SIGIR24-多行为|基于行为模式挖掘的多行为推荐
通过行为模式计算、特征生成、贝叶斯推理评分计算,实现了 多行为推荐 的目标。它结合了用户与物品的交互信息,通过 行为模式路径 和 特征矩阵 的加权计算,为用户生成准确的推荐。

论文来源:SIGIR 2024(短文)
论文链接:https://arxiv.org/pdf/2408.12152
代码链接:https://github.com/rookitkitlee/BPMR.
1 动机
现有的多行为推荐方法可以分为两类:
一类将多种行为交互分解成单独的子图来进行嵌入学习,虽然能通过整合辅助行为的洞察来丰富目标行为的表示,但它们无法有效探索节点间不同行为的交互,编码用户的复杂行为模式,如下图所示。用户𝑢1查看页面𝑖2,然后是另一个用户𝑢2查看同一页面,然后随后购买项目𝑖3。 此序列“ pageview后面进行pageview,然后进行购买”𝑢1和𝑖3之间的序列是一种细微的行为模式
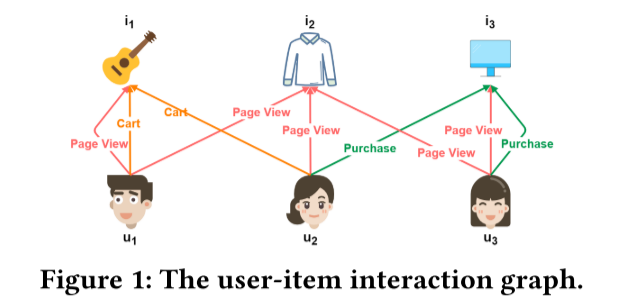
另一类将所有行为统一处理,通过图神经网络进行信息传递,尽管能处理多个行为,但它们混合了当前节点与不同邻居和行为的信息,丧失了特定行为模式的详细特征。
此外,现有多行为推荐依赖图协同过滤方法,但图神经网络的过平滑问题使得无法准确捕捉用户的独特偏好,影响了推荐的准确性。
2 贡献
1:提出了基于行为模式挖掘的多行为推荐模型(BPMR),将多行为推荐任务转化为基于行为模式的预测任务。通过深入挖掘和分析用户与物品之间的行为模式,BPMR 能有效捕捉行为间的潜在依赖关系,解决传统方法中的数据稀疏问题,提高目标行为的推荐精度。
2:将用户交互序列转化为行为模式并应用贝叶斯方法,通过计算行为模式发生的概率并将其应用于推荐中,BPMR 提升了推荐的准确性。这一方法帮助系统准确捕捉用户在不同行为之间的复杂关系(如“页面查看 -> 页面查看 -> 购买”),有效避免了图神经网络中的过平滑问题。
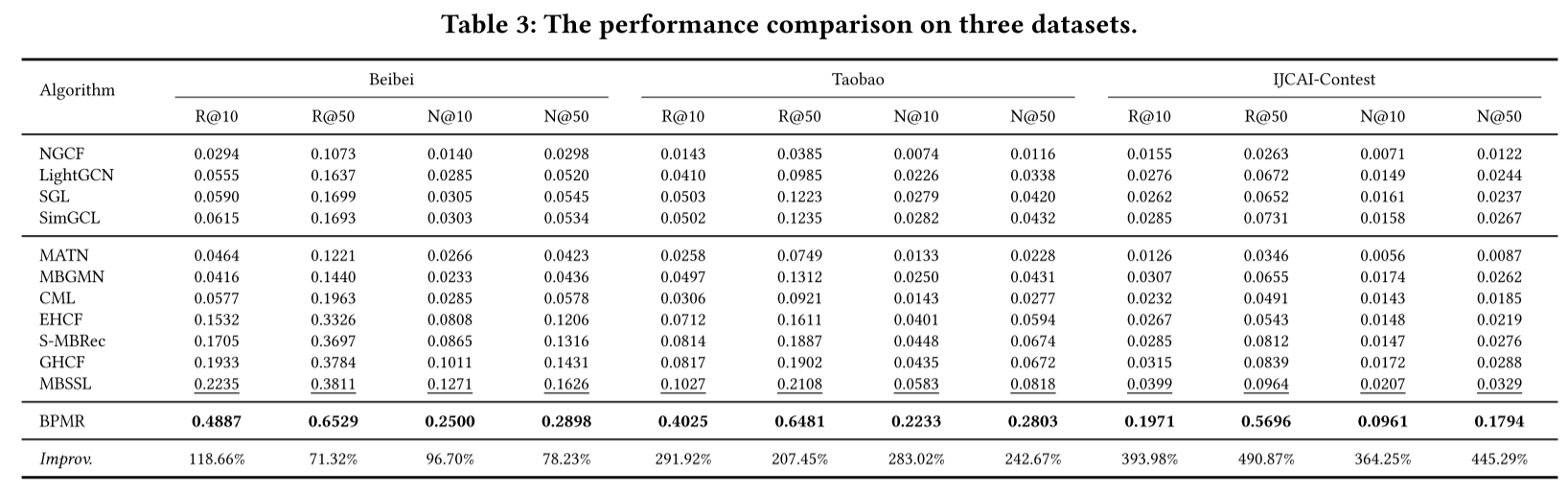
3:性能很棒,MBSSL是23年的SIGIR,我也做了论文阅读和代码阅读的。推荐系统论文阅读总结:SIGIR 2023 Multi-behavior Self-supervised Learning for Recommendation-CSDN博客
3 行为模式挖掘
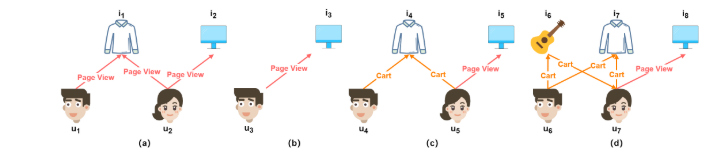
上图说明了用户与项目之间的潜在互动,显示了各种行为下的潜在相互作用及其对理解用户意图的影响。
通过页面视图共享兴趣(a):当用户𝑢1和𝑢2都查看项目𝑖1时,它表示共同的兴趣。 𝑢2的随后的页面视图也可能意味着𝑢1的潜在购买权益,这表明是一种传递的兴趣模式。
直接初步购买意图(b)):通过页面视图与𝑖3的直接相互作用表示直接的初步购买意图,这比图(a)中的推断意图更可靠。
通过购物车动作增强了兴趣相似性(c):𝑢4和𝑢5在其购物车中添加项目𝑖4的动作比单纯的页面视图更强的兴趣相似性,如(a)所示。 因此,当𝑢5查看另一个项目𝑖5时,它也强烈暗示了𝑖4的可能购买意图。
通过多个推车动作加强购买意图(d):当𝑢6和𝑢7在其购物车中有多个共同点时,相似性和可能的购买意图将进一步扩大。 如果𝑢7,则查看项目𝑖8,它会大大提高𝑢6对𝑖8的可能性。
因此这些模式可以可靠地预测未来与目标项目的相互作用,并成为预测基础;这些预测的有效性随观察到的行为模式的长度而变化;不同类型的行为(例如页面视图与购物车动作)对预测精度有明显的影响;行为模式路径的数量在制定准确的目标行为建议中起着至关重要的作用。
通过用户与物品之间的行为模式来预测目标行为。通过这种方式,推荐系统将多行为推荐任务转化为基于行为模式的预测任务。除了目标行为本身不再直接使用目标行为,而是关注通过其他行为模式预测目标行为是否发生。 ![]() 表示算法考虑的所有类型的行为模式,𝛼是所需路径长度的超参数。 采用路径
表示算法考虑的所有类型的行为模式,𝛼是所需路径长度的超参数。 采用路径![]() 的数量,该算法与用户𝑢和项目𝑖作为输入之间的
的数量,该算法与用户𝑢和项目𝑖作为输入之间的![]() 中的行为模式相对应,并且输出是二进制标签
中的行为模式相对应,并且输出是二进制标签
如上图所示,下表中显示了用户𝑢3和项目𝑖1,𝑖2和𝑖3之间的行为模式预测任务的数据:
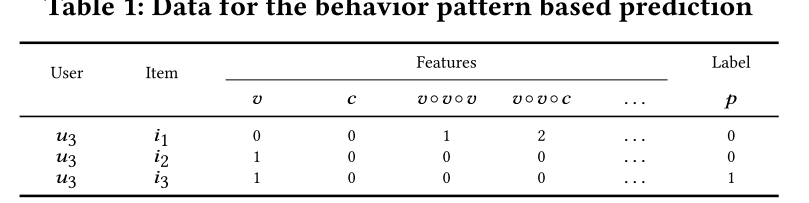
由于𝑢3和𝑖3之间的直接浏览,![]() ,
,![]()
根据上述两条路径,因此 ![]() 通过贝叶斯推理,可以计算一个行为模式路径出现的概率,从而判断目标行为的发生概率。
通过贝叶斯推理,可以计算一个行为模式路径出现的概率,从而判断目标行为的发生概率。
贝叶斯方法:
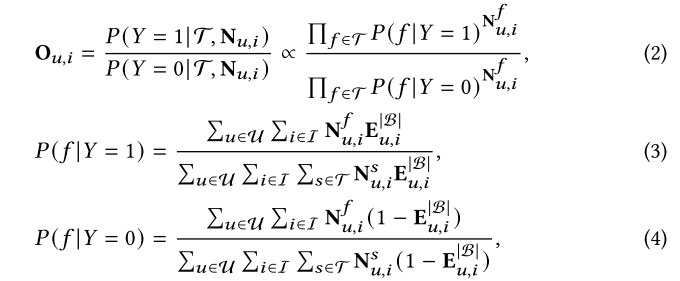
公式 (2) 计算了目标行为为1和0时,行为模式路径出现的概率比率,在给定行为模式集合和路径数量
的情况下,目标行为为1的条件概率。
在给定行为模式集合和路径数量
的情况下,目标行为为0的条件概率。代码在StepTNBZScore.subTask1
if flag == True:
pc[k] = pc[k] + v # 正向样本
else:
nc[k] = nc[k] + v # 负向样本
CH[k] = [PC[i] / (NC[i] + 0.0000001) for i in range(be.get_bs_size())]
bv = bv * (CH[k] ** v) # 使用正负样本比率 (CH) 来调整权重
公式 (3) 和 (4) 给出了条件概率的计算方式:表示用户与物品之间符合行为模式f的路径数量。
用户和物品之间是否发生了目标行为(目标行为发生为1,未发生为0)。最后,基于上述贝叶斯推理计算的比例
,对用户的候选物品进行排序,生成推荐列表。具有更高概率的行为模式路径会导致目标行为发生的可能性更大,从而影响推荐排序。
4 代码
由于短文,论文整个流程还是不大清楚,看着代码大致说一下整个的流程,三个部分:
Step1CreateIIndex-行为模式路径计算
首先初始化索引结构,IIIndex 保存的是用户-物品对之间的交集关系(即不同行为下,用户和物品之间的交集),而 IIIndex_C 保存的是交集的大小(即有多少行为交集)。通过遍历行为和用户-物品交互数据添加索引,并对于每一对用户m和物品n,计算用户m的行为集合和物品n的行为集合之间的交集,最后保存到IIIndex 和 IIIndex_C。
class Step1CreateIIndex:
@staticmethod
def subTask(name, datadir, ie, b1, b2):
if os.path.exists("Data/"+ datadir +"/IIIndex_C_"+name+".pkl"):
return
IIIndex = {}
IIIndex_C = {}
for m in range(len(ie.enum)):
if m % 100 == 1:
print('TaskId: '+str(name)+': ' + str(m)+ '/'+ str(len(ie.enum)))
if m not in b1.iu_index.keys():
continue
for n in range(len(ie.enum)):
if n not in b2.iu_index.keys():
continue
set1 = b1.iu_index[m]
set2 = b2.iu_index[n]
ins = set1.intersection(set2)
if len(ins) > 0:
NumberKit.KeySetAddData(IIIndex, m, n)
NumberKit.KeySetAddDataValue(IIIndex_C, m, n, len(ins))
IOKit.write_pkl("Data/"+ datadir +"/IIIndex_"+name+".pkl", IIIndex)
IOKit.write_pkl("Data/"+ datadir +"/IIIndex_C_"+name+".pkl", IIIndex_C)
@staticmethod
def execute(dataset):
bbs = HandleStepReadData.read_train_test_facade(dataset)
ue, ie = HandleStepCreateEnum.createUserAndItemEnum(bbs)
rbbs = HandleStepRecodeBehavior.recode_behaviors(ue, ie, bbs)
be = BehaviorEnumFactory.createEnumByDataSet(dataset)
base = be.base
behaviors = rbbs[0: len(base)]
ps = []
for i in range(len(base)):
b1 = behaviors[i]
for j in range(len(base)):
b2 = behaviors[j]
name = base[i] + "_" + base[j]
p = multiprocessing.Process(target = Step1CreateIIndex.subTask ,args = (name, dataset, ie, b1, b2))
ps.append(p)
for p in ps:
p.start()
for p in ps:
p.join()
print('end ----------------------------------------------')Step2CreateFeatures-特征计算和归一化
首先遍历用户-物品交互数据,对于每个用户-物品对,它通过检查不同行为类型的交集(如页面浏览、收藏等)来计算特征值。通过行为模式路径的交集大小IIIndex_C加权不同的行为模式,从而生成特征,最大值和最小值用于后续的归一化处理。
class Step2CreateFeatures:
@staticmethod
def subTask(tasks, datadir, base, behaviors, IIIndex, IIIndex_C, ie, be, MAX, MIN):
max = [0.0 for _ in range(be.get_bs_size())]
min = [100.0 for _ in range(be.get_bs_size())]
for taskid, subus in tasks:
if os.path.exists("Data/"+ datadir +"/IN_"+str(taskid)+".pkl"):
continue
result = []
xx = 0
for u1 in subus:
xx = xx + 1
if xx % 20 == 1:
print('TaskId: '+str(taskid)+': ' + str(xx) + '/' + str(len(subus)))
u_result = []
for i1 in range(len(ie.enum)):
i_result = [0 for _ in range(be.get_bs_size())]
for ind in range(len(base)):
id_index = be.get_index(base[ind])
beh = behaviors[ind]
if u1 not in beh.ui_index.keys():
continue
if i1 in beh.ui_index[u1]:
i_result[id_index] = 1
max[id_index] = 1
for ti in range(len(base)):
uiindex = behaviors[ti].ui_index
if u1 not in uiindex.keys():
continue
for tj in range(len(base)):
for tk in range(len(base)):
t_name = base[tk] + "_" + base[tj]
iiindex = IIIndex[t_name]
iiindex_c = IIIndex_C[t_name]
if i1 not in iiindex.keys():
continue
set1 = uiindex[u1]
set2 = iiindex[i1]
ins = set1.intersection(set2)
if len(ins) == 0:
continue
sum = 0
for i2 in ins:
sum = sum + iiindex_c[i1][i2]
xxx = be.get_index((base[ti], base[tj], base[tk]))
i_result[xxx] = sum
if max[xxx] < sum:
max[xxx] = sum
if min[xxx] > sum:
min[xxx] = sum
u_result.append(i_result)
result.append(u_result)
IOKit.write_pkl("Data/"+ datadir +"/IN_"+str(taskid)+".pkl", result)
for i in range(be.get_bs_size()):
if MAX[i] < max[i]:
MAX[i] = max[i]
if MIN[i] > min[i]:
MIN[i] = min[i]
@staticmethod
def execute(dataset, top=None):
bbs = HandleStepReadData.read_train_test_facade(dataset)
ue, ie = HandleStepCreateEnum.createUserAndItemEnum(bbs)
rbbs = HandleStepRecodeBehavior.recode_behaviors(ue, ie, bbs)
be = BehaviorEnumFactory.createEnumByDataSet(dataset)
base = be.base
behaviors = rbbs[0: len(base)]
IIIndex = {}
IIIndex_C = {}
for i in range(len(base)):
for j in range(len(base)):
name = base[i] + "_" + base[j]
index = IOKit.read_pkl("Data/"+ dataset +"/IIIndex_"+name+".pkl")
index_c = IOKit.read_pkl("Data/"+ dataset +"/IIIndex_C_"+name+".pkl")
IIIndex[name] = index
IIIndex_C[name] = index_c
if top == None:
u_len = len(ue.enum)
else:
u_len = top
batch_size = 50
batch = int(u_len / batch_size) + 1
us_totals = [i for i in range(u_len)]
process_total = 20
tasks = [[] for _ in range(process_total)]
for i in range(batch):
us = us_totals[i*batch_size: (i+1)*batch_size]
process_id = i % process_total
tasks[process_id].append((i, us))
# print(tasks)
print('start subtasks')
MAX = Array('f', [0.0 for _ in range(be.get_bs_size())])
MIN = Array('f', [0.0 for _ in range(be.get_bs_size())])
ps = []
for i in range(process_total):
p = multiprocessing.Process(target=Step2CreateFeatures.subTask, args=(
tasks[i], dataset, base, behaviors, IIIndex, IIIndex_C, ie, be, MAX, MIN))
ps.append(p)
for p in ps:
p.start()
for p in ps:
p.join()
max = [MAX[i] for i in range(be.get_bs_size())]
min = [MIN[i] for i in range(be.get_bs_size())]
IOKit.write_pkl("Data/"+ dataset +"/IN_MAX.pkl", max)
IOKit.write_pkl("Data/"+ dataset +"/IN_MIN.pkl", min)StepTNBZScore-贝叶斯标准化和评分计算
首先取用户-物品交互数据以及之前生成的行为模式(IIIndex 和 IIIndex_C)来初始化数据。接着subTask1,就是公式3,4,正负样本计算,对于目标行为发生pc和未发生nc的样本统计每个特征的值,subTask1累积了目标行为发生和未发生的特征信息,这些数据会被用来推断目标行为的概率。
def subTask1(processId, tasks, datadir, MAX, ie, be, PC, NC, LPN, SelectUser, SelectItem):
Sample = [[] for _ in range(be.get_bs_size())]
pc = [0 for _ in range(be.get_bs_size())]
nc = [0 for _ in range(be.get_bs_size())]
lpn = [0, 0]
for taskid, subus in tasks:
print('likehood '+str(taskid))
data = IOKit.read_pkl("Data/" + datadir +
"/IN_"+str(taskid)+".pkl")
for u1 in range(len(subus)):
uid = subus[u1]
for i1 in range(len(ie.enum)):
iid = i1
d = data[u1][i1]
flag_index = be.get_flag_index()
flag = False
if d[flag_index] > 0:
flag = True
lpn[0] = lpn[0] + 1
else:
lpn[1] = lpn[1] + 1
for k in range(be.get_bs_size()):
if k == be.get_flag_index():
continue
v = d[k]
# 求比例 除不除 都一样
# v = v / MAX[k]
if flag == True:
pc[k] = pc[k] + v
else:
nc[k] = nc[k] + v
# 采样算标准差
if uid in SelectUser and iid in SelectItem:
for k in range(be.get_bs_size()):
Sample[k].append(d[k])
for k in range(be.get_bs_size()):
PC[k] = PC[k] + pc[k]
NC[k] = NC[k] + nc[k]
LPN[0] = LPN[0] + lpn[0]
LPN[1] + LPN[1] + lpn[1]
IOKit.write_pkl("Data/" + datadir + "/Sample_"+str(processId)+".pkl", Sample)subTask2计算每个行为特征的后验概率,即每个用户和物品对的推荐评分。首先对每个特征值进行归一化处理,减去均值并除以最大值来规范化特征值(v),然后根据贝叶斯公式bv,基于标准化后的特征数据计算每个行为模式发生的概率。核心是根据目标行为发生与否 正负样本比率(PC 和 NC)来调整各特征的权重,进而得出每个物品的推荐概率。
def subTask2(tasks, datadir, MAX, be, ie, CH, Mean):
for taskid, subus in tasks:
print('posterior '+str(taskid))
data = IOKit.read_pkl("Data/" + datadir + "/IN_"+str(taskid)+".pkl")
R = []
for u1 in range(len(subus)):
r = [0 for _ in range(len(ie.enum))]
for i1 in range(len(ie.enum)):
d = data[u1][i1]
bv = 1.0
for k in range(be.get_bs_size()):
if k == be.get_flag_index():
continue
v = d[k] - Mean[k]
v = v / MAX[k]
bv = bv * (CH[k] ** v)
r[i1] = bv
R.append(r)
IOKit.write_pkl("Data/" + datadir + "/RNBZScore_"+str(taskid)+".pkl", R)流程:首先生成用户和物品之间的生成行为模式路径的数量,计算行为模式的交集。接着,基于用户和物品的交互数据,计算特征矩阵并进行特征归一化处理。最后,贝叶斯推理步骤 中,通过正向样本和负向样本的比率,结合标准化后的特征,计算每个用户-物品对的推荐得分。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)