【论文精读】Bipartite network projection and personal recommendation
【论文精读】Bipartite network projection and personal recommendation
一、Introduction
在过去的几年里,人们对复杂网络进行了大量的研究,一类特殊的网络是二部网络(bipartite network)。特点是其节点可分割为两个互不相交的子集X和Y,连接只允许存在于不同集合中两个节点之间。例如人类的性别网络由男人和女人组成;代谢网络由化学反应和化学物质组成。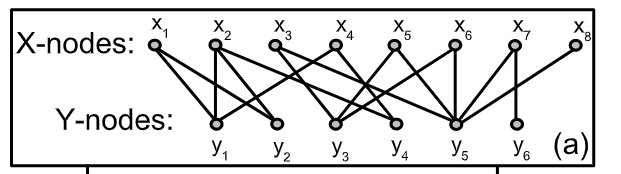
在二部图网络中,有两类需要特别关注。
第一是所谓的协作网络(collaboration network),它通常被定义为通过共同的协作行为连接的要素网络。例子有很多,包括通过共同撰写一篇论文而联系在一起的科学家,共同演绎一部电影的影星等。
第二个被称为意见网络(opinion network),用户集合中的每个节点都与其在目标集合中选择的目标进行连接。例如音乐app用户与他从音乐库中加到自己歌单中的单曲相关联;用户与他收藏的页面书签相关联;网购书籍顾客和他所购买的书籍相关联。
为了便于直接显示一组特定节点之间的关系,二部网络通常采用单模投影法(one-mode projection) 进行压缩。X上的单模投影(简称X投影)是指只包含X节点的网络,其中当两个X节点至少有一个公共相邻Y节点时,它们是相连的。下图是X投影和Y投影的结果(带权重)。
(如果采用最简单的投影方式,将其投影到一个不带权重的网络unweighted network,也就是说不考虑和做的重复频率,这样会造成大量信息的丢失。例如有两个音乐app的用户,他们都加入到“我喜欢”歌单中100多首歌曲,其中有1首相同歌曲和有100首相同歌曲的不带权重的投影结果都是同一网络,无法得出这两个用户究竟有无共同爱好。)
而带权重的网络包含的信息比不带权重网络的信息多,最简单的权重方式就是重复次数,如下图(b)和(c)。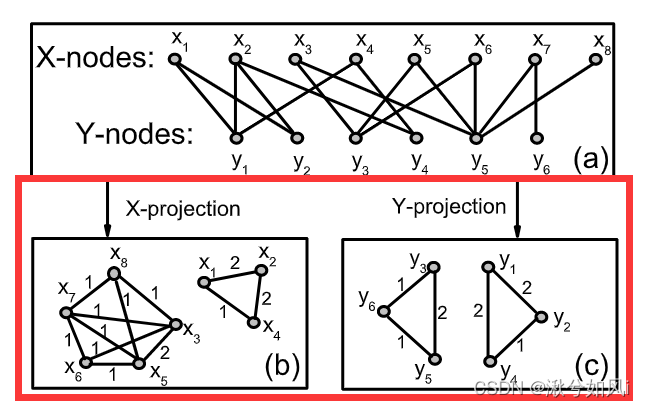
但有时权重也不能简单的用重复频率表示,例如对于论文的联合作者这个例子来说,如果有两个作者之前共同发表过100篇论文,他们又发表了一篇,影响力就没那么大。不如有另外两个作者,他们之前之共同发表过一篇文章,现又共同发表了一篇,研究表明后者的影响力应该比前者大。
基于此,此篇文章提出了一种权重不对称和允许自连接的加权方法。该方法可以直接应用于个人推荐算法,其性能明显优于目前广泛使用的全局排名法(GRM)和协同过滤(CF)。
二、Method
以此图为例,由于二分网络本身是未加权的,所以任意X节点中的资源应该均匀地分配给与它连接的Y节点。类似地,任何Y节点中的资源都应该均匀地分配给与它连接的X节点。如下图(a)所示,三个X节点最初被分配权重x、y和z。资源分配过程包括两个步骤;首先从X到Y,然后回到X。
下面我总结详细过程: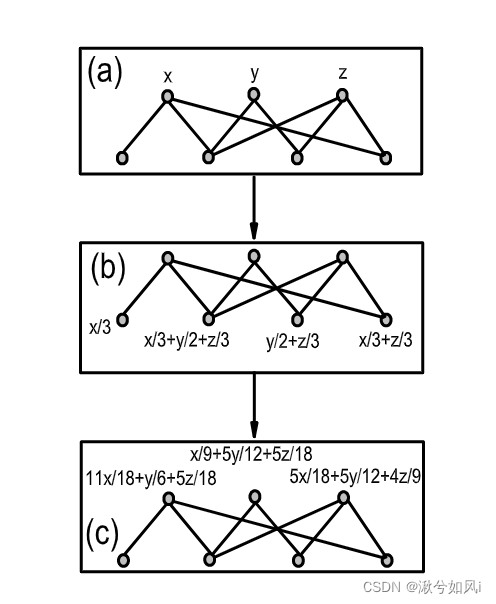
我们先假定X节点从左到右分别是w1,w2,w3。Y节点从左到右分别是v1,v2,v3,v4
- 与第一个X节点相连的Y节点有3个,所以这三个节点各自被分配了x/3。y和z同理,分配完毕后如图(b)
- 第二步再由Y节点分配回X节点。(b)中v1只与w1相连,所以x/3全部分配给w1。而v2与w1,w2,w3都相连,所以只能将资源的三分之一分给w1,也就是x/9+y/6+z/9。v3没有和w1相连,不分配资源。v4与w1,w3都相连,所以只能将资源的二分之一分为w1,也就是x/6+z/6。那么w1所分配到的x资源为x/3+x/9+x/6 = 11x/18,y/6, 和z/9+z/6 = 5z/18
- 对于w2和w3都是上述步骤,最终资源分配结果如图(c)
- 最终分配到的资源也可以用下图矩阵来表示,x,y,z经过分配变为了x’,y’,z’
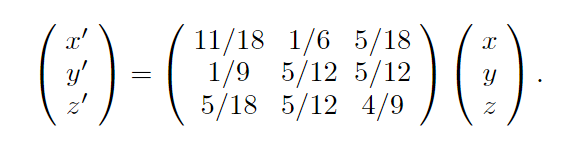
对于一般的二部网络G(X,Y,E),E代表连接两节点的边。假设有n个X节点,m个Y节点。假设第i个X节点的起始资源是f(xi)
第一步后,第l个Y节点上的资源如下公式表示: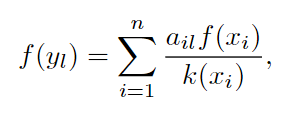
其中ail是一个n×m的邻接矩阵,xi和yl有边连接则ail为1,否则为0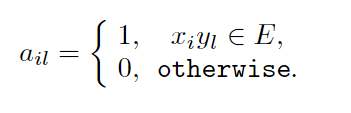
第二步,所有资源又流回X节点,第i个X节点的最终资源量可以用以下公式表示: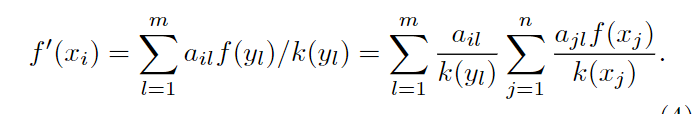
也可以写成: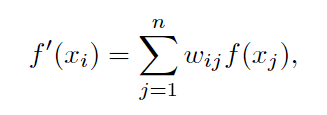
其中:Wij也就是权重矩阵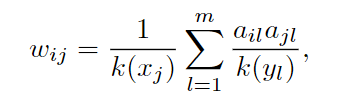
三、个性化推荐(PERSONAL RECOMMENDATION)
在当今这个信息爆炸的时代,想要检索自己需要的信息十分困难。搜索引擎可以帮助解决这个问题,但搜索引擎没有考虑个性化,每个人检索的结果都是一样的,然而每个人的需求却是不同的。
所以,个性化推荐更高效。例如你在京东买了一本关于经济学的书籍,它就会更你推荐更多经济学领域的其他书籍。推荐系统也被广泛应用于电影推荐,音乐推荐等。
介绍个性化推荐算法略。
作者提出了一种Network-based inference (NBI)推荐算法,直接运用了上述提到的带权重的二部图网络。步骤如下:
- 首先通过对象投影(object-projection)压缩"用户-对象"二部图网络,得到带权重的网络G。
- 对每一个用户ui,根据其收集的对象给他分配资源,简单起见,如果对象oj被用户ui收集,初始资源是单位资源,否则初始资源是0。(这里的收集方式有很多,例如用户将喜欢的歌曲加到歌单中)这样一来,每个用户的初始资源都是不同的,因为他们收集的对象都是不同的,从而实现了个性化推荐。
最终,每一个对象的资源量由以下式子表示(同上讨论)。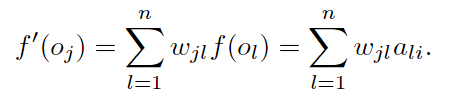
- 对于每一个用户ui,将他没有收集过的对象,按照资源量降序排序。资源量最高的几个对象就是要推荐给该用户的结果。
结论
实验使用了MovieLens数据集来检验算法的性能。该数据集包括1682部电影和943个用户,其实是一个评分系统,用户可以给每部电影评分1-5分 MovieLens数据集下载地址 http://www.grouplens.org
文章使用了一种粗粒度的方法来判断用户和电影直接的关系:当且仅当用户给一个电影评分大于等于3时,才算做一个关联(collect 可以看做是收藏)。 原始数据包含100000个评分,有85.25%大于等于3, 因此用户-电影构成的二部图共有85250条边。为了测试推荐系统,将85250条边随机分成两部分,90%作为训练集,10%用来验证结果。
GRM, CF and NBI(本算法)都能给每个用户提供一个他没有收藏的电影的排序列表(应该是算法推荐给用户的电影,可能性从高到低)。对任意一个用户Ui,如果边Ui - Oj在测试集中,我们记录下Oj在推荐列表中的位置(看他是第几个)。例如Ui用1500个没有收藏的电影,Oj位于第30位,那么我们把Oj的位置记做30/1500,也就是rij = 0.02。 越小的rij能代表更好的推荐。 实验结果是NBI在三个算法中表现的最好。
另一指标是命中率,同样优于另外俩算法。假设算法得出的推荐电影列表长度为L,如果Ui - Oj在测试集中,则代表Ui - Oj命中。所有命中的边除以推荐列表的长度即代表命中率。 (注意:如果L大于用户未收藏的电影数量,那么L用该用户所有未收藏的电影数量表示,推荐列表是根据其他用户得来的)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)