论文解读《FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation》
然后将提取的逐点特征馈送到实例语义分割和3D关键点投票检测模块中,以获得场景中的每个对象的3D关键点。具体而言:通过添加实例语义分割模块来区分不同的对象实例,并添加关键点投票模块来恢复三维关键点,从而获得每个对象的三维关键点。实例语义分割模块由语义分割模块和中心点投票模块组成,前者预测每点语义标签,后者学习每点到对象中心的偏移量,以区分不同的实例。这些点很难检测,估计姿态的精度降低。基于PVN3D
论文:《FFB6D: A Full Flow Bidirectional Fusion Network for 6D Pose Estimation》 (是PVN3D团队的后续之作)
该论文是结合并改进了DenseFusion和PVN3D,感觉整体框架设计比较牛。
Code:https://github.com/ethnhe/FFB6D (217star)
摘要:
-
解决问题:
- RGB图像中的外观信息和深度图像中的几何信息是两个互补的数据源,如何充分利用它们仍然未知。 孤立的处理RGB和D或者是RGB和点云(如,先在RGB图像出估计初始位姿,再通过点云ICP(Posecnn)或multi-view hypothesis verification来优化非常耗时,而且使用不了端到端的RGB图像优化),性能都是不够好的。 => 本文见解:(创新点1)RGB中的外观信息和点云中的几何信息可以在其特征提取过程中作为互补信息。具体来说,在CNN编码解码过程中,CNN很难从RGB图像中学习相似对象的独特表示,然而,在PCN看来,这是显而易见的;另一方面,物体反射表面造成的深度缺失挑战了仅点云的几何推理。 融合方法应该1+1>2,而不是1+1=2。 (可以视为对DenseFusion的改进,可见论文图1。)
-
提出了一个全流双向融合网络(Full Flow Bidirectional fusion network,FFB6D),用于从单个RGB-D图像中估计6D姿态。
给定一个对齐的RGBD图像,要首先将深度图像转换为的点云。
FFB6D学习将外观和几何信息结合起来进行表示学习以及输出表示选择。具体来说,
- 在表示学习阶段,该模型在两个网络(CNN网络处理RGB图的颜色信息,PCN(Point Cloud Network)网络处理点云的几何信息)的全流程中构建双向融合模块,其中融合应用于每个编码和解码层。通过这种方式,这两个网络可以利用来自另一个网络的局部和全局互补信息来获得更好的表示。
- 在输出表示阶段,设计了一种简单但有效的3D关键点选择算法,考虑了物体的纹理和几何信息,简化了关键点定位(创新点2),实现了精确的姿态估计。该阶段,是在PVN3D的基础上做了改进:PVN3D仅考虑关键点之间的距离以进行3D关键点选择,然而一些选定的关键点可能出现在不显著的区域,如没有明显纹理的平滑表面,从而很难定位。 => 同时考虑了对象纹理和几何信息,并提出了用于自动3D关键点选择的SIFT-FPS算法,以这种方式过滤的显著关键点更容易被网络定位,并且有利于姿态估计性能。
-
效果:在YCB Video、LineMOD和Occlusion LineMOD数据集上测试,表明,在没有任何耗时的后细化过程的情况下,所提出的方法大大优于现有技术。
网络架构:
-
表示学习阶段:
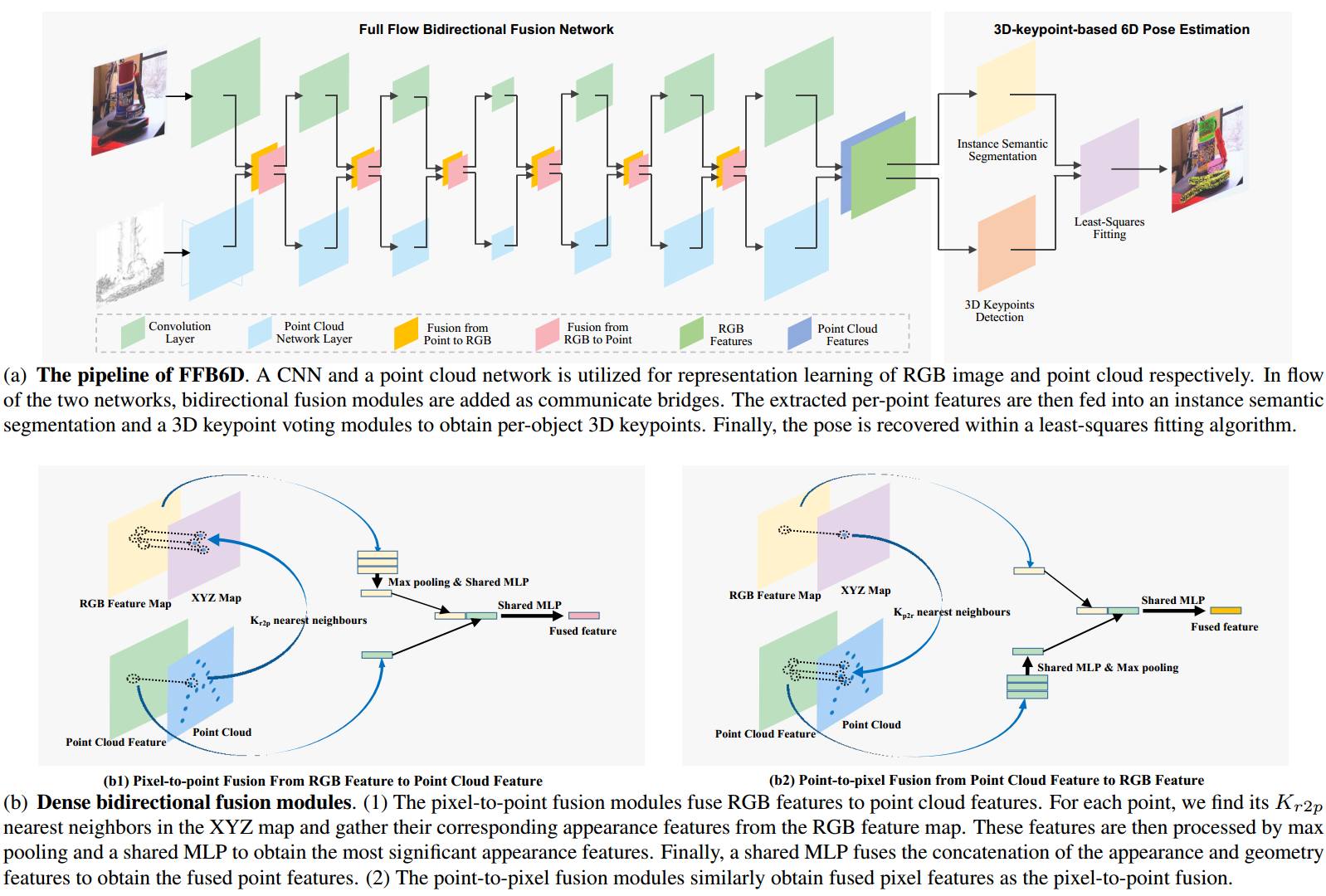
给定RGB-D图像作为输入,利用CNN从RGB图像中提取外观特征,并利用点云网络从点云中提取几何特征。在两个网络的特征提取流程中,在每一层中都添加了点对像素和点对点融合模块作为通信桥梁。通过这种方式,两个分支可以利用来自另一个分支的额外外观/几何信息来促进它们自己的表示学习。然后将提取的逐点特征馈送到实例语义分割和3D关键点投票检测模块中,以获得场景中的每个对象的3D关键点。最后,应用最小二乘拟合算法对6D姿态参数进行恢复。
其中的密集双向融合模块:
- Pixel-to-point模块将RGB特征融合到点云特征。对于每个点,在XYZ图中找到其Kr2p最近的邻居,并从RGB特征图中收集其相应的外观特征。然后通过最大池化和共享MLP来处理这些特征,以获得最重要的外观特征。最后,共享MLP融合外观特征和几何特征的级联,以获得融合的point特征。
- Point-to-pixel模块类似Pixel-to-point模块,获得融合的pixel特征。
从CNN分支获得表面纹理特征,从PCN分支获得几何特征。然后,通过使用相机内参矩阵将每个点投影到图像平面来找到它们之间的对应关系。根据对应关系,获得外观特征和几何特征对,并将它们连接在一起,形成提取的密集RGBD特征。在下一步中,这些特征被输入到一个实例语义分割模块和一个3D关键点投票检测模块中,用于物体姿态估计。
-
输出表示阶段:
基于PVN3D的逐对象3D关键点检测,首先在场景中检测每个对象选择的3D关键点,然后利用最小二乘拟合算法恢复姿势参数。
具体而言:通过添加实例语义分割模块来区分不同的对象实例,并添加关键点投票模块来恢复三维关键点,从而获得每个对象的三维关键点。实例语义分割模块由语义分割模块和中心点投票模块组成,前者预测每点语义标签,后者学习每点到对象中心的偏移量,以区分不同的实例。对于每个对象实例,关键点投票模块学习到在MeanShift聚类方式内投票给3D关键点的选定关键点的逐点偏移。
PVN3D中3D关键点选取方法的缺点:由于FPS算法仅考虑欧氏距离,因此选定的点可能出现在非显著区域,例如没有明显纹理的平面。这些点很难检测,估计姿态的精度降低。
为了充分利用物体的纹理和几何信息,该文提出了一种简单而有效的3D关键点选择算法SIFT-FPS。具体来说,使用SIFT算法检测纹理图像中不同的2D关键点,然后将其提升到3D。然后应用FPS算法选择其中的前N个关键点。这样,选定的关键点不仅均匀分布在对象表面上,而且纹理独特,易于检测。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 1
1 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)