【踩坑笔记】Pytorch 训练好模型,预测时使用不同的 batch 出来的结果不一样
训练好模型后,单个样本预测的结果,和多个样本批量预测的结果不一样,有时候差异较小,有时候差异较大。`torch.nn.utils.rnn.pad_sequence` 会根据样本的最大长度自动添加填充数据来统一数据维度。如果每次测试输入的样本最大长度不一样,填充的长度也会不同,导致最终的计算结果不一样。
·
问题描述:
训练好模型后,单个样本预测的结果,和多个样本批量预测的结果不一样,有时候差异较小,有时候差异较大。
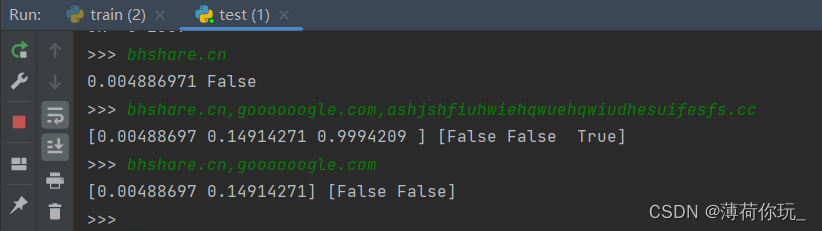
如下图所示,使用 LSTM 做了个 DGA(恶意域名)识别的任务,属于二分类。在输入不同的样本的情况下,返回的结果不一样。相同的样本则结果一致。

原因分析:
一开始查了一些资料,基本都是说 Norm 层 和 Dropout 层没有禁用的原因,但是代码里面已经加了 model.eval()。后面又试了固定 numpy 和 torch 的随机种子,但还是一样的情况。
# 固定随机种子
np.random.seed(1337)
torch.manual_seed(1337)
–最后–
发现问题出现在 X = torch.nn.utils.rnn.pad_sequence(X, batch_first=True) 这条语句,由于样本数据长短不一,处理的时候都会根据样本情况添加 padding ,统一数据维度。
torch.nn.utils.rnn.pad_sequence 会根据样本的最大长度自动添加填充数据来统一数据维度。如果每次测试输入的样本最大长度不一样,填充的长度也会不同,导致最终的计算结果不一样。
解决方法:
使用固定的序列填充长度即可:
max_len = 100 # 应和训练时的样本维度一致
...
X= torch.nn.utils.rnn.pad_sequence(X, batch_first=True)
# 对序列进行截断或填充到指定长度
if X.size(1) < max_len:
X = torch.nn.functional.pad(X, (0, max_len - X.size(1)), value=0)
elif X.size(1) > max_len:
X = X[:, :max_len]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)