贝叶斯优化超参数
贝叶斯优化的工作原理是:首先对目标函数的全局行为建立先验知识(通常用高斯过程来表示),然后通过不断地添加样本点观察目标函数在不同输入点的输出,更新这个先验知识,形成后验分布。这个选择的策略通常由所谓的采集函数(Acquisition Function)来定义,比如最常用的期望提升(Expected Improvement),这样,贝叶斯优化不仅可以有效地搜索超参数空间,还能根据已有的知识来引导搜索
机器学习(十五):超参数调优高阶_贝叶斯优化(附代码)_贝叶斯调参优化-CSDN博客
机器学习实践(2.2)LightGBM回归任务-CSDN博客 评论区有具体调参方法,可以和贝叶斯优化结合了,
可视化自动调参工具Optuna在机器学习中的应用:以 XGBoost 回归模型为例
调参是个无穷无尽的过程,适可而止,切误沉溺其中本末倒置,真正决定模型效果上限的还是数据质量
1.ML手动调参
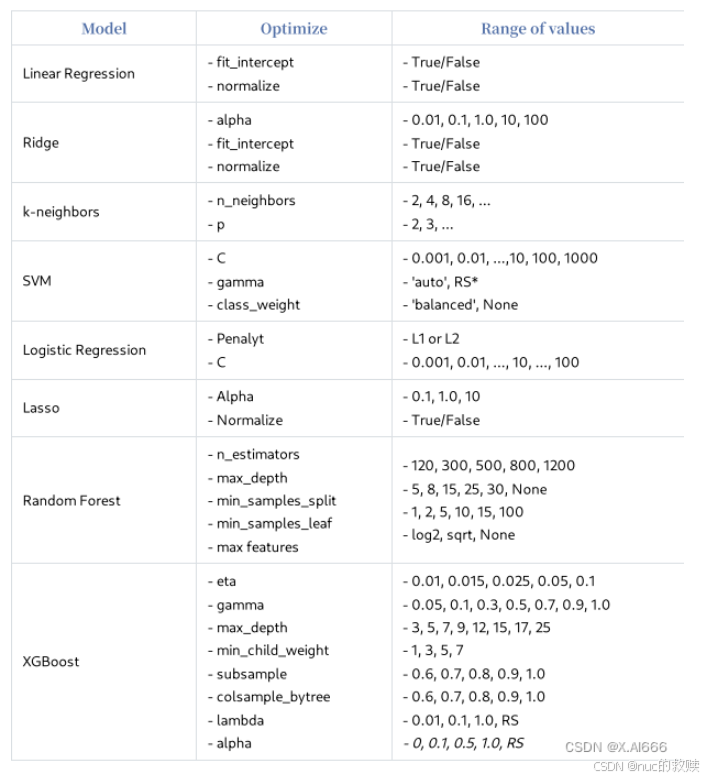
2.介绍
贝叶斯优化被认定是超参数优化的最先进技术。
对于网格搜索、随机搜索,都是对所有点进行验证后再返回最优损失值,导致效率和精度不可兼得。
3.工作原理
贝叶斯优化的工作原理是:首先对目标函数的全局行为建立先验知识(通常用高斯过程来表示),然后通过不断地添加样本点观察目标函数在不同输入点的输出,更新这个先验知识,形成后验分布。基于后验分布,选择下一个采样点,这个选择既要考虑到之前观察到的最优值(即利用),又要考虑到全局尚未探索的区域(即探索)。这个选择的策略通常由所谓的采集函数(Acquisition Function)来定义,比如最常用的期望提升(Expected Improvement),这样,贝叶斯优化不仅可以有效地搜索超参数空间,还能根据已有的知识来引导搜索,避免了大量的无用尝试。
采集函数:平衡探索与利用
采集函数基于代理模型的预测,量化每个候选点的采样价值,指导下一步的试验。常见类型包括:
* 期望提升(Expected Improvement, EI):计算当前最优值改进的期望,优先选择改进潜力大的点
* 置信上界(Upper Confidence Bound, UCB):直接优化均值与不确定性的加权和,参数 β 控制探索程度
* 概率改进(Probability of Improvement, PI):计算新点优于当前最优值的概率,适合快速收敛场景
迭代流程
贝叶斯优化的步骤通常包括:
1. 初始化:随机采样少量初始点,构建初始代理模型 。 (先建立先验知识)
2. 循环迭代:
* 选择采样点:通过最大化采集函数确定下一个试验点。
* 评估目标函数:计算更新数据集 。
* 更新代理模型:基于新数据重新拟合高斯过程 。
3. 终止条件:达到预设迭代次数或收敛阈值后,返回最优解 。
4.贝叶斯优化与常规的网格搜索或者随机搜索的区别是:
贝叶斯调参采用高斯过程,考虑之前的参数信息,不断地更新先验;网格搜索未考虑之前的参数信息
贝叶斯调参迭代次数少,速度快;网格搜索速度慢,参数多时易导致维度爆炸
贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部最优
贝叶斯优化提供了一个优雅的框架来尽可能少的步骤中找到全局最小值。
5.总结
开发:力求在代用模型预测的目标好的地方采样。这就是利用已知的有希望的点。但是,如果我们已经对某一区域进行了足够的探索,那么不断地利用已知的信息就不会有什么收获。
探索:力求在不确定性较高的地点进行采样。这就确保了空间的任何主要区域都不会未被探索–全局最小值可能恰好就在那里。
6.贝叶斯优化就是把概率论的思想放在代入优化的思想后面。综上所述:
· 代用优化利用代用函数或近似函数通过抽样来估计目标函数。
· 贝叶斯优化将代用优化置于概率框架中,将代用函数表示为概率分布,可以根据新的信息进行更新。
· 获取函数用于评估在当前已知的先验条件下,探索空间中某一点会产生 “好 “收益的概率,平衡探索与开发
· 主要在目标函数评估成本很高的时候使用贝叶斯优化,常用于超参数调整。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)