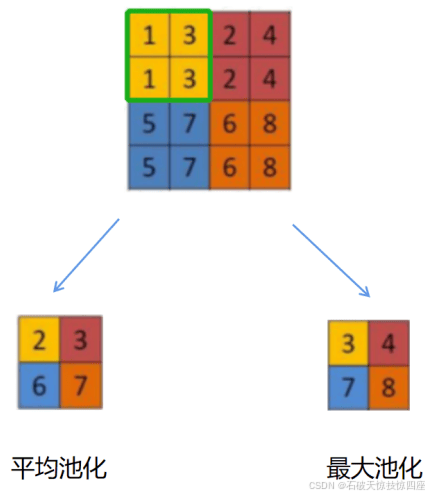
池化层紧跟在卷积层之后,同样由多个特征面组成,它的每一个特征面唯一对应与其上一层的一个特征面,不会改变特征面的个数。如图13,卷积层是池化层的输入层,卷积层的一个特征面与池化层中的一个特征面唯一对应,且池化层的神经元也与其输入层的局部接受域相连,不同神经元局部接受域不重叠。池化层旨在通过降低特征面的分辨率来获得具有空间不变性的特征,池化层起到二次提取特征的作用,它的每个神经元对局部接受域进行池化操作。池化层用于对卷积层输出的特征图进行降维和抽样,以减少模型参数数量和计算复杂度。常见的池化操作包括最大池化和平均池化,通过在特定区域内取最大值或平均值来保留重要信息并减少数据量。池化操作还能增强模型对于平移和尺度变化的鲁棒性,提高模型的泛化能力。具体操作如图14所示。
5.3 全连接层
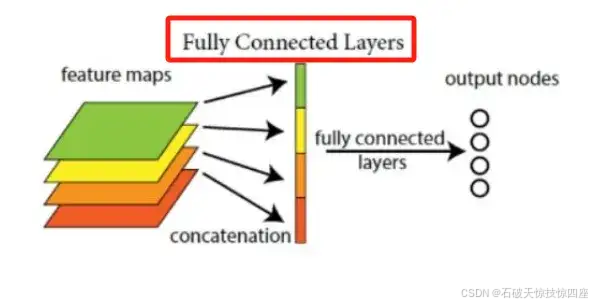
在CNN结构中,经过多个卷积层和池化层后,连接着1个或多个全连接层。与MLP类似,全连接层中的每个神经元与其前一层的所有神经元进行全连接。全连接层可以整合卷积层或池化层中具有类别区分性的局部信息。为了提升CNN网络性能,全连接层每个神经元的激励函数一般采用ReLU函数。最后一层全连接层的输出值被传递给一个输出层,可以采用softmax逻辑回归(softmax regression)进行分类,该层也可称为softmax层(softmax layer)。具体操作如图15所示。
5.4 与传统的模式识别算法相比
CNN的本质就是每一个卷积层包含一定数量的特征面或者卷积核。与传统MLP相比,CNN中卷积层的权值共享使网络中可训练的参数变小,降低了网络模型复杂度,减少过度拟合,从而获得二了一个更好的泛化能力。同时,在CNN结构中使用池化操作使模型中的神经元个数大大减少,对输入空间的平移不变性也更具有鲁棒性。而且CNNN结构的可拓展性很强,它可以采用很深的层数。深度模型具有更强的表达能力,它能够处理更复杂的分类问题。问的来说,CNN的局部连接、权值共享和池化操作使其比传统MLP具有更少的连接和参数,从而更容易训练。
本文主要参考文献:周飞燕《卷积神经网络研究综述》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 38
38 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)