Transformer学习与基础实验4——英汉翻译(2. 模型构建、训练、推理)
Transformer学习与基础实验系列文章的第4篇,基于自定义实现的Transformer模型的英汉翻译任务训练、推理等过程记录和代码理解,以及所有源码、模型结构图绘制文件的原件提供
模型训练准备工作
1. 实例化训练集和模型
# 添加系统路径
import sys
sys.path.append('xxxxx/transformer_learning/pytorch_version/transformers_network')
sys.path.append('xxxxxx/transformer_learning/pytorch_version')
from text2text.datasetProcess import CmnTranslationDataset, datasets, DataLoader, src_vocab, trg_vocab
from transformers_network.decoder import Decoder
from transformers_network.encoder import Encoder
from transformers_network.transformer import Transformer
# super parameters
batch_size = 64
max_len = 50 # the maximum length of the longest sentence in the dataset
d_model = 512
d_ff = 2048
n_layers = 6
n_heads = 8
# 实例化数据集
translation_dataset = CmnTranslationDataset(datasets, src_vocab, trg_vocab, max_len=max_len)
# 创建DataLoader实例
trained_dataloader = DataLoader(translation_dataset, batch_size=batch_size, shuffle=True)
""" 实例化模型。
"""
src_vocab_size = len(src_vocab)
trg_vocab_size = len(trg_vocab)
src_pad_idx = src_vocab.pad_idx
trg_pad_idx = trg_vocab.pad_idx
encoder = Encoder(src_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
decoder = Decoder(trg_vocab_size, d_model, n_heads, d_ff, n_layers, dropout_p=0.1)
model = Transformer(encoder, decoder)
2. 定义损失函数、优化器
损失函数:
定义如何计算模型输出(logits)与目标(targets)之间的误差,这里可以使用交叉熵损失(CrossEntropyLoss)
提出疑问Q1:交叉熵损失函数作为多分类模型常用的损失函数,为什么能用在这里的机器翻译任务中?
优化器:
AI框架(如pytorch)将模型优化算法的实现称为优化器。优化器内部定义了模型的参数优化过程(即梯度如何更新至模型参数),所有优化逻辑都封装在优化器对象中,这里使用Adam优化算法。
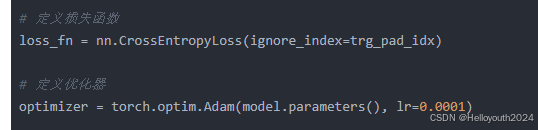
提出疑问Q2:nn.CrossEntropyLoss 的 ignore_index参数在具体损失计算中如何发挥作用?
3. 函数封装训练过程
在训练过程中,表示句子结尾的占位符<eos>应是被模型预测出来,而不是作为模型的输入,其实更准确的说,应该是需要和目标序列前后错开一个token,如 【Transformer学习与基础实验2——Transformer结构】中所提到的:

所以在将数据集中的目标序列作为 Decoder 的输入前,需要移除目标序列最末的token,因为每个单词的预测是根据目前的”翻译情况“结合源序列的信息生成的(根据前面预测后面),举例说明:
数据集的目标序列:
trg = [, x_1, x_2, ..., x_n, eos]
Decoder的输入之一(query向量):
trg[:-1] = [, x_1, x_2, ..., x_n]
其中,x_i代表目标序列中第i个表示实际内容的词元。
pytorch代码:
import torch
from torch import nn
from tqdm import tqdm
import os
from get_dataset2model import trained_dataloader, src_pad_idx, trg_pad_idx, model
# 定义损失函数
loss_fn = nn.CrossEntropyLoss(ignore_index=trg_pad_idx)
# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 定义前向网络计算逻辑
def forward(src, trg):
"""前向网络"""
trg_input = trg[:, :-1] # 去除目标序列最末的 token词元
trg_target = trg[:, 1:] # 去除目标序列的句首 <bos> 占位符
logits, _, _, _ = model(src, trg_input, src_pad_idx, trg_pad_idx) # logits: [batch_size * trg_len, trg_vocab_size]
loss = loss_fn(logits, trg_target.reshape(-1))
return loss
# 定义训练一个step的逻辑
def train_step(src, trg):
optimizer.zero_grad() # 清空梯度
loss = forward(src, trg)
loss.backward() # 反向传播
optimizer.step() # 更新参数
return loss.item()
# 定义整体训练逻辑
def train(model, iterator, epoch=0):
model = model.to(device)
model.train() # 设置模型为训练模式
total_loss = 0
num_batches = len(iterator)
with tqdm(total=num_batches, desc=f'Epoch {epoch}') as t:
for batch in iterator:
src, trg = batch['src_indexes'], batch['tgt_indexes']
src = src.to(device)
trg = trg.to(device)
loss = train_step(src, trg)
total_loss += loss
t.set_postfix({'loss': f'{loss:.2f}'})
t.update(1)
return total_loss / num_batches模型训练
最后就是指定训练迭代的epochs,然后进行循环训练了,记得保存训练得到的模型参数。
if __name__ == '__main__':
num_epochs = 10
best_valid_loss = float('inf')
for i in range(num_epochs):
train_loss = train(model, trained_dataloader, i)
# valid_loss = evaluate(valid_dataloader)
# if valid_loss < best_valid_loss:
# best_valid_loss = valid_loss
# 使用torch.save保存模型的参数
dir = os.path.dirname(__file__)
model_path = os.path.join(dir, 'transformer_en2cn.pth')
torch.save(model.state_dict(), model_path)本文的训练过程:

共训练10个epochs,模型在训练集的平均loss从最开始的3.71到最后的0.73.
模型推理
推理预测流程图
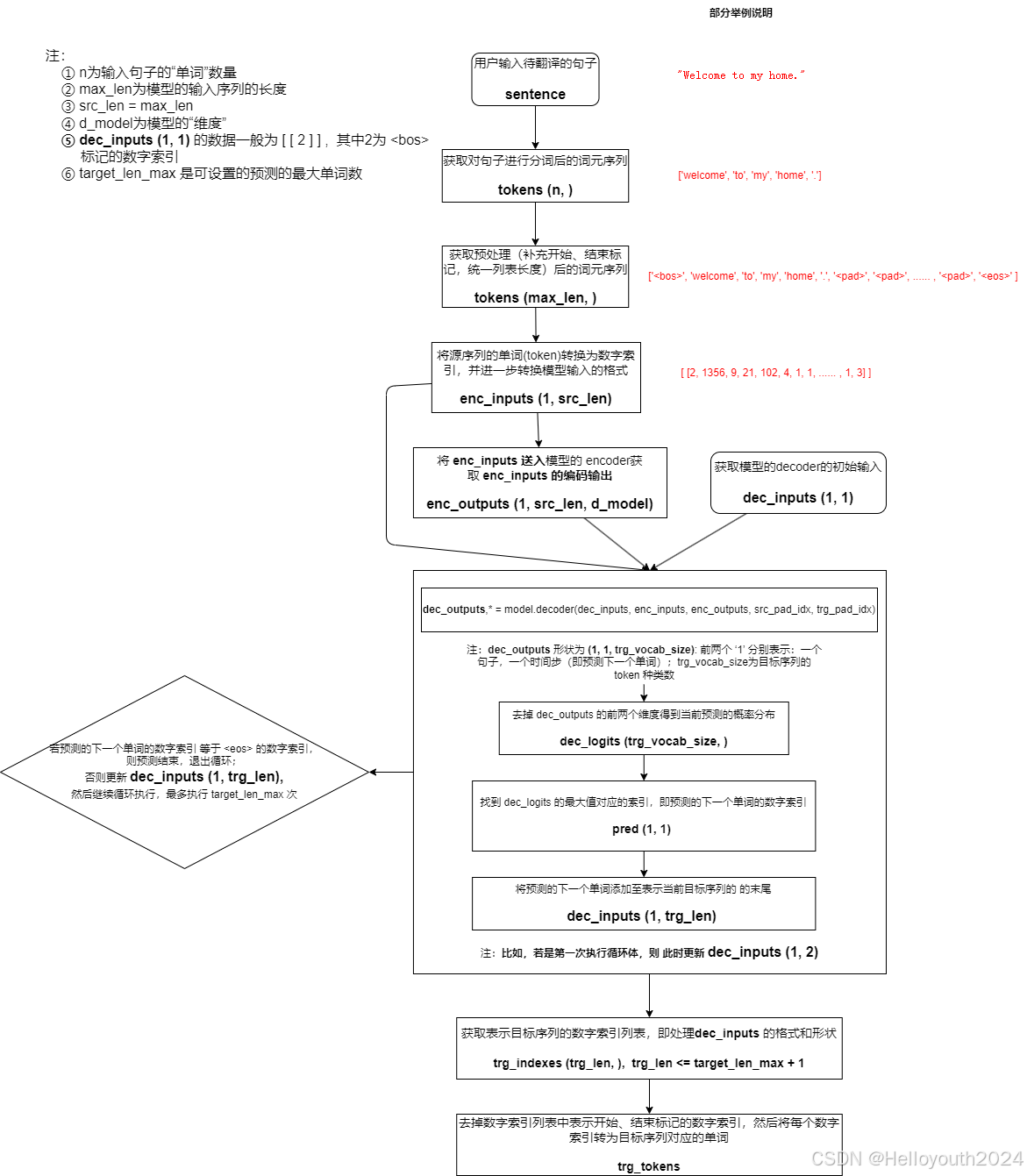
代码实现(代码进行了一点优化,可能和上述流程图不完全一致,但基本过程符合):
import re
from get_dataset2model import src_pad_idx, trg_pad_idx, model, max_len, src_vocab, trg_vocab
from datas_preProcess import en_tokenize_op
import torch
# 加载检查点
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
checkpoint_path = "xxxxxx/torch_areas/cache/transformer_en2cn.pth"
checkpoint = torch.load(checkpoint_path, map_location=device)
model.load_state_dict(checkpoint)
model.eval()
"""
我们输入一个英文语句,期望可以返回翻译好的中文语句。
首先通过Encoder提取英文序列中的特征信息,并将这些特征信息传输至Decoder。
Decoder最开始的输入为起始占位符 < bos >,每次会根据输入预测下一个出现的单词,并对输入进行更新,直到预测出终止占位符 < eos > 或者达到指定的长度。
"""
def inference(sentence, max_len=max_len, target_len_max: int = None):
"""模型推理:输入一个英文句子,输出翻译后的中文句子
enc_inputs: [batch_size(1), src_len]
"""
# 对输入句子进行分词
tokens = en_tokenize_op(sentence)
n = len(tokens) # 输入句子的“单词”的个数
# 补充起始、终止占位符,统一序列长度
if len(tokens) > max_len - 2:
src_len = max_len
tokens = ['<bos>'] + tokens[:max_len - 2] + ['<eos>']
else:
src_len = len(tokens) + 2
# tokens = ['<bos>'] + tokens + ['<eos>'] + ['<pad>'] * (max_len - src_len)
tokens = ['<bos>'] + tokens + ['<pad>'] * (max_len - src_len) + ['<eos>']
# 将源语言的单词转换为数字索引,并进一步转换为tensor
# enc_inputs: [1, src_len]
indexes = src_vocab.encode(tokens)
enc_inputs = torch.tensor(indexes, dtype=torch.long).reshape(1, -1)
# 将输入送入encoder,获取信息
enc_outputs, _ = model.encoder(enc_inputs, src_pad_idx)
dec_inputs = torch.tensor([[src_vocab.bos_idx]], dtype=torch.long)
# 初始化decoder输入,此时仅有句首占位符<pad>,即 dec_inputs: [1, 1]
if target_len_max is None:
target_len_max = n + 3
for _ in range(target_len_max):
dec_outputs, _, _ = model.decoder(dec_inputs, enc_inputs, enc_outputs, src_pad_idx, trg_pad_idx)
dec_logits = dec_outputs.view((-1, dec_outputs.shape[-1]))
# 找到下一个词的概率分布,并输出预测
dec_logits = dec_logits[-1, :]
pred = dec_logits.argmax(axis=0)
# 如果出现<eos>,则终止继续预测
if int(pred.numpy()) == trg_vocab.eos_idx:
break
pred = pred.to(torch.long).reshape(1, -1)
# 更新dec_inputs
dec_inputs = torch.concat((dec_inputs, pred), axis=1)
# 最后需要将数字索引转换为英文单词
trg_indexes = dec_inputs.reshape(-1).tolist()
trg_indexes = trg_indexes[1:] # 去掉起始符号, 因为没有终止符号(上述循环遇到终止符就退出预测了), 所以不用去掉
trg_tokens = trg_vocab.decode(trg_indexes)
return trg_tokens
src_sentence = "Welcome to my home."
pred_trg = inference(src_sentence)
print(f'src: {src_sentence}')
print(f"predicted trg: {pred_trg}")
src_sentence = "What is your plans of year 2025 ?"
pred_trg = inference(src_sentence)
print(f'src: {src_sentence}')
print(f"predicted trg: {pred_trg}")
# while True:
# src_sentence = input("input src sentence: ")
# if src_sentence == 'exit':
# print("Program exit.")
# break
# pred_trg = inference(src_sentence)
# print(f"predicted trg = {pred_trg}")
这里提供本文训练好的模型参数权重字典保存的文件,可以自行下载直接进行翻译推理。
基于自定义实现的Transformer模型的英汉翻译任务训练得到的模型参数权重字典
(这里好像自动被设置为VIP资源了且无法更改,本来想设置免费被下载的,这里提供另外的下载途径:https://pan.baidu.com/s/1nqhOKPW3-0tMzeHdlh1CbQ?pwd=wkbk, 提取码: wkbk)
输出:

翻译效果直观上还是不错的,由于目标序列语料库本身没有太多数字token,这里的2025年并没有翻译过来的,但也能接受。transformer模型(Encoder-Decoder架构)对text to text类的任务是很合适的,表现出强大的表示能力,后续可以试试其它序列到序列的任务,一般只需对代码部分的数据处理部分进行适当的修改即可。
关注微信公众号——分享之心,后台回复:Transformer,获取该系列实验的所有源码(包含mindspore和pytorch两个框架的版本)、文档、模型结构图(部分帮助理解的流程图)文件(.drawio文件、PPT文件)。
注:对于源码,部分源文件中的“通过sys模块添加系统路径使得可以正确加载自定义的模块”部分需要根据实际运行机器的路径进行修改,本地安装好第三方依赖包(如pytorch、jieba等)后可以直接运行。

分享之心公众号二维码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)