YOLOv5训练自己的模型并用c++部署mnn框架使用
YOLOv5训练自己的模型并部署mnn框架使用
·
基本思想:YOLOv5训练自己的模型并部署mnn框架使用
前言
YOLOv5选择5.0的版本
一、下载源码
ubuntu@ubuntu:~$ wget https://github.com/ultralytics/yolov5/archive/refs/tags/v5.0.zip1.1 下载功能包
ubuntu@ubuntu:~$ cd yolov5-5.0/
ubuntu@ubuntu:~/yolov5-5.0$ pip install -r requirements.txt二、测试模型
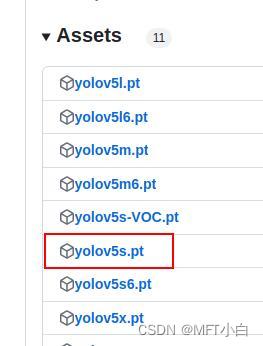
下载对应版本模型 yolov5s.pt
ubuntu@ubuntu:~$ cd yolov5-5.0/
ubuntu@ubuntu:~/yolov5-5.0$ python detect.py --weights yolov5s.pt --source data/images/bus.jpg
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.25, device='', exist_ok=False, img_size=640, iou_thres=0.45, name='exp', nosave=False, project='runs/detect', save_conf=False, save_txt=False, source='data/images/bus.jpg', update=False, view_img=False, weights=['yolov5s.pt'])
YOLOv5 🚀 2021-4-12 torch 1.9.0+cu111 CUDA:0 (NVIDIA GeForce RTX 3050, 7965.25MB)
Fusing layers...
/home/ubuntu/.local/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS
image 1/1 /home/ubuntu/yolov5-5.0/data/images/bus.jpg: 640x480 4 persons, 1 bus, 1 fire hydrant, Done. (0.012s)
Results saved to runs/detect/exp
Done. (0.042s) 

三、创建数据集
3.1 新建文件夹
ubuntu@ubuntu:~/yolov5-5.0$ mkdir -p datasets
ubuntu@ubuntu:~/yolov5-5.0$ cd datasets/
ubuntu@ubuntu:~/yolov5-5.0/datasets$ mkdir -p VOCdevkit
ubuntu@ubuntu:~/yolov5-5.0/datasets$ cd VOCdevkit/
ubuntu@ubuntu:~/yolov5-5.0/datasets/VOCdevkit$ mkdir -p VOC2007
ubuntu@ubuntu:~/yolov5-5.0/datasets/VOCdevkit$ cd VOC2007/
ubuntu@ubuntu:~/yolov5-5.0/datasets/VOCdevkit/VOC2007$ mkdir -p Annotations
ubuntu@ubuntu:~/yolov5-5.0/datasets/VOCdevkit/VOC2007$ mkdir -p JPEGImages3.2 文件结构
ubuntu@ubuntu:~/yolov5/yolov5-5.0/datasets$ tree -L 3
. # datasets 数据集一级目录
└── VOCdevkit # 数据集二级目录
└── VOC2007 # 数据集三级目录
├── Annotations # 存放标注好的xml文件
└── JPEGImages # 存放对应xml文件的jpg图片
4 directories, 0 files
3.3 转换VOC数据集格式,划分数据集
xml2voc.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes = ["code"] ##这里要写好标签对应的类
# classes=["ball"]
TRAIN_RATIO = 80 #表示将数据集划分为训练集和验证集,按照2:8比例来的
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('/home/ubuntu/yolov5/yolov5-5.0/datasets/VOCdevkit/VOC2007/Annotations/%s.xml' % image_id)
out_file = open('/home/ubuntu/yolov5/yolov5-5.0/datasets/VOCdevkit/VOC2007/YOLOLabels/%s.txt' % image_id, 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "/home/ubuntu/yolov5-5.0/datasets/VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "/home/ubuntu/yolov5-5.0/datasets/VOCdevkit/VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "/home/ubuntu/yolov5-5.0/datasets/VOCdevkit/VOC2007/Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "/home/ubuntu/yolov5/yolov5-5.0/datasets/VOCdevkit/VOC2007/JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "/home/ubuntu/yolov5-5.0/datasets/VOCdevkit/VOC2007/YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0, len(list_imgs)):
path = os.path.join(image_dir, list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if (prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
3.4 转换之后的文件结构
ubuntu@ubuntu:~/yolov5/yolov5-5.0/datasets$ tree -L 3
.
└── VOCdevkit
├── images # 新生成文件夹
│ ├── train # 训练集jpg图片
│ └── val # 验证集jpg图片
├── labels # 新生成文件夹
│ ├── train # 训练集标注txt文件
│ └── val # 验证集标注txt文件
└── VOC2007
├── Annotations
├── JPEGImages
└── YOLOLabels # 新生成文件夹,存放转voc格式文件
11 directories, 0 files四、训练模型
4.1 修改data配置文件 tarinData.yaml
ubuntu@ubuntu:~/yolov5-5.0$ cd data
ubuntu@ubuntu:~/yolov5-5.0/data$ cp coco.yaml tarinData.yaml修改一下tarinData.yaml
# COCO 2017 dataset http://cocodataset.org
# Train command: python train.py --data coco.yaml
# Default dataset location is next to /yolov5:
# /parent_folder
# /coco
# /yolov5
# download command/URL (optional)
# download: bash data/scripts/get_coco.sh
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /home/ubuntu/yolov5-5.0/datasets/VOCdevkit/images/train/ # 118287 images
val: /home/ubuntu/yolov5-5.0/datasets/VOCdevkit/images/val/ # 5000 images
# test: ../coco/test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 1
# class names
names: ['code']
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
4.2 修改model配置文件 yolov5s_self.yaml
ubuntu@ubuntu:~/yolov5-5.0$ cd models/
ubuntu@ubuntu:~/yolov5-5.0/models$ cp yolov5s.yaml yolov5s_self.yaml修改一下yolov5s_self.yaml
# parameters
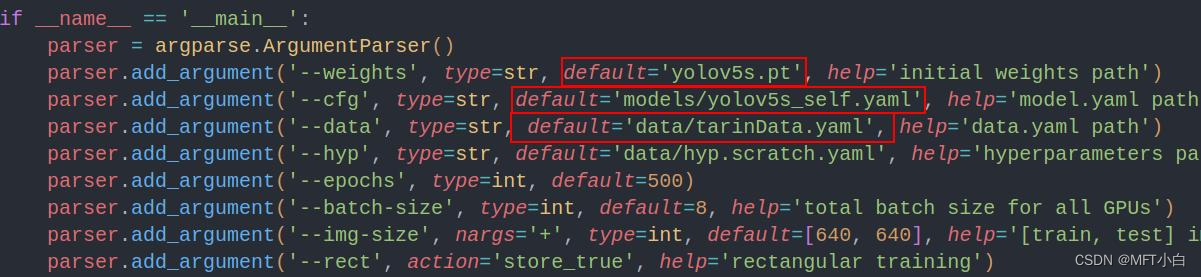
nc: 1 # number of classes4.3 修改train.py
4.4 开始训练
ubuntu@ubuntu:~/yolov5/yolov5-5.0$ python train.py --device "0" Epoch gpu_mem box obj cls total labels img_size
0/499 0.35G 0.1139 0.02577 0 0.1397 14 640: 100%|████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:06<00:00, 2.16it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.54it/s]
all 13 13 0.0117 0.0769 0.00234 0.000628
Epoch gpu_mem box obj cls total labels img_size
1/499 1.87G 0.1037 0.02539 0 0.1291 11 640: 100%|████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 7.85it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4.29it/s]
all 13 13 0.0249 0.0769 0.00723 0.00094
Epoch gpu_mem box obj cls total labels img_size
2/499 2.1G 0.09326 0.02571 0 0.119 12 640: 100%|████████████████████████████████████████████████████████████████████████████████████| 13/13 [00:01<00:00, 7.05it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 3.20it/s]
all 13 13 0.0144 0.615 0.0106 0.00286
4.5 训练中遇到的问题
问题一:提示common.py文件缺少SPPF函数
AttributeError: Can't get attribute 'SPPF' on <module 'models.common' from '/home/ubuntu/yolov5/yolov5-5.0/models/common.py'>问题分析:一是是因为yolov5-5.0版本之后才有的SPPF函数;二是每次训练会下载新版本,不对应。
问题解决:所以要将对应版本的yolov5s.pt权重放到weights文件夹下,并且也要在上衣目录放置一个。这样每次训练模型不会自动下载新版本的预训练权重。
问题二:
RuntimeError: result type Float can‘t be cast to the desired output type long int问题解决参考此处:
修改一:
在 \utils\loss.py 文件中查找 indices.append 找到如下内容:
原始内容:
for in range(self.nl):
anchors = self.anchors[i] #将这一行进行更改
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain修改后:
for in range(self.nl):
anchors, shape = self.anchors[i], p[i].shape # 改成这样
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain修改二:
在 \utils\loss.py 文件中查找 indices.append 找到如下内容:
原始内容:
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices # 将这一行进行修改
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box修改后:
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid # 修改成这样
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
五、转换模型
5.1 pt转onnx
python models/export.py --weights weights/yolov5s.pt --img 640 --batch 1 --device 0ubuntu@ubuntu:~/yolov5/yolov5-5.0$ python models/export.py --weights weights/yolov5s.pt --img 640 --batch 1 --device 0
Namespace(batch_size=1, device='0', dynamic=False, grid=False, img_size=[640, 640], weights='weights/yolov5s.pt')
YOLOv5 🚀 2021-4-12 torch 1.9.0+cu111 CUDA:0 (NVIDIA GeForce RTX 3050, 7965.25MB)
Fusing layers...
/home/ubuntu/.local/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Model Summary: 224 layers, 7266973 parameters, 0 gradients, 17.0 GFLOPS
Starting TorchScript export with torch 1.9.0+cu111...
/home/ubuntu/.local/lib/python3.8/site-packages/torch/jit/_trace.py:952: TracerWarning: Encountering a list at the output of the tracer might cause the trace to be incorrect, this is only valid if the container structure does not change based on the module's inputs. Consider using a constant container instead (e.g. for `list`, use a `tuple` instead. for `dict`, use a `NamedTuple` instead). If you absolutely need this and know the side effects, pass strict=False to trace() to allow this behavior.
module._c._create_method_from_trace(
TorchScript export success, saved as weights/yolov5s.torchscript.pt
Starting ONNX export with onnx 1.14.0...
ONNX export success, saved as weights/yolov5s.onnx5.2 简化onnx模型
ubuntu@ubuntu:~/yolov5-5.0$ python -m onnxsim yolov5s.onnx yolov5s-sim.onnxubuntu@ubuntu:~/yolov5-5.0$ python -m onnxsim yolov5s.onnx yolov5s-sim.onnx
Simplifying...
Finish! Here is the difference:
┏━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━┓
┃ ┃ Original Model ┃ Simplified Model ┃
┡━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━┩
│ Add │ 7 │ 7 │
│ Concat │ 17 │ 14 │
│ Constant │ 175 │ 136 │
│ Conv │ 62 │ 62 │
│ Gather │ 9 │ 0 │
│ MaxPool │ 3 │ 3 │
│ Mul │ 59 │ 59 │
│ Reshape │ 3 │ 3 │
│ Resize │ 2 │ 2 │
│ Shape │ 9 │ 0 │
│ Sigmoid │ 59 │ 59 │
│ Slice │ 8 │ 4 │
│ Transpose │ 3 │ 3 │
│ Unsqueeze │ 9 │ 0 │
│ Model Size │ 27.7MiB │ 27.7MiB │
└────────────┴────────────────┴──────────────────┘5.3 onnx转mnn
修改配置文件
ubuntu@ubuntu:~/MNN$ sudo gedit CMakeLists.txt 设置convert工具为ON
option(MNN_BUILD_CONVERTER "Build Converter" ON)ubuntu@ubuntu:~/MNN/build$ ./MNNConvert -f ONNX --modelFile /home/ubuntu/yolov5-5.0/yolov5s-sim.onnx --MNNModel /home/ubuntu/yolov5-5.0/yolov5s-sim.mnn --bizCode MNNubuntu@ubuntu:~/MNN/build$ ./MNNConvert -f ONNX --modelFile /home/ubuntu/yolov5-5.0/yolov5s-sim.onnx --MNNModel /home/ubuntu/yolov5-5.0/yolov5s-sim.mnn --bizCode MNN
The device support i8sdot:0, support fp16:0, support i8mm: 0
Start to Convert Other Model Format To MNN Model...
[14:03:36] /home/ubuntu/MNN/tools/converter/source/onnx/onnxConverter.cpp:98: ONNX Model ir version: 6
[14:03:36] /home/ubuntu/MNN/tools/converter/source/onnx/onnxConverter.cpp:99: ONNX Model opset version: 12
Start to Optimize the MNN Net...
inputTensors : [ images, ]
outputTensors: [ 417, 437, output, ]
Converted Success!六、c++部署mnn
CMakeLists.txt
cmake_minimum_required(VERSION 3.16)
project(yolov5_mnn)
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_FLAGS "-std=c++11")
set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fopenmp")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fopenmp")
#添加头文件
include_directories(${CMAKE_SOURCE_DIR})
include_directories(${CMAKE_SOURCE_DIR}/include)
#include_directories(${CMAKE_SOURCE_DIR}/include/ncnn)
include_directories(${CMAKE_SOURCE_DIR}/include/MNN)
find_package(OpenCV REQUIRED)
include_directories(${OpenCV_INCLUDE_DIRS})
add_library(libmnn SHARED IMPORTED)
#set_target_properties(libncnn PROPERTIES IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/libncnn.so)
set_target_properties(libmnn PROPERTIES IMPORTED_LOCATION ${CMAKE_SOURCE_DIR}/lib/libMNN.so)
aux_source_directory(${CMAKE_SOURCE_DIR}/src SRC_LIST)
add_executable(yolov5_mnn main.cpp ${SRC_LIST})
target_link_libraries(yolov5_mnn ${OpenCV_LIBS}
# libncnn
libmnn)main.cpp
#include <iostream>
#include <string>
#include <MNN/MNNDefine.h>
#include <MNN/MNNForwardType.h>
#include <MNN/Interpreter.hpp>
#include <opencv2/opencv.hpp>
#include "Yolo.h"
void show_shape(std::vector<int> shape)
{
std::cout<<shape[0]<<" "<<shape[1]<<" "<<shape[2]<<" "<<shape[3]<<" "<<shape[4]<<" "<<std::endl;
}
void scale_coords(std::vector<BoxInfo> &boxes, int w_from, int h_from, int w_to, int h_to)
{
float w_ratio = float(w_to)/float(w_from);
float h_ratio = float(h_to)/float(h_from);
for(auto &box: boxes)
{
box.x1 *= w_ratio;
box.x2 *= w_ratio;
box.y1 *= h_ratio;
box.y2 *= h_ratio;
}
return ;
}
cv::Mat draw_box(cv::Mat & cv_mat, std::vector<BoxInfo> &boxes, const std::vector<std::string> &labels)
{
int CNUM = 80;
cv::RNG rng(0xFFFFFFFF);
cv::Scalar_<int> randColor[CNUM];
for (int i = 0; i < CNUM; i++)
rng.fill(randColor[i], cv::RNG::UNIFORM, 0, 256);
for(auto box : boxes)
{
int width = box.x2-box.x1;
int height = box.y2-box.y1;
int id = box.id;
cv::Point p = cv::Point(box.x1, box.y1);
cv::Rect rect = cv::Rect(box.x1, box.y1, width, height);
cv::rectangle(cv_mat, rect, randColor[box.label]);
string text = labels[box.label] + ":" + std::to_string(box.score) + " ID:" + std::to_string(id);
cv::putText(cv_mat, text, p, cv::FONT_HERSHEY_PLAIN, 1, randColor[box.label]);
}
return cv_mat;
}
int main()
{
#if 1
std::string model_name = "../model/yolov5s-sim.mnn";
int num_classes=80;
std::vector<YoloLayerData> yolov5s_layers{
{"437", 32, {{116, 90}, {156, 198}, {373, 326}}},
{"417", 16, {{30, 61}, {62, 45}, {59, 119}}},
{"output", 8, {{10, 13}, {16, 30}, {33, 23}}},
};
std::vector<YoloLayerData> & layers = yolov5s_layers;
std::vector<std::string> labels{"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush"};
#else
std::string model_name = "checkpoints/yolov5ss.mnn";
int num_classes=5;
std::vector<YoloLayerData> yolov5ss_layers{
{"415", 32, {{116, 90}, {156, 198}, {373, 326}}},
{"395", 16, {{30, 61}, {62, 45}, {59, 119}}},
{"output", 8, {{10, 13}, {16, 30}, {33, 23}}},
};
std::vector<YoloLayerData> & layers = yolov5ss_layers;
//std::vector<std::string> labels{"person", "vehicle", "outdoor", "animal", "accessory"};
#endif
int net_size =640;
// auto revertor = std::unique_ptr<Revert>(new Revert(model_name.c_str()));
// revertor->initialize();
// auto modelBuffer = revertor->getBuffer();
// const auto bufferSize = revertor->getBufferSize();
// auto net = std::shared_ptr<MNN::Interpreter>(MNN::Interpreter::createFromBuffer(modelBuffer, bufferSize));
// revertor.reset();
std::shared_ptr<MNN::Interpreter> net = std::shared_ptr<MNN::Interpreter>(MNN::Interpreter::createFromFile(model_name.c_str()));
if (nullptr == net) {
return 0;
}
MNN::ScheduleConfig config;
config.numThread = 4;
config.type = static_cast<MNNForwardType>(MNN_FORWARD_CPU);
MNN::BackendConfig backendConfig;
backendConfig.precision = (MNN::BackendConfig::PrecisionMode)2;
// backendConfig.precision = MNN::PrecisionMode Precision_Normal; // static_cast<PrecisionMode>(Precision_Normal);
config.backendConfig = &backendConfig;
MNN::Session *session = net->createSession(config);;
int INPUT_SIZE = 640;
std::string image_name = "../bus.jpg";
// load image
cv::Mat raw_image = cv::imread(image_name.c_str());
cv::Mat image;
cv::resize(raw_image, image, cv::Size(INPUT_SIZE, INPUT_SIZE));
// preprocessing
image.convertTo(image, CV_32FC3);
// image = (image * 2 / 255.0f) - 1;
image = image /255.0f;
// wrapping input tensor, convert nhwc to nchw
std::vector<int> dims{1, INPUT_SIZE, INPUT_SIZE, 3};
auto nhwc_Tensor = MNN::Tensor::create<float>(dims, NULL, MNN::Tensor::TENSORFLOW);
auto nhwc_data = nhwc_Tensor->host<float>();
auto nhwc_size = nhwc_Tensor->size();
std::memcpy(nhwc_data, image.data, nhwc_size);
auto inputTensor = net->getSessionInput(session, nullptr);
inputTensor->copyFromHostTensor(nhwc_Tensor);
// run network
net->runSession(session);
// get output data
std::string output_tensor_name0 = layers[2].name ;
std::string output_tensor_name1 = layers[1].name ;
std::string output_tensor_name2 = layers[0].name ;
MNN::Tensor *tensor_scores = net->getSessionOutput(session, output_tensor_name0.c_str());
MNN::Tensor *tensor_boxes = net->getSessionOutput(session, output_tensor_name1.c_str());
MNN::Tensor *tensor_anchors = net->getSessionOutput(session, output_tensor_name2.c_str());
MNN::Tensor tensor_scores_host(tensor_scores, tensor_scores->getDimensionType());
MNN::Tensor tensor_boxes_host(tensor_boxes, tensor_boxes->getDimensionType());
MNN::Tensor tensor_anchors_host(tensor_anchors, tensor_anchors->getDimensionType());
tensor_scores->copyToHostTensor(&tensor_scores_host);
tensor_boxes->copyToHostTensor(&tensor_boxes_host);
tensor_anchors->copyToHostTensor(&tensor_anchors_host);
std::vector<BoxInfo> result;
std::vector<BoxInfo> boxes;
yolocv::YoloSize yolosize = yolocv::YoloSize{INPUT_SIZE,INPUT_SIZE};
float threshold = 0.3;
float nms_threshold = 0.7;
show_shape(tensor_scores_host.shape());
show_shape(tensor_boxes_host.shape());
show_shape(tensor_anchors_host.shape());
boxes = decode_infer(tensor_scores_host, layers[2].stride, yolosize, net_size, num_classes, layers[2].anchors, threshold);
result.insert(result.begin(), boxes.begin(), boxes.end());
boxes = decode_infer(tensor_boxes_host, layers[1].stride, yolosize, net_size, num_classes, layers[1].anchors, threshold);
result.insert(result.begin(), boxes.begin(), boxes.end());
boxes = decode_infer(tensor_anchors_host, layers[0].stride, yolosize, net_size, num_classes, layers[0].anchors, threshold);
result.insert(result.begin(), boxes.begin(), boxes.end());
nms(result, nms_threshold);
std::cout<<result.size()<<std::endl;
scale_coords(result, INPUT_SIZE, INPUT_SIZE, raw_image.cols, raw_image.rows);
cv::Mat frame_show = draw_box(raw_image, result, labels);
cv::imwrite("../output.jpg", frame_show);
return 0;
}
// std::shared_ptr<MNN::Interpreter> net =
// std::shared_ptr<MNN::Interpreter>(MNN::Interpreter::createFromFile(fileName));
// if (nullptr == net) {
// return 0;
// }
// // Must call it before createSession.
// // If ".tempcache" file does not exist, Interpreter will go through the
// // regular initialization procedure, after which the compiled model files
// // will be written to ".tempcache".
// // If ".tempcache" file exists, the Interpreter will be created from the
// // cache.
// net->setCacheFile(".tempcache");
// MNN::ScheduleConfig config;
// // Creates the session after you've called setCacheFile.
// MNN::Session* session = net->createSession(config);测试结果


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)