如何在服务器上并行化快速下载VFHQ数据集?A High-Quality Dataset and Benchmark for Video Face Super Resolution
·
目录
前言
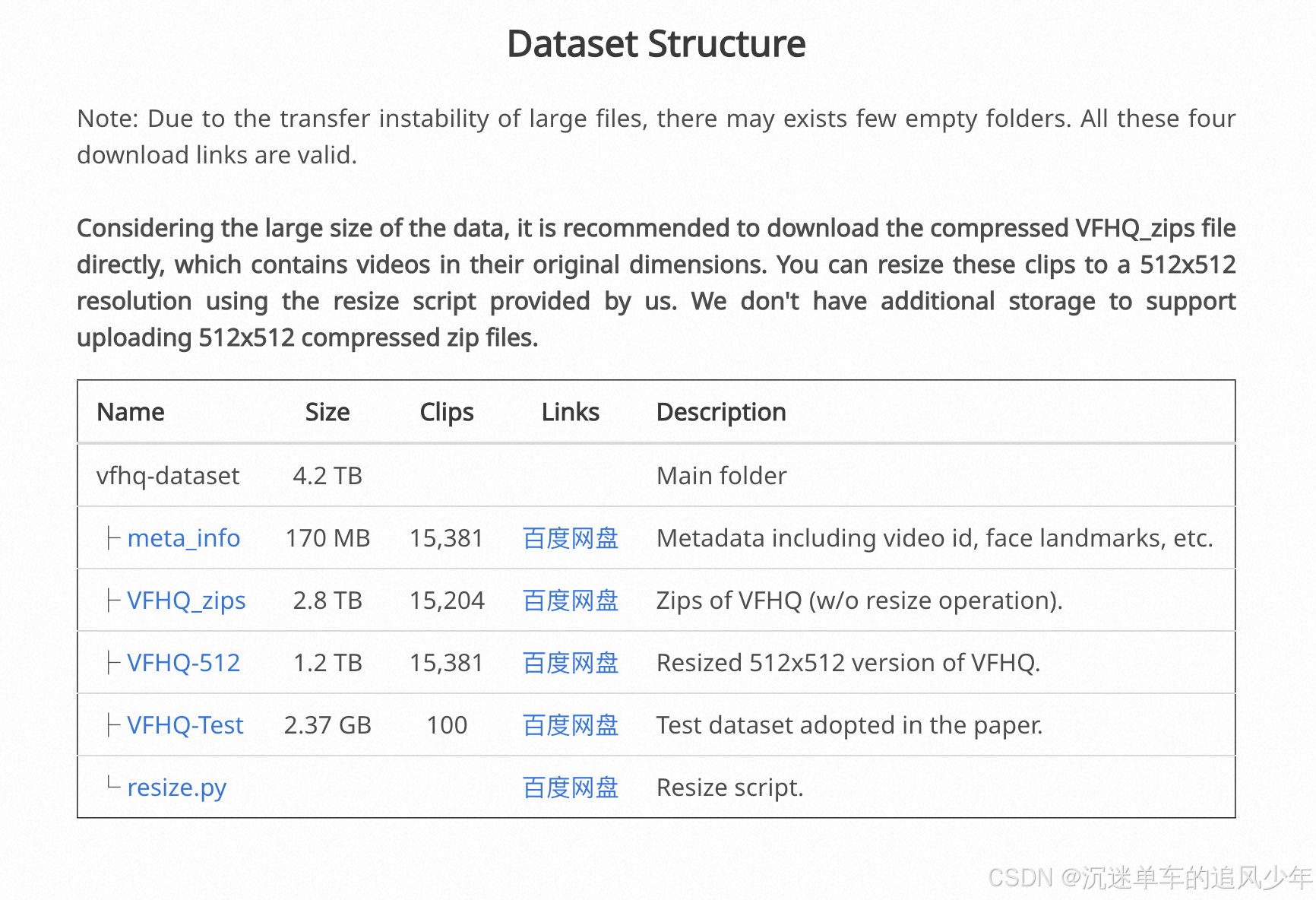
虽然VFHQ是一个2022年的工作,但是数据集的质量非常高,导致三年过去了还是非常好用。
那时候huggingface还没有流行,所以并没有托管到huggingface上,导致现在非常难快速下载。
这篇博客提供一种并行化快速下载的方法,能够快速下载这个超大数据集。
单个压缩文件下载
首先进入官网:VFHQ
然后找到你想要的链接:
然后开通一个百度网盘SVIP,否则无法保存这么大的文件到自己的文件夹中。
保存完按照我之前博客中提供的方法下载这些文件:
并行化加速
这里一共有好几百个压缩文件,逐个下载很不现实,所以我提供了一个并行化下载的脚本,实测在1小时内就能完成所有数据的下载。
#!/bin/bash
# 定义函数用于下载单个文件
download_file() {
local index=$1
echo "Starting download for group${index}.zip"
bypy downfile VFHQ_zips/group"${index}".zip
echo "Finished download for group${index}.zip"
}
export -f download_file # 导出函数,使得parallel可以访问
# 使用GNU Parallel进行并发下载
# --jobs 选项设置并发任务数,这里设置为10作为示例
# seq 100 422 生成从100到422的数字序列
parallel --jobs 322 download_file ::: $(seq 100 422)
echo "All downloads have been started."
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)