自研算法提升文本图像篡改检测精度,抖音技术团队获 ICDAR2023 分类赛道冠军...
动手点关注干货不迷路近日,抖音 CV 技术团队在 ICDAR 2023 的“Detecting Tampered Text in Images”比赛中,利用自研的“CAS”算法从 1267 个参赛队伍中脱颖而出,获得分类赛道的第一名。ICDAR(International Conference on Document Analysis and Recognition),是国际文档图像分析和识别领域
动手点关注

干货不迷路
近日,抖音 CV 技术团队在 ICDAR 2023 的“Detecting Tampered Text in Images”比赛中,利用自研的“CAS”算法从 1267 个参赛队伍中脱颖而出,获得分类赛道的第一名。
ICDAR(International Conference on Document Analysis and Recognition),是国际文档图像分析和识别领域公认的权威学术会议,涉及的领域包括文本识别、文本检测、文档分析和自然语言处理等。该会议从 1991 年开始,每两年举办一次,吸引了来自全世界的科学家、工程师和学者参加,分享他们的研究成果和最新技术进展。第 17 届将于 2023 年 8 月在美国加利福尼亚举行。
DTT 竞赛聚焦于真实场景下的文本图像篡改检测。随着文档分析与识别领域的快速发展,新兴技术也在不断涌现,并广泛应用于数字金融、电子商务、安全审核和智慧教育等领域。然而,以往的研究大多集中于文本内容的理解,对于图像本身的真实性关注度较低。与通常针对自然图片中人或物的篡改检测不同,文本的篡改检测在精度和泛化性方面更具挑战性。首先,篡改的区域通常很小,几个字符的改动即可导致整体语义的扭曲,且由于背景缺乏复杂的纹理,篡改区域与邻近区域之间也没有明显的差异。
竞赛简介
竞赛数据集共收录了 19000 张通过拍摄、扫描和截图等多种方式在真实场景下采集到的文本图像,并使用人工修图或者机器合成等方式对部分图片进行了包括复制粘贴,替换和擦除等不同类型的篡改。比赛任务是训练一个分类器,判断测试集中的图片是否经过篡改。
图1. 训练样本
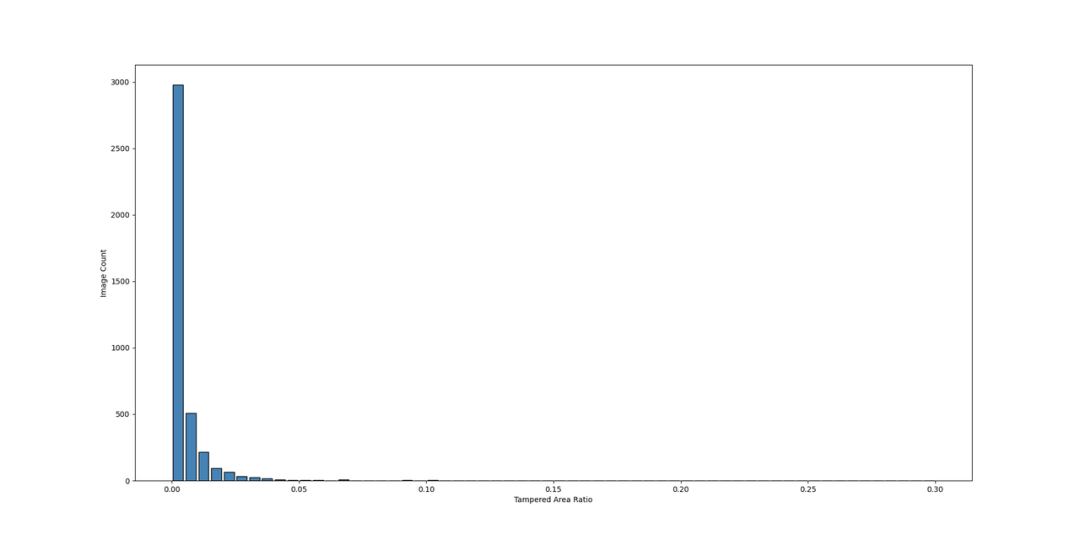
图2. 篡改区域面积占比分布直方图
赛程分两个阶段:
-
初赛阶段提供训练集和初赛测试集。训练集包含图片以及分割和分类的标签,测试集仅包含图片。该阶段,参赛选手直接提交预测结果计算得分,为期 35 天,每个队伍 1 天最多提交 5 次。
-
初赛排名前 30 的队伍进入复赛,为期 6 天。复赛阶段测试集不公开,入围选手每次可提交 1 次 Docker 镜像,由主办方负责执行推理并计算得分。取复赛阶段的最高分作为最终的成绩。
参赛方案
针对数据集中篡改类型多、前景区域小且训练数据量少等特点,对传统分类方案进行了以下改进:
-
通过引入第三方数据集和在线生成等多种方式扩充训练样本,以数据驱动替代模型驱动,提高泛化能力。
-
设计了"Classification After Segmentation"的二阶段分类器,兼顾 CNN 和 Transformer 的不同特性并加以融合,最大程度地发掘不同层级的图像信息。
-
使用在高分辨率的原图上进行滑窗的采样方式,在算力和资源有限的情况下,尽可能地保留图片的整体语义和局部细节。
数据扩充
除了引入多个篡改检测的开源数据集扩充样本数量,在训练阶段也使用了在线合成的方式生成篡改图片,提供了丰富的训练数据。常用的篡改方式包括局部擦除、相同图片不同区域之前的复制黏贴,以及不同图片区域的替换等。由于比赛主要针对文本区域的篡改,因此在合成数据之前需要先进行文本检测区分字符和背景。同时为了更贴近真实的场景,除了对图片进行简单篡改之外,还需要使用各种后处理消除篡改痕迹。例如,随机尺度的缩放、二次 JPEG 压缩、图像模糊和随机噪声等。
模型结构
借鉴了图像篡改检测中常用的不同类型特征的融合方案,团队创新性地设计了一个先分割后分类(Classification After Segmentation)的结构,将浅层篡改痕迹的感知和抽象文本语义的理解进行解耦,并在后续阶段融合不同层级的视觉概念,从而尽可能丰富地发掘图像信息。分割阶段使用 CNN 作为编码器进行局部信息的捕捉,同时采样和 UperNet 类似的特征金字塔结构,进行像素级热力图的生成,并与原图进行合并,作为后续分类模型的输入。而相较于 CNN,Transformer 的自注意力机制更适合高层特征的提取和抽象语义的理解,因此在分类阶段使用 Transformer 作为编码器,进行全图标签的预测。
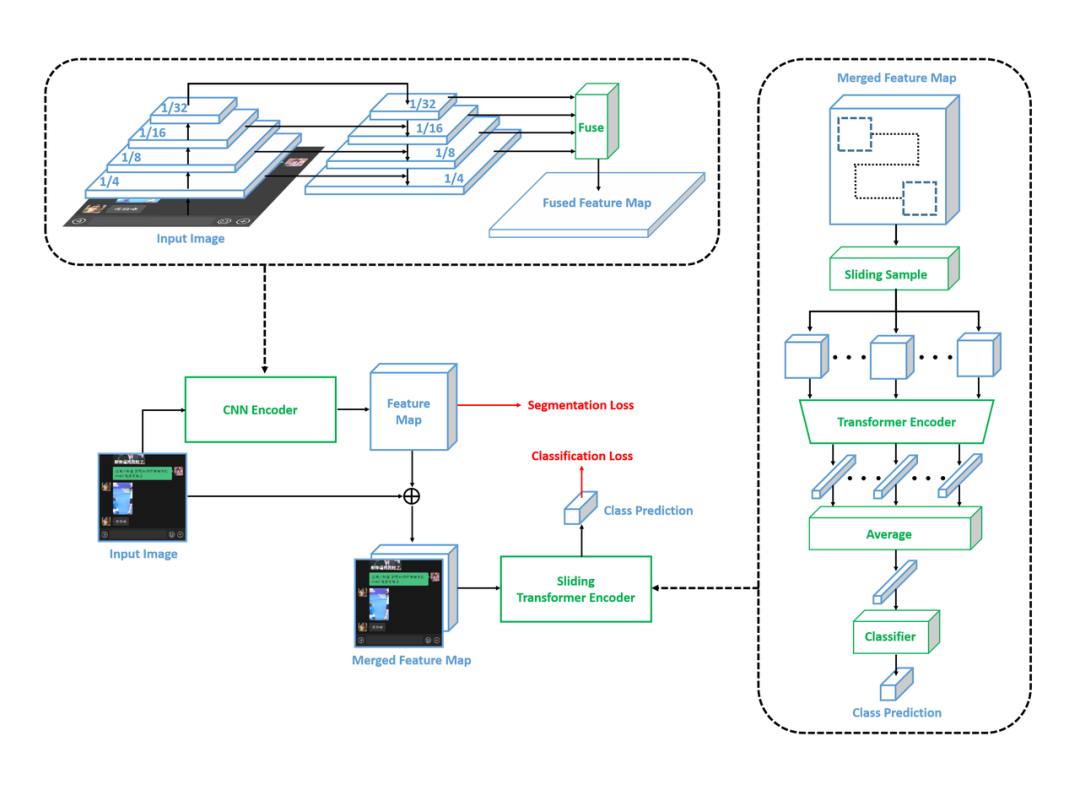
图3. CAS 结构图
考虑到目标区域较小,对原图进行缩放会造成篡改痕迹的损坏,不利于模型的收敛。同时,由于比赛中对于模型的算力和显存占用存在限制,因此无法直接使用原始尺寸进行推理。为了最大程度地保留图片信息,采样了滑窗采样的方式进行训练和推理。在图像分割领域,滑窗推理原本就是一个常用的技巧,因此第一阶段也沿用了相同的采样策略。而第二阶段,在编码过程中,先使用滑窗对原图不同区域进行特征提取和全局池化。随后将所有区域的特征向量进行融合,生成全图特征后再使用分类器进行解码,得到二分类的预测结果。
对于图像分割,使用 dice loss 往往能够有效提高模型的性能,但是也存在梯度变化剧烈,导致训练不稳定的风险。因此分割阶段采用 BCE loss 和 dice loss 相结合的方式,保证训练稳定的情况下提升模型性能。同时由于正负区域的面积差异过大,还采用了像素级的 OHEM(在线难例挖掘)样本平衡策略加速模型的收敛。分类阶段,则使用常规的交叉熵作为损失函数。同时,也尝试引入了多分类模型常用的标签平滑。实验证明,即使是在二分类场景,适当的标签平滑也能够有效地提升模型性能。
实验中发现,使用相同的数据进行端到端的训练容易导致下游分类模型对上游分割生成的热力图过拟合,从而降低模型的泛化能力。因此采用二阶段训练策略:在第一阶段,使用多种数据扩充的方式生成丰富的训练样本,训练一个"通用"的分割模型,提高上游的泛化能力;第二阶段,固定分割部分的权重,仅使用比赛的数据集微调下游的分类模型,提高整体性能。
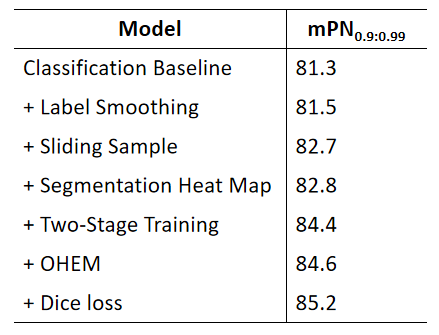
图4. CAS 消融实验
结果融合
训练阶段尝试了不同的骨干网络,发现并非更深的网络和更多的参数就能取得最优的性能。考虑到复赛阶段对于推理时间的限制,最终选取了 3 个性能高且耗时低的模型在推理阶段进行融合。同时,为了获得更鲁棒的性能,在推理过程中,对测试图片进行水平翻转,并将翻转前后的结果进行融合计算最终的预测分数。上述的提及的两种融合都统一采用了加权平均的方式。实验证明,激活前融合的效果通常优于激活后融合。即通过线性分类器对特征进行映射后,先进行融合再使用 softmax 计算分数的方式性能更佳。
图5. 局部篡改检测示例
除此之外,利用训练集和测试集中存在数据同源(基于同一张图片进行不同方式的篡改)的情况,通过对比同源图片的差异,也能够获取可靠的局部篡改信息。首先经过特征提取并计算余弦相似度进行全图匹配,获取候选的参考图片。随后使用 ECC(Enhanced Correlation Coefficient)进行图像配准,在对齐后的图像上计算局部差异,并过滤噪声后获得篡改信息。结合参考图片的标签和篡改信息进行打分,最终根据置信度更新预测结果。

图6. 获奖证书
关于抖音 CV 团队
抖音 CV 技术团队是抖音集团旗下的计算机视觉算法团队。通过不断产出业界前沿的深度学习模型,团队保障了抖音、西瓜、头条等多业务推荐系统和内容生态的安全发展。自成立以来,团队一直坚持底层创新,建设业界前沿的视觉表征、内容理解、真伪鉴别等解决方案,曾获得多项国际级技术赛事冠军。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)