【MPC】模型预测控制 | 在车辆控制中的应用(二)目标函数构建
写在前面:
🌟 欢迎光临 清流君 的博客小天地,这里是我分享技术与心得的温馨角落。📝
个人主页:清流君_CSDN博客,期待与您一同探索 移动机器人 领域的无限可能。
🔍 本文系 清流君 原创之作,荣幸在CSDN首发🐒
若您觉得内容有价值,还请评论告知一声,以便更多人受益。
转载请注明出处,尊重原创,从我做起。
👍 点赞、评论、收藏,三连走一波,让我们一起养成好习惯😜
在这里,您将收获的不只是技术干货,还有思维的火花!
📚 系列专栏:【运动控制】系列,带您深入浅出,领略控制之美。🖊
愿我的分享能为您带来启迪,如有不足,敬请指正,让我们共同学习,交流进步!
🎭 人生如戏,我们并非能选择舞台和剧本,但我们可以选择如何演绎 🌟
感谢您的支持与关注,让我们一起在知识的海洋中砥砺前行~~~
引言
本篇博客将探讨如何构建目标函数,以有针对性地优化车辆的运动行为。目标函数是优化控制中的核心概念,它明确地表达了优化的目的以及期望车辆的行为。
一、目标函数的定义
目标函数定义了控制车辆应达到的效果。一般而言,目标函数可以从以下几个方面进行定义:
1. 跟踪目标
在路径规划阶段,若已对舒适度、安全度进行了优化,则期望车辆能够严格跟踪参考轨迹,就可以提高跟踪参考轨迹的代价,确保车辆行为符合预期。
- 参考轨迹跟踪精确度的优化
为了确保车辆能够精确跟踪预定的轨迹,目标函数需要包含跟踪误差的项,涉及到位置误差和速度误差。
2、舒适度目标
在路径规划中,若未进行平滑处理,且重视舒适度,则应对舒适度建立目标函数来调整代价。
3、安全性目标
安全性是车辆控制系统的首要考虑因素,目标函数应包含安全性约束,如碰撞避免和行驶稳定性。
二、多目标优化与权衡
1、不同目标的权重
在构建目标函数时,往往需要处理多个相互冲突的目标。例如,提高跟踪精确度可能会牺牲舒适性。因此,需要在目标函数中为不同的目标设置合适的权重,以实现多目标优化:
J = w t ⋅ J t r a c k i n g + w c ⋅ J c o m f o r t + w s ⋅ J s a f e t y J=w_{t}\cdot J_{tracking}+w_{c}\cdot J_{comfort}+w_{s}\cdot J_{safety} J=wt⋅Jtracking+wc⋅Jcomfort+ws⋅Jsafety其中, w t w_t wt 是跟踪误差的权重, w c w_{c} wc 是舒适度的权重, w s w_{s} ws 是安全性的权重。
2、权重调节的优先级
需要注意的是,这三个目标函数之间可能会出现一些冲突,在不同场景下,三个权重的调节会有一个优先级的概念。例如,我们可能会希望车辆行驶时具有较高的舒适性,但在紧急情况下,安全性能可能会优先考虑,从而牺牲舒适性。所以这几项目标函数需要根据不同场景进行权衡。
三、目标函数解析
1、跟踪项目标函数 (Tracking Objective)
下面来分析一下跟踪项代价,这是衡量车辆沿着预设轨迹行驶期望程度的一个指标。
跟踪代价的核心在于以下两点:
- 确保车辆遵循规划器设计的预定路径。
- 确保车辆遵循上层规划模块设定的 速度曲线(Speak Profile)。
根据这两个要求,可以写成以下形式:
J t r a c k i n g = w s ˙ ⋅ ( s ˙ − s ˙ r e f ) 2 + w n ⋅ n 2 + w μ ⋅ ( μ + β ) 2 J_{tracking}=w_{\dot{s}}\cdot\left(\dot{s}-\dot{s}_{ref}\right)^{2}+w_{n}\cdot n^{2}+w_{\mu}\cdot(\mu+\beta)^{2} Jtracking=ws˙⋅(s˙−s˙ref)2+wn⋅n2+wμ⋅(μ+β)2
- 第一项为沿参考轨迹运动的速度偏差;
- 第二项为横向偏移矫正;
- 第三项为方向角度误差的矫正。
2、舒适度目标函数 (Comfort Objective)
另一个重要的考量因素是建立与车辆行驶舒适度相关的目标函数,来提升车辆行驶过程中的乘坐舒适度:
J c o m f o r t = w j x ⋅ j x 2 + w a x ⋅ a x 2 + w a y ⋅ a y 2 + w δ ˙ ⋅ δ ˙ + w δ ¨ ⋅ δ ¨ 2 J_{comfort}=w_{j_{x}}\cdot j_{x}^{2}+w_{a_{x}}\cdot a_{x}^{2}+w_{a_{y}}\cdot a_{y}^{2}+w_{\dot{\delta}}\cdot\dot{\delta}+w_{\ddot{\delta}}\cdot\ddot{\delta}^{2} Jcomfort=wjx⋅jx2+wax⋅ax2+way⋅ay2+wδ˙⋅δ˙+wδ¨⋅δ¨2
- 第一项为对纵向 跃度(jerk) 的控制;
- 第二项为对纵向加速度的变化的控制;
- 第三项为对横向加速度的这控制;
- 第四项和第五项为对转向角变化/振荡的优化。
需要注意的是,在选择不同的量进行最小化时,并不一定需要将所有因素都纳入考量。因为车辆控制系统是一个整体耦合的系统。例如,当引入对角加速度的优化时,实际上也会相应减少车辆的横向晃动,即 y y y 方向上的跃度;当减少转向角速度的晃动时,纵向加速度 a y a_y ay 也会相应减少。因此,可以有选择、有侧重点地选择几个较为关注的量进行最小化处理。
3、安全性目标函数 (Safety Objective)
另一个在MPC中很重要的目标函数是对安全性的优化。在规划过程中,根据周围环境建立安全可行的范围。在这个范围内,车辆的运动是安全的。相反,超出这个范围的运动可能会变得不安全。因此,可以通过衡量系统对约束的违反程度来评估其安全性能。
a)软约束
为了更有效地处理约束,引入软约束的概念。系统的约束分为硬约束和软约束两种:
- 硬约束是不可违反的,通常与物理限制相关,如电机最大转速或车辆油门的最大移动量。
- 软约束则允许一定程度的违反,这有助于避免不同约束之间的冲突,从而确保优化问题的可行性。
例如,一辆汽车在高速公路上以每小时 50 50 50 公里的速度行驶,当它开始爬坡时,由于重力的影响,速度会自然下降。在这种情况下,控制器可以通过增加油门开度来尝试提高速度,但由于汽车顶部负载增加,即使控制器完全打开油门,速度仍然会下降,导致速度约束难以满足。
如果速度限制是软约束,控制器在爬坡过程中允许速度超过限制,直到汽车越过坡顶,此时冲突不会发生。
因此,对于这类情况,就建议将输出的约束设为软约束,以避免输出和输入之间的冲突。
在实际应用中,软约束的使用可以减少系统的控制复杂度,并允许操作域的扩展。由于实际系统中存在测量误差或干扰,软约束可以提供一定的灵活性,防止控制器超出可行操作范围。因此,在工业应用中,通常会将状态量和控制范围设为软约束,以提高系统的稳定性和适应性。
引入松弛变量
在控制策略中,我们引入了一个新的变量 λ k \lambda_k λk,即松弛变量。类似于状态输入,松弛变量为优化器提供了对边界违反的容许度。为了保证对软约束的微小违反,我们通过优化问题将其最小化,从而将安全性优化转化为对约束违反的惩罚。
因此,原来的 MPC 问题:
min U ≜ { u k ∣ k , u k + 1 ∣ k , . . . } J ( x k , U ) = ∑ k = 0 N − 1 J s t a g e ( x k , u k ) s . t . x k + 1 = f ( x k , u k ) , c k ( x k , u k ) ≤ 0 , x ∈ X , u ∈ U . \begin{gathered} \min_{U\triangleq\{u_{k|k},u_{k+1|k},...\}}J(x_{k},U)=\sum_{k=0}^{N-1}J_{stage}(x_{k},u_{k}) \\ s.t.\quad x_{k+1}=f(x_{k},u_{k}), \\ c_{k}(x_{k},u_{k})\leq0, \\ x\in\mathcal{X}, \\ u\in \mathcal{U}. \end{gathered} U≜{uk∣k,uk+1∣k,...}minJ(xk,U)=k=0∑N−1Jstage(xk,uk)s.t.xk+1=f(xk,uk),ck(xk,uk)≤0,x∈X,u∈U.转化为加入松弛因子后的问题:
min U ≜ { u k ∣ k , u k + 1 ∣ k , … } J ( x k , U ) = ∑ k = 0 N − 1 J s t a g e ( x k , u k , λ k ) s . t . x k + 1 = f ( x k , u k ) , c k ( x k , u k , λ k ) ≤ 0 , x ∈ X , u ∈ U , λ ∈ Λ . \begin{gathered} \min_{U\triangleq\{u_{k|k},u_{k+1|k},\ldots\}}J(x_{k},U)=\sum_{k=0}^{N-1}J_{stage}(x_{k},u_{k},\lambda_{k}) \\ s.t.\quad x_{k+1}=f(x_{k},u_{k}), \\ c_{k}(x_{k},u_{k},\lambda_{k})\leq0, \\ x\in\mathcal{X}, \\ u\in \mathcal{U}, \\ \lambda\in\Lambda. \end{gathered} U≜{uk∣k,uk+1∣k,…}minJ(xk,U)=k=0∑N−1Jstage(xk,uk,λk)s.t.xk+1=f(xk,uk),ck(xk,uk,λk)≤0,x∈X,u∈U,λ∈Λ.
为松弛因子设定合理范围,避免其值过大。通过优化松弛变量,可以调整对约束违反的程度,从而实现安全性能的优化。因此,我们可以将安全性能目标函数表示为如下形式:
J s a f e t y = λ s o f t T E λ s o f t + H ‾ λ h a r d J_{safety}=\lambda_{soft}^{T}E\lambda_{soft}+\overline{H}\lambda_{hard} Jsafety=λsoftTEλsoft+Hλhard其中, λ s o f t \lambda_{soft} λsoft 是引入的松弛因子。
λ s o f t = [ λ n , s o f t λ v , s o f t λ a , s o f t ] \lambda_{soft}=\begin{bmatrix}\lambda_{n,soft}\\\lambda_{v,soft}\\\lambda_{a,soft}\end{bmatrix} λsoft=
λn,softλv,softλa,soft
现在我们引入了三个变量:横向误差松弛因子 λ n , s o f t \lambda_{n,soft} λn,soft、纵向速度松弛因子 λ v , s o f t \lambda_{v,soft} λv,soft 以及加速度松弛因子 λ a , s o f t \lambda_{a,soft} λa,soft。在实际应用中,这三个变量确实可以允许一定程度上的违反,因此我们对其施加了软约束。其中, E E E 表示我们对这三个软约束的权重分配:
E = d i a g ( w λ n , s o f t , w λ v , s o f t , w λ a , s o f t ) E=diag(w_{\lambda_{n,soft}},w_{\lambda_{v,soft}},w_{\lambda_{a,soft}}) E=diag(wλn,soft,wλv,soft,wλa,soft)其中包含了了横向误差权重比、速度软约束权重比以及加速度软约束权重比。
b)硬约束
同时也加入了硬约束,即: λ h a r d = [ λ n λ a λ s ] \lambda_{hard}=\begin{bmatrix}\lambda_{n}\\\lambda_{a}\\\lambda_{s}\end{bmatrix} λhard= λnλaλs
① 横向偏移硬约束
需要注意的是,硬约束与软约束的含义不同,即它们的数值是不相等的。我们提出硬约束和软约束的主要原因在于,当车辆在道路上行驶时,通常会设定一个合理的允许车辆晃动或偏离的范围。因此,我们假设在软约束下,可以有一定的违反冗余度和容忍度。但这种容忍是有限的,不能超出道路路面。
因此,需要为系统施加物理性的强制硬约束,例如道路边缘,也就是马路牙子,以限制车辆的横向偏差并防止其脱离道路。
② 加速度硬约束
同时,我们也需要对加速度施加硬约束,确保车辆的实际加速度不超过某个安全值。这些硬约束是确保车辆安全行驶的重要条件。
③ 位置硬约束
第三个考虑的因素是对位置的硬约束,这一项反映了对车辆之间碰撞风险的考量。例如,假设车辆正在道路上行驶,前方有一辆车在行驶,那么前方车辆在物理上限制了我们的行驶进程,使其只能在一定范围内进行,这个范围构成了一个硬约束,不能违反它。
与软约束类似,我们也为硬约束分配了一个权重比:
H = [ w λ n , w λ a , w λ s ] {H}=[w_{\lambda_{n}},w_{\lambda_{a}},w_{\lambda_{s}}] H=[wλn,wλa,wλs]包括对硬约束的横向偏差、加速度和位置进程的权重比。
综上所述,根据不同的应用场景,选择构建不同的优化目标函数,这些目标函数涵盖了参考轨迹的跟踪能力、舒适度以及安全性,同时也考虑了约束的违反程度:
J t r a c k i n g = w s ˙ ⋅ ( s ˙ − s ˙ r e f ) + w n ⋅ n 2 + w μ ⋅ ( μ + β ) 2 J c o m f o r t = w j x ⋅ j x 2 + w a x ⋅ a x 2 + w a y ⋅ a y 2 + w δ ˙ ⋅ δ ˙ + w δ ˙ ⋅ δ ¨ 2 J s a f e t y = λ s o f t T E λ s o f t + H ‾ λ h a r d \begin{aligned}&J_{tracking}=w_{\dot{s}}\cdot\left(\dot{s}-\dot{s}_{ref}\right)+w_{n}\cdot n^{2}+w_{\mu}\cdot(\mu+\beta)^{2}\\&J_{comfort}=w_{j_{x}}\cdot j_{x}^{2}+w_{a_{x}}\cdot a_{x}^{2}+w_{a_{y}}\cdot a_{y}^{2}+w_{\dot{\delta}}\cdot\dot{\delta}+w_{\dot{\delta}}\cdot\ddot{\delta}^{2}\\&J_{safety}=\lambda_{soft}^{T}E\lambda_{soft}+\overline{H}\lambda_{hard}\end{aligned} Jtracking=ws˙⋅(s˙−s˙ref)+wn⋅n2+wμ⋅(μ+β)2Jcomfort=wjx⋅jx2+wax⋅ax2+way⋅ay2+wδ˙⋅δ˙+wδ˙⋅δ¨2Jsafety=λsoftTEλsoft+Hλhard
四、标准有限时域MPC的不足
这样就足够了吗?那么我们还遗漏了对哪些方面的考虑呢?
在回答这个问题之前,我们先来探讨一下标准有限时域的 MPC 可能出现的问题。
我们知道,MPC是一种短期策略,其每一步的预测轨迹只能跟踪第一步。此外,在MPC中只考虑了有限时域内的优化问题。因此,可能会遇到以下两种情况:
1、难以保证MPC的可行性
第一种情况是可能无法找到满足所有约束条件的解。这种情况通常发生在约束条件非常严格或者存在冲突的情况下,或者预测时域太短,无法使系统从初始状态稳定下来。
2、难以保证MPC的稳定性
第二种情况是由于MPC只考虑了有限时域内的优化问题,系统从初始状态到稳定状态通常需要一定的时间。如果预测时域太短,就很难完成这个收敛过程。
五、终端代价和约束
为了确保系统的状态在预期预测期结束时在一个特定的集合内取值,从而保证迭代的稳定性和可行性,我们可以有针对性地对终端状态进行约束和优化。
1、终端代价与阶段性代价
在MPC中,终端控制的目的是确保系统状态在预测时域的最后一个阶段达到预定的目标状态。这种终端目标函数的设置不同于常规的阶段性代价 (staging cost),后者主要关注预测时域内的优化问题。终端代价 (terminal cost) 是在预测时域之后的最终阶段施加,用于提高闭环系统的稳定性和整体性能,以弥补由于预测时域有限制而无法进行无限优化的问题。
通过这种方式,MPC策略能够在有限预测时域内实现对系统状态的优化控制,同时确保系统在预测时域结束时能够稳定地达到预期的状态,从而提高整个控制过程的稳定性和效率。
2、预测时域的调整
在控制设计过程中,特别是在非线性MPC中,通常不需要强制实时执行终端代价和终止约束来实现闭环稳定性。而是可以通过验证后验的方式来确保稳定性,即在实际运行过程中,如果系统状态不满足预定的终端状态,我们可以适当增加预测范围,以适应系统的不确定性和动态变化。
因此,我们可以将之前的问题转化为以下形式:
min U ≜ { u k ∣ k , u k + 1 ∣ k , . . . } J ( x k , U ) = ∑ k = 0 N − 1 J s t a g e ( x k , u k , λ k ) + J t e r m i n a l ( x N ) s.t. x k + 1 = f ( x k , u k ) , c k ( x k , u k , λ k ) ≤ 0 , x ∈ X , u ∈ U , λ ∈ Λ . \begin{aligned} &&\min_{U\triangleq\{u_{k|k},u_{k+1|k},...\}}J(x_{k},U)& =\sum_{k=0}^{N-1}J_{stage}(x_{k},u_{k},\lambda_{k})+\boxed{J_{terminal}(x_{N})} \\ &\text{s.t.} && x_{k+1}=f(x_{k},u_{k}), \\ &&&c_k(x_k,u_k,\lambda_k)\leq0, \\ &&&x\in\mathcal{X}, \\ &&&u\in\mathcal{U}, \\ &&&\lambda\in\Lambda. \end{aligned} s.t.U≜{uk∣k,uk+1∣k,...}minJ(xk,U)=k=0∑N−1Jstage(xk,uk,λk)+Jterminal(xN)xk+1=f(xk,uk),ck(xk,uk,λk)≤0,x∈X,u∈U,λ∈Λ.引入了终端代价(Terminal Cost),用 J t e r m i n a l J_{terminal} Jterminal表示,并将预测时域内的代价重新定义为阶段性代价(Staging Cost)。
3、终端代价的设置
在实践中,如何选择终端代价和终端约束呢?
通常情况下,终端约束为系统提供了全局稳定性的充分条件。通过增加预测时域的长度,我们可以扩大系统的吸引区域(Region of Attraction),进而增加终端区域。这样,我们就可以检查系统的稳定性。
对于较小的预测时域长度 n n n,可以选择将终端代价设置为 0 0 0,作为最简单的选择。这样做会导致吸引区域较小,即系统能够稳定运行的范围较窄。
4、吸引区域(Region of Attraction)
吸引区域实际上是系统稳定性特征的指标。对于较长的预测时域,这个区域通常接近系统的最大控制面积。在没有终端约束的情况下,吸引区域有时可能比具有终端约束的MPC更大。然而,这也使得表征吸引区域变得非常困难。
总的来说,增加预测步长可以增加实际吸引区域的大小。同样,增加终端区域也会增加吸引区域,从而提高系统的稳定性和性能。
六、终端代价的实际应用
在车辆控制的实际应用中,通常会选择将终端代价设置在**移动时域(Moving Horizon)**的最后一个阶段,促使车俩与参考路径的运动方向对齐。这种代价的设置有助于确保车辆紧密地追踪参考轨迹,即使是在当前控制范围之外,也能够保持轨迹的连续性和平滑性。
最常见的应用场景就是弯道停车: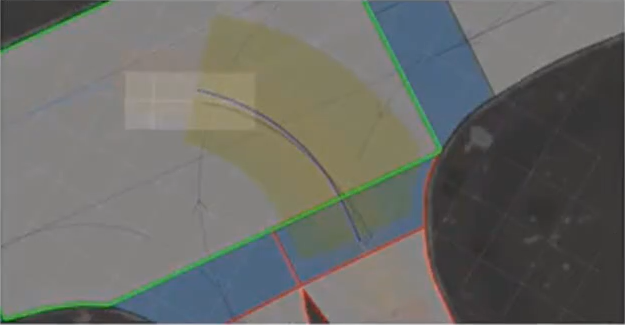
在弯道停车时,移动时域的预测时长有限,很可能只延伸到停车线。这意味着预测时域之外的后续路径对我们来说是不可见的。
所以可以增加一个终端代价,即在预测时域的最后阶段施加一个目标函数,以使得最终停车时的车辆方向与后续路径的方向对齐,有助于提高整个控制系统的性能。
后记:
🌟 感谢您耐心阅读这篇关于 目标函数构建 的技术博客。 📚
🎯 如果您觉得这篇博客对您有所帮助,请不要吝啬您的点赞和评论 📢
🌟您的支持是我继续创作的动力。同时,别忘了收藏本篇博客,以便日后随时查阅。🚀
🚗 让我们一起期待更多的技术分享,共同探索移动机器人的无限可能!💡
🎭感谢您的支持与关注,让我们一起在知识的海洋中砥砺前行 🚀

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)