自注意力机制 与 多头注意力机制 代码实现与图解
自注意力机制 与多头注意力机制 代码实现与图解
本文重点通过代码实现来讲解自注意力机制和多头注意力机制的实现,通过代码来透彻理解其原理,同时注意本文在讲解多头注意力机制代码实现的时候,移除了padding_mask和sequence_mask等部分代码实现逻辑,也就是不包含带掩码的多头注意力机制代码实现。
自注意力机制
自注意力机制是 Transformer 架构中的核心组件,它能够让模型在处理序列数据时,动态地关注序列中不同位置的元素,从而更好地捕捉序列内的依赖关系。在自注意力机制中,对于输入的每个元素(通常是词的嵌入向量),都会通过线性变换生成三个新的向量:查询向量(Query)、键向量(Key)和值向量(Value)。
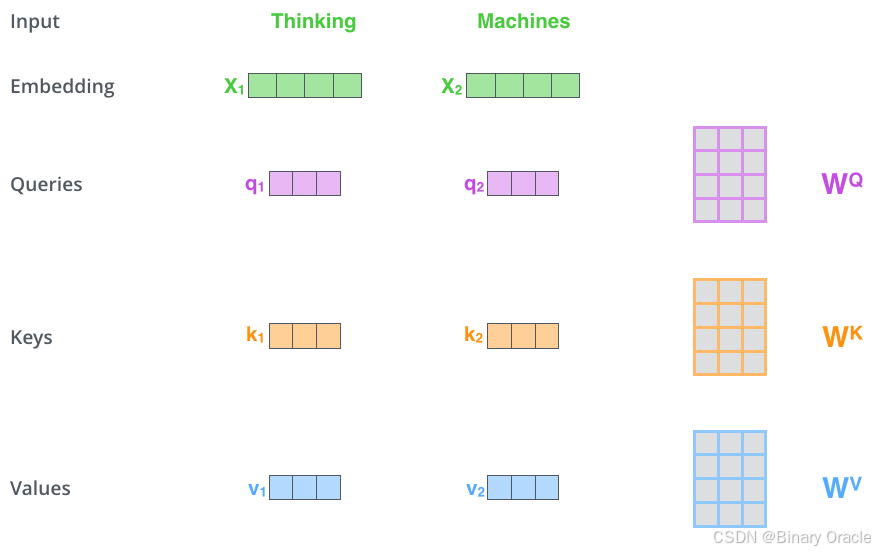
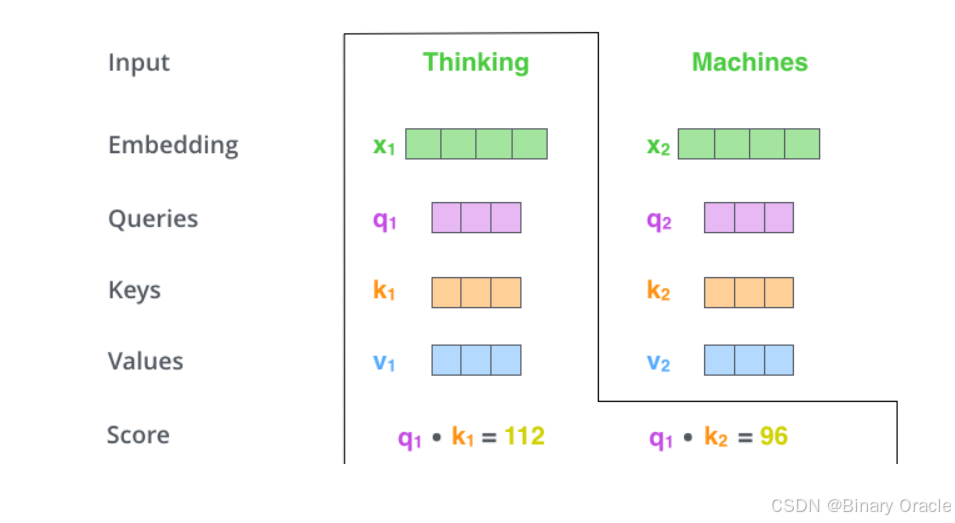
计算self-attention的分数值,该分数值决定了当我们在某个位置encode一个词时,对输入句子的其他部分的关注程度。这个分数值的计算方法是Query与Key做点乘,以下图为例,首先我们需要针对Thinking这个词,计算出其他词对于该词的一个分数值,首先是针对于自己本身即q1·k1,然后是针对于第二个词即q1·k2
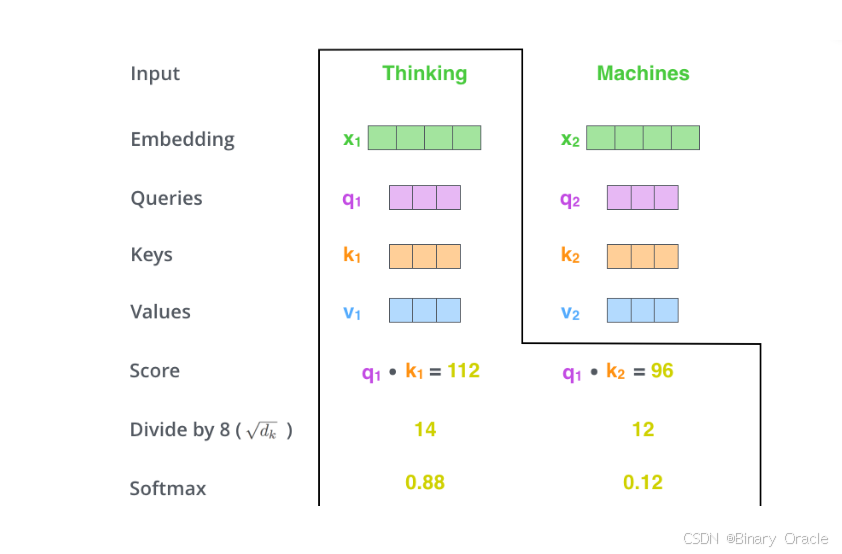
接下来,把点乘的结果除以一个常数,这里我们除以8,这个值一般是采用上文提到的矩阵的第一个维度的开方即64的开方8,当然也可以选择其他的值,然后把得到的结果做一个softmax的计算。得到的结果即是每个词对于当前位置的词的相关性大小,当然,当前位置的词相关性肯定会很大
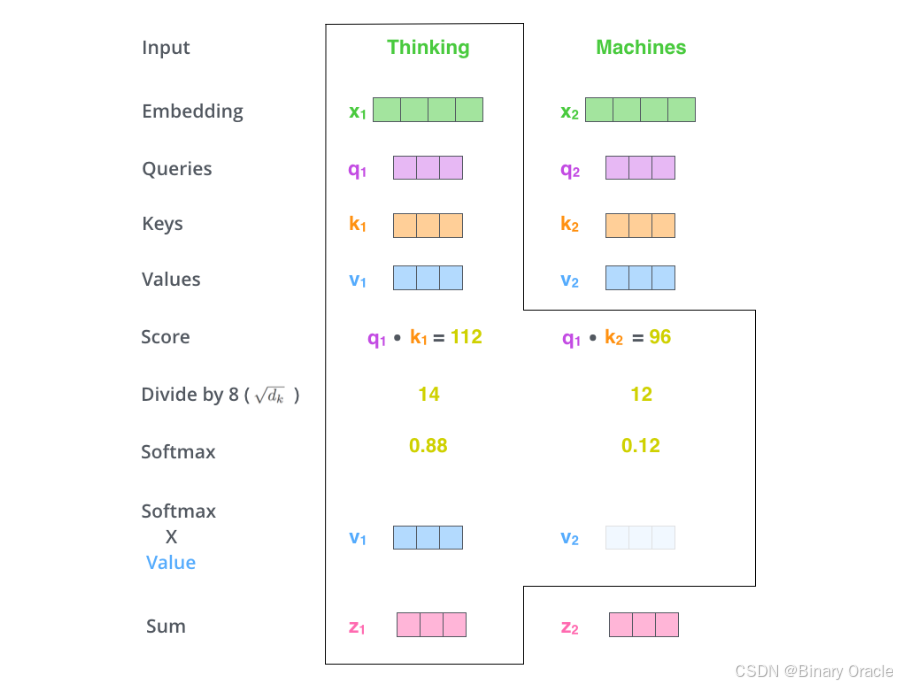
下一步就是把Value和softmax得到的值进行相乘,并相加,得到的结果即是self-attetion在当前节点的值。
在实际的应用场景,为了提高计算速度,我们采用的是矩阵的方式,直接计算出Query, Key, Value的矩阵,然后把embedding的值与三个矩阵直接相乘,把得到的新矩阵Q与K相乘,乘以一个常数,做softmax操作,最后乘上V矩阵
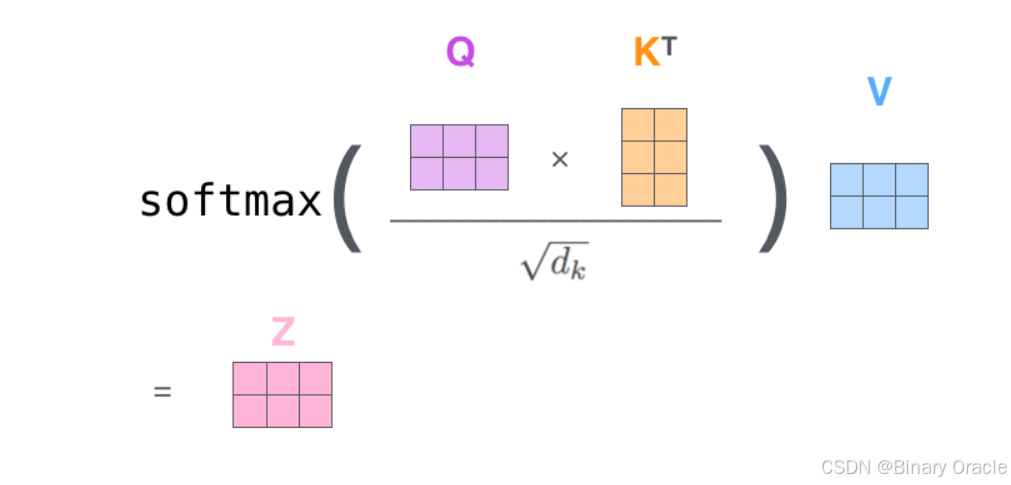
这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
公式如下: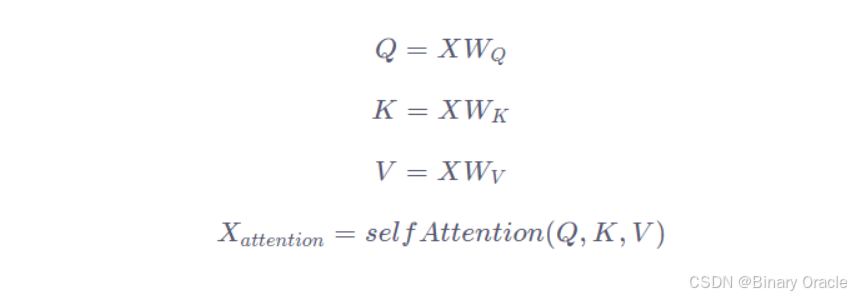
实现代码如下:
import torch
import torch.nn as nn
class MySelfAttention(nn.Module):
def __init__(self, embedding_dim):
super().__init__()
self.wq = nn.Linear(embedding_dim, embedding_dim)
self.wk = nn.Linear(embedding_dim, embedding_dim)
self.wv = nn.Linear(embedding_dim, embedding_dim)
self.wz = nn.Linear(embedding_dim, embedding_dim)
self.embedding_dim = embedding_dim
# x维度(batch_size,seq_len,embedding_size)
def forward(self, x):
# 计算 Q, K, V
Q = self.wq(x)
K = self.wk(x)
V = self.wv(x)
# 计算 Q 和 K 的转置的点积
# torch.bmm 是 PyTorch 中的一个函数,用于执行批量矩阵乘法(Batch Matrix Multiplication)
# 批量矩阵乘法要求输入的两个张量都具有三维形状,并且第一个维度(批量维度)的大小必须相同。
# 假设输入的两个张量分别为 A 和 B,它们的形状分别为 (b, n, m) 和 (b, m, p),其中 b 是批量大小,n、m 和 p 分别是矩阵的行数和列数。
# torch.bmm(A, B) 会对批量中的每一对矩阵进行普通的矩阵乘法,最终输出的张量形状为 (b, n, p)。
QKT = torch.bmm(Q, K.transpose(1, 2))
# 缩放点积
Scale = QKT / torch.sqrt(torch.tensor(self.embedding_dim, dtype=torch.float32))
# 应用 softmax 函数得到注意力分数
Attention_Score = nn.functional.softmax(Scale, dim=-1)
# 计算注意力输出
z = torch.bmm(Attention_Score, V)
# 线性变换
output = self.wz(z)
return output
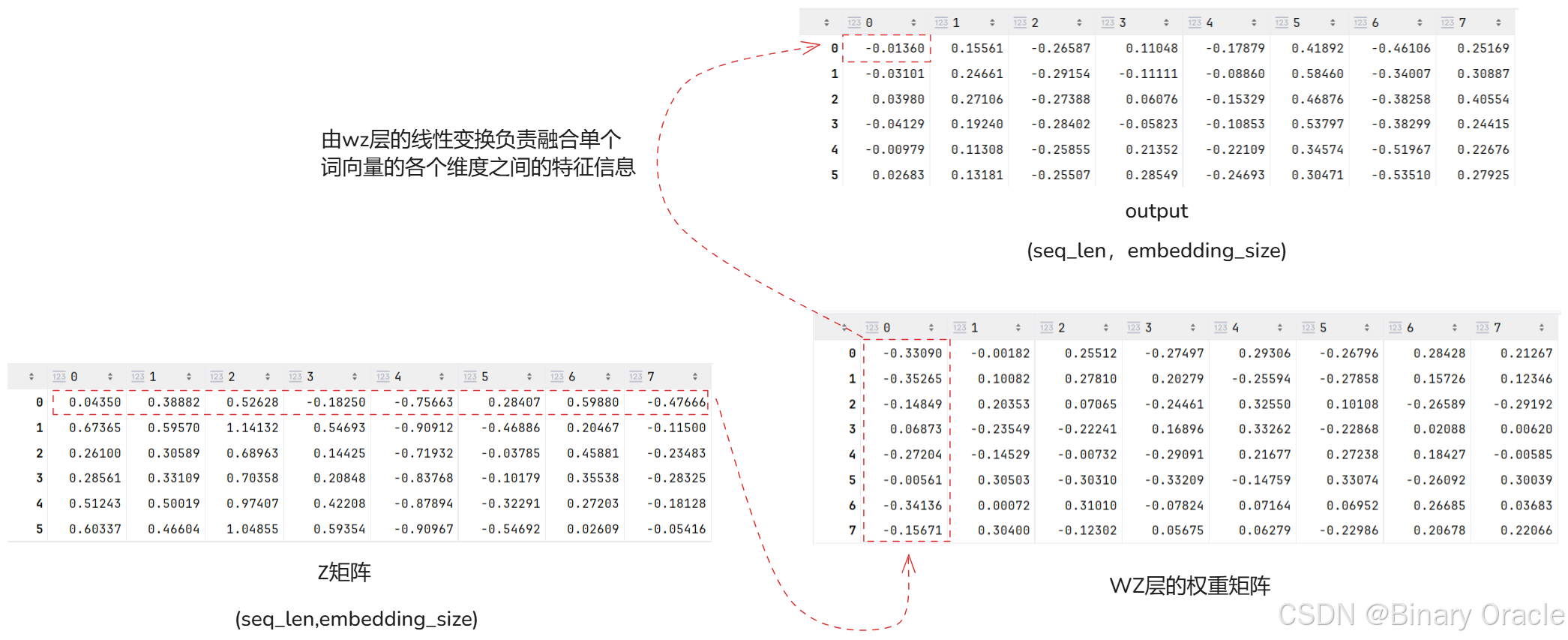
完整运算流程如下图所示(batch_size=1,seq_len=6,embedding_dim=8):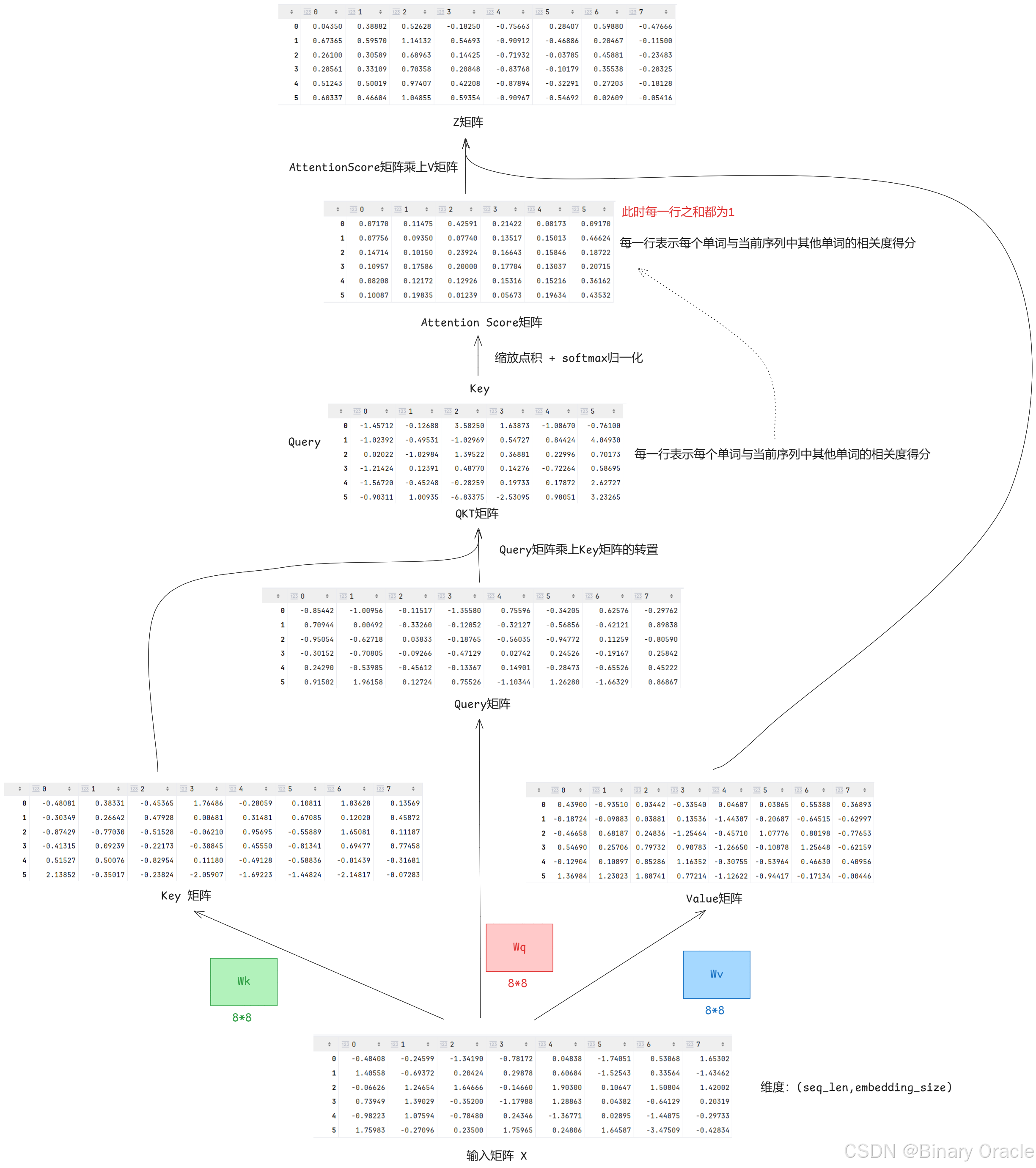
通过Q矩阵与K矩阵转置相乘,得到的QKT过程如下图所示: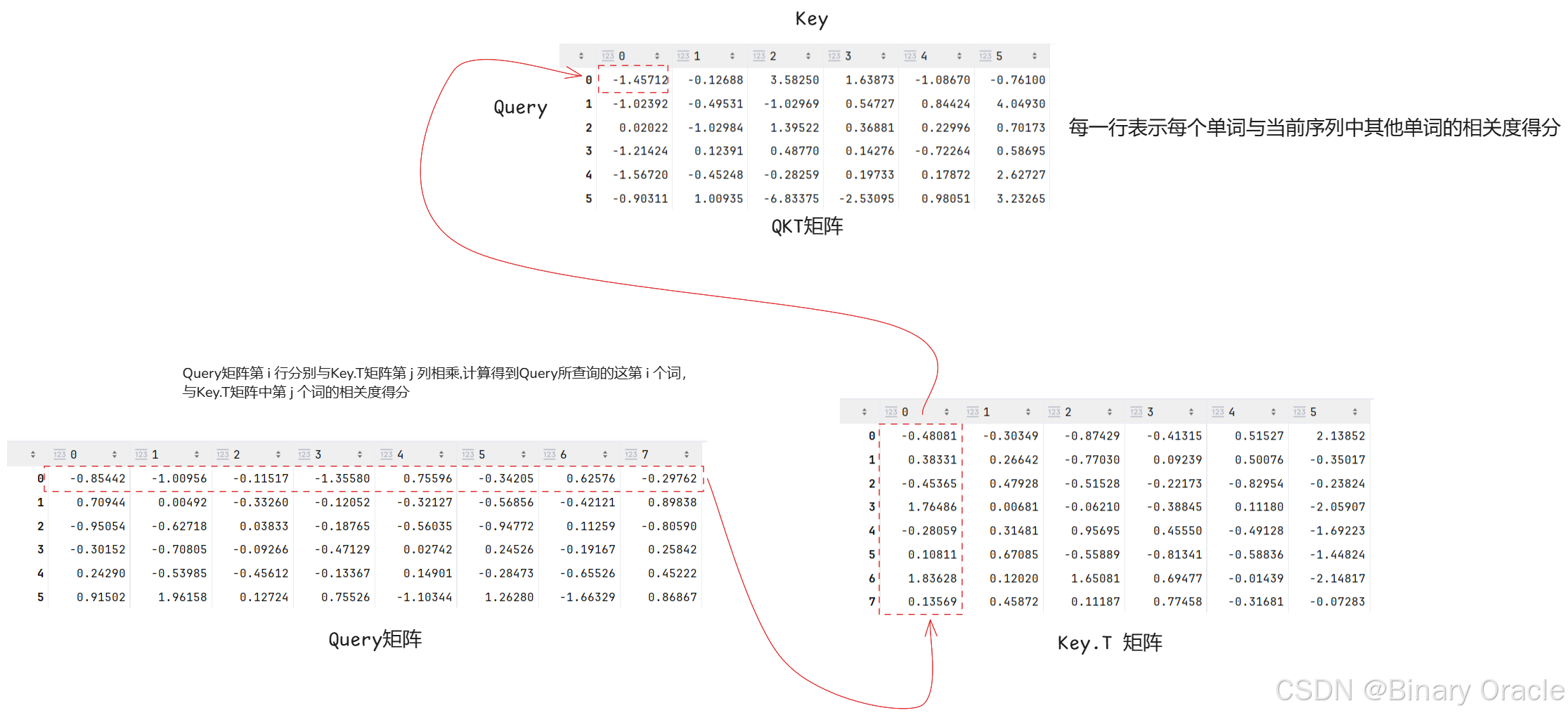
归一化得到Attention Score矩阵后,第0个词对应的词向量需要按照Attention Score矩阵第0行给出的信息融合比例,按对应比例分别从Value矩阵中每个词向量提取信息,也就是将对应比例乘以对应词向量中每个分量,然后通过加法操作融合在一起,具体过程如下图所示:
信息融合完毕后,得到第0个词融合了上下文信息后的新的词向量表示,作为z矩阵的第0行。
得到z矩阵后,我们还会经历一个线性变换,一种理解是我们已经通过自注意力机制对当前词的向量表示完成了上下文信息的融合,下面需要通过线性变换来挖掘单个词向量各个维度之间的关系,并进行特征抽取和融合:
多头注意力机制
多头注意力机制之所以叫多头,不是多个注意力模块对序列进行多次解读,也不是多个头对序列分而解读,而是多个头对输入的词向量的特征进行分而解读,而且是解读完毕后再cancat一起,映射回原向量空间。所以你一定要明白,多头的初衷不是解决模型效果的!而是解决计算效率的!或者说多头的初衷是解决计算效率的,但是在解决计算效率时,它的解决方式一定程度上也带来了,比如说,增强了模型的表达能力和泛化能力这样的效果。
代码实现如下:
class MyMutilHeadSelfAttention(nn.Module):
def __init__(self, embedding_dim=embedding_dim, num_heads=num_heads, sequence_len=sequence_len):
super().__init__()
self.wq = nn.Linear(embedding_dim, embedding_dim)
self.wk = nn.Linear(embedding_dim, embedding_dim)
self.wv = nn.Linear(embedding_dim, embedding_dim)
self.wz = nn.Linear(embedding_dim, embedding_dim)
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.sequence_len = sequence_len
# qkv=(batch_size,seq_len,embedding_size)
def forward(self, q, k, v):
output = []
# 第一维是batch_size,我们分别处理每个序列,可以理解为分别处理每句话
for i in range(q.shape[0]):
# q[i]维度: (seq_len,embedding_size)
Q = self.wq(q[i])
K = self.wk(k[i])
V = self.wv(v[i])
# 存储多头中每个头最终融合v中某段维度后的结果
z_per_head = []
# 计算切片跨度,如果是8个头,嵌入向量为64维,则每个头分到8维
step = int(self.embedding_dim / self.num_heads)
# 依次对每个头进行自注意力机制的运算,但是每个头只会对分给自己的维度部分去做自注意力机制运算
for h in range(0, self.embedding_dim, step):
QKT = torch.mm(Q[:, h:h + step], K[:, h:h + step].t())
Scale = QKT / torch.sqrt(torch.LongTensor([step]))
Attention_Score = nn.functional.softmax(Scale, dim=-1)
# 每个头负责分配权重并融合V矩阵中部分维度的信息
z = torch.mm(Attention_Score, V[:, h:h + step])
z_per_head.append(z)
# 将所有维度信息拼接在一起作为最终融合后得到的结果
z = torch.concat(z_per_head, dim=1)
# wz的权重矩阵维度为(64,64),利用线性变换融合单个词向量中各个维度特征的信息
re = self.wz(z)
# 一个序列信息融合处理完毕,处理批次中下一个序列
output.append(re)
return torch.stack(output, dim=0)
完整运算流程如下图所示(batch_size=1,seq_len=6,embedding_dim=8,num_heads=2):
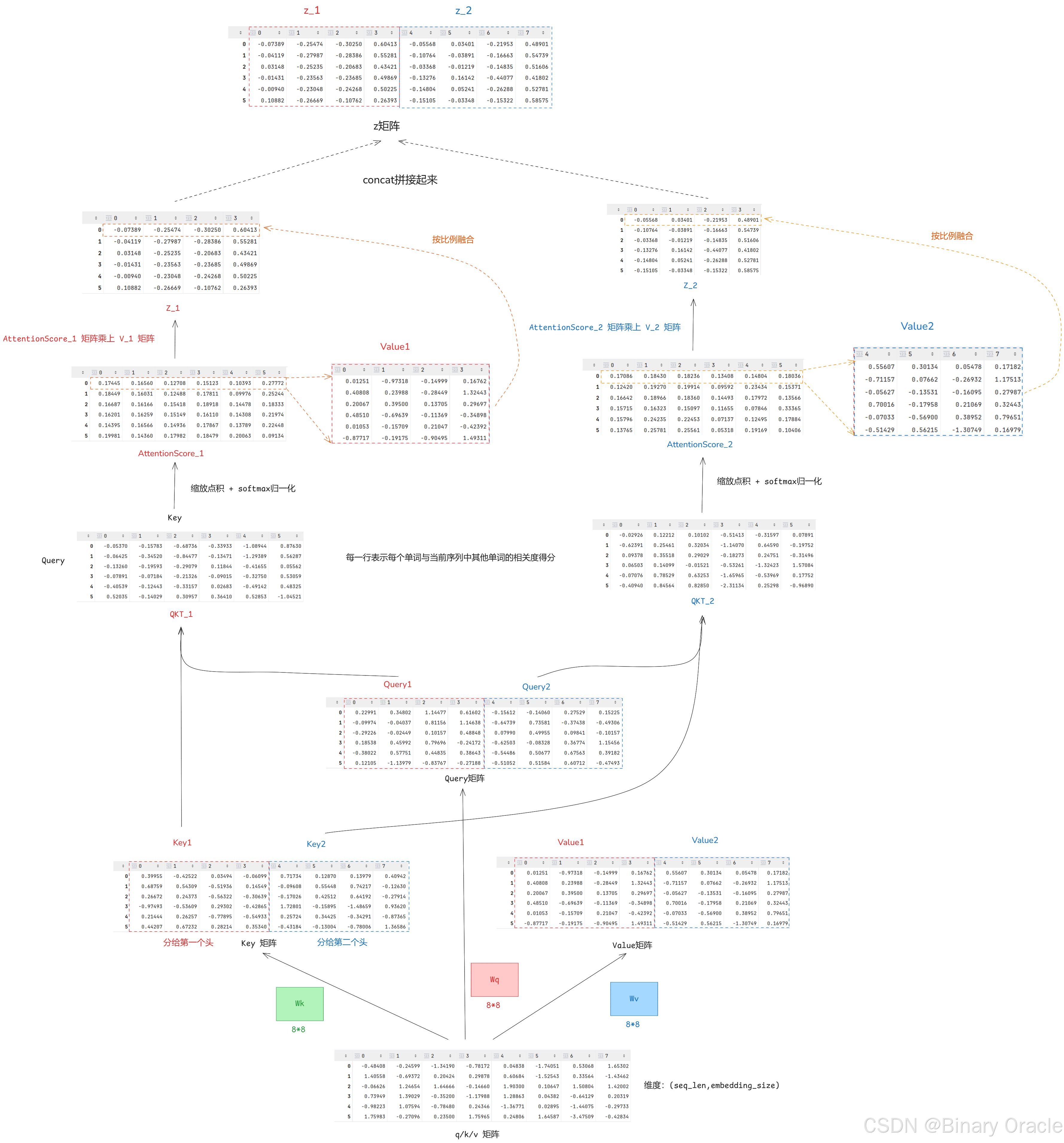
通过图解大家也可以看出来,多头注意力机制之所以叫多头是因为,把QKV在词向量的特征维度空间给分隔了,然后分而治之。分隔几段就是几头,然后每个头就各种计算自己的注意力分数,各自求自己对应的那部分数据的z,然后把所有头的z横向拼接,再用一个线性层输出

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)