CNN卷积神经网络底层原理详细分析及基于pytorch的代码实现
`Conv2d`参数详解:- `1`: 输入通道数(MNIST为灰度图)- `32`: 输出通道数(特征图数量)- `padding=1`: 在输入周围填充1圈0,保持空间分辨率(计算公式:`H_out = (H_in + 2*padding - kernel_size)/stride + 1`)- `MaxPool2d(2,2)`:使用2x2窗口,步长2,输出尺寸减半。
1. CNN底层原理详细分析
1.1 核心设计
卷积神经网络(CNN) 是计算机视觉领域的基石模型,其设计灵感来源于生物视觉皮层感受野的层次化特征提取机制。作为大模型开发人员,需理解其三大核心特性:
1)局部感受野(Local Receptive Fields)
- 传统全连接网络参数爆炸问题:输入尺寸为`[H,W,C]`的图片展开为向量后,参数量为`(H*W*C) * hidden_units`
- 卷积核通过滑动窗口仅关注局部区域(如3x3),参数共享机制使得参数量仅为`K*K*C_in*C_out`(K为核大小)
2)层次化特征抽象
- 底层卷积层提取边缘/纹理等低级特征
- 深层网络捕获语义信息(如物体部件、类别)
- 与Transformer的全局注意力形成互补(现代大模型如ViT、Swin Transformer均保留CNN层次化设计思想)
3)平移等变性(Translation Equivariance)
- 卷积操作对输入平移具有等变性:`conv(translate(x)) = translate(conv(x))`
- 这一特性使CNN天然适合图像数据,但缺乏旋转/尺度不变性(需通过数据增强或特殊结构补偿)
1.2 数学形式化表达
1)单层卷积操作可形式化为:
$$
\text{Output}(i,j) = \sum_{m=0}^{k-1} \sum_{n=0}^{k-1} \mathbf{W}(m,n) \cdot \mathbf{X}(i+m, j+n) + b
$$
2)多通道扩展(现代CNN核心):
- 输入张量: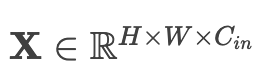
- 卷积核: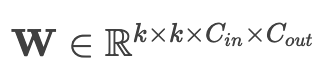
- 输出张量: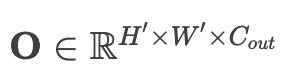
3)参数共享使得每个通道的卷积核在整个图像上重复使用,极大降低参数量。
1.3 关键组件解析
1)卷积层(Convolution Layer)
- 核心功能:特征提取
- 超参数选择:
- 小卷积核(3x3为主流,参考VGGNet设计哲学)
- Padding策略("same"保持分辨率,"valid"降低分辨率)
- Stride控制下采样率
2)池化层(Pooling Layer)
- 功能:降维、平移鲁棒性、防止过拟合
- Max Pooling公式:
$$ \text{Output}(i,j) = \max_{m,n \in \mathcal{N}(i,j)} \mathbf{X}(m,n) $$
- 现代趋势:被带步长的卷积替代(如ResNet)
3)激活函数
- ReLU及其变体(LeakyReLU, Swish)引入非线性
- 数学表达式:
$$ \text{ReLU}(x) = \max(0, x) $$
- 专家级理解:避免梯度消失同时保持计算效率
4)Batch Normalization
- 现代CNN标配组件,解决Internal Covariate Shift问题
- 计算公式:
$$ \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma + \beta $$
5)残差连接(Residual Connection)
- 来自ResNet的核心创新,解决深层网络梯度消失问题
- 数学表达式: 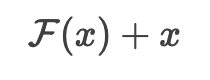
- 大模型启示:被Transformer广泛借鉴(如BERT中的skip-connection)
2. 代码实现(PyTorch版本)
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 超参数配置
BATCH_SIZE = 128
EPOCHS = 10
LEARNING_RATE = 0.001
# 数据预处理管道
transform = transforms.Compose([
transforms.ToTensor(), # 将PIL图像转换为Tensor [0,1]范围
transforms.Normalize((0.1307,), (0.3081,)) # MNIST均值和标准差
])
# 数据集加载
train_dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
test_dataset = datasets.MNIST(
root='./data',
train=False,
transform=transform
)
# 数据加载器(高效分批加载)
train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True # 训练时打乱顺序防止过拟合
)
test_loader = DataLoader(
test_dataset,
batch_size=BATCH_SIZE,
shuffle=False # 测试时无需打乱
)
# CNN模型定义
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 特征提取网络
self.features = nn.Sequential(
# 卷积层1: 输入1通道,输出32通道,3x3卷积核
nn.Conv2d(1, 32, kernel_size=3, padding=1), # 输出尺寸: [32, 28, 28]
nn.ReLU(inplace=True), # 原地操作节省内存
nn.MaxPool2d(kernel_size=2, stride=2), # 输出尺寸: [32, 14, 14]
# 卷积层2: 输入32通道,输出64通道
nn.Conv2d(32, 64, 3, padding=1), # [64, 14, 14]
nn.ReLU(inplace=True),
nn.MaxPool2d(2) # [64, 7, 7]
)
# 分类网络
self.classifier = nn.Sequential(
nn.Linear(64 * 7 * 7, 512), # 展平后全连接
nn.ReLU(inplace=True),
nn.Dropout(p=0.5), # 防止过拟合
nn.Linear(512, 10) # 输出10个类别(MNIST数字0-9)
)
def forward(self, x):
x = self.features(x) # 通过卷积层提取特征
x = torch.flatten(x, 1) # 展平处理,保留batch维度
x = self.classifier(x) # 通过全连接层分类
return x
# 初始化模型、损失函数、优化器
model = CNN()
criterion = nn.CrossEntropyLoss() # 结合LogSoftmax和NLLLoss
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE) # 自适应学习率优化器
# 训练循环
def train(model, device, train_loader, optimizer, epoch):
model.train() # 设置训练模式(启用Dropout等)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad() # 清空历史梯度
output = model(data) # 前向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播计算梯度
optimizer.step() # 参数更新
# 测试函数
def test(model, device, test_loader):
model.eval() # 设置评估模式(关闭Dropout)
test_loss = 0
correct = 0
with torch.no_grad(): # 禁用梯度计算
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item() # 累加损失
pred = output.argmax(dim=1, keepdim=True) # 获取预测类别
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)')
# 主程序
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
for epoch in range(1, EPOCHS + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
# 保存模型
torch.save(model.state_dict(), "mnist_cnn.pt")3. 代码分析
3.1 数据预处理部分
transform = transforms.Compose([
transforms.ToTensor(), # 将图像转换为PyTorch Tensor(CHW格式)
transforms.Normalize((0.1307,), (0.3081,)) # 标准化到[-1,1]区间
])- `ToTensor()`:将PIL Image或numpy数组转换为`[C, H, W]`格式的Tensor,并自动缩放到[0,1]范围
- `Normalize`:使用MNIST数据集的全局均值(0.1307)和标准差(0.3081)进行标准化,计算公式:
$$ x' = \frac{x - \mu}{\sigma} $$
3.2 模型定义部分
self.features = nn.Sequential(
nn.Conv2d(1, 32, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(2, 2)- `Conv2d`参数详解:
- `1`: 输入通道数(MNIST为灰度图)
- `32`: 输出通道数(特征图数量)
- `padding=1`: 在输入周围填充1圈0,保持空间分辨率(计算公式:`H_out = (H_in + 2*padding - kernel_size)/stride + 1`)
- `MaxPool2d(2,2)`:使用2x2窗口,步长2,输出尺寸减半
3.3 训练循环关键代码
optimizer.zero_grad() # 必须清空梯度,否则会累积
output = model(data) # 前向传播:调用forward方法
loss = criterion(output, target)
loss.backward() # 自动微分计算所有参数的梯度
optimizer.step() # 根据梯度更新参数- PyTorch的梯度是累积的,必须每个batch前清空
- `loss.backward()`利用自动微分系统(Autograd)构建计算图的反向传播
- `optimizer.step()`根据梯度更新参数,内部实现:
$$ \theta_{t+1} = \theta_t - \eta \nabla_\theta \mathcal{L} $$
3.4 测试阶段关键代码
model.eval() # 关闭Dropout/BatchNorm的train模式
with torch.no_grad(): # 关闭梯度计算,节省内存
output = model(data)
pred = output.argmax(dim=1) # 取概率最大的类别- `eval()`模式会固定BatchNorm的running_mean/running_var
- `torch.no_grad()`上下文管理器禁用梯度跟踪,提升计算速度
- `argmax(dim=1)`在通道维度取最大值索引(每个样本的预测类别)
4. 扩展建议
1)模型架构优化
- 添加BatchNorm层加速收敛:在Conv层后加入`nn.BatchNorm2d`
- 使用更深的架构(如ResNet-18)提升准确率
- 尝试注意力机制(如SE Block)增强特征表达能力
2)训练策略升级
- 学习率调度器(如CosineAnnealingLR)
- 数据增强(随机旋转、缩放、CutMix)
- 混合精度训练(`torch.cuda.amp`)
3)部署优化
- 模型量化(Post-training Quantization)
- ONNX格式导出
- TensorRT加速
4)与大模型结合
- 作为Vision Transformer的骨干网络
- 多模态模型中的视觉编码器(如CLIP)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)