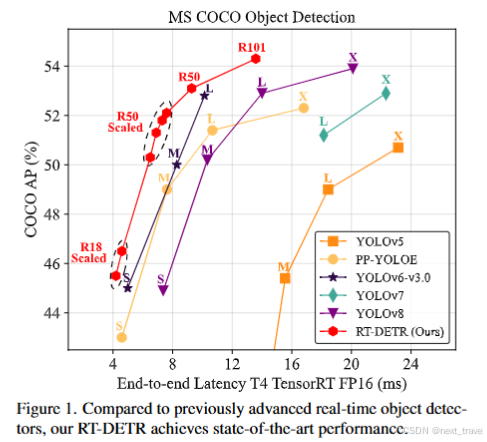
RT-DETR
摘要
本周看了一篇《DETRs Beat YOLOs on Real-time Object Detection》设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来提高速度来快速处理多尺度特征;同时提出了不确定性最小查询选择来为解码器提供高质量的初始查询,从而提高准确率。此外,RT-DETR通过调整解码器的数量来适应各种场景而无需重新训练来支持灵活的速度调整。它不仅在速度和准确性上都优于之前先进的 YOLO 检测器,而且还消除了 NMS 后处理对实时对象检测的负面影响。
abstract
This week I read an article “DETRs Beat YOLOs on Real-time Object Detection”, which designed an efficient hybrid encoder to rapidly process multi-scale features by decoupling intra-scale interaction and cross-scale fusion to improve speed; At the same time, the uncertainty minimum query selection is proposed to provide the decoder with high quality initial query and improve the accuracy. In addition, RT-DETR supports flexible speed adjustment by adjusting the number of decoders to suit various scenarios without the need for retraining. It not only outperforms previous advanced YOLO detectors in both speed and accuracy, but also eliminates the negative impact of post-NMS processing on real-time object detection.
RT-DETR
在上周学习的DETR模型中其消除了手工制作的描点和NMS组件。相反,它采用了二分匹配并直接预测一对一的对象集。尽管DETR具有明显的优势,但存在一些问题:训练收敛慢、计算成本高、查询难以优化等。由此RT-DETR的创新点:首先,设置一个高效的混合编码器来替代普通的Transformer解码器,通过解耦不同尺度特征的尺度内交互和跨尺度融合,显著提高了推理速度。其次,为了避免选择定位置信度较低的编码器特征作为对象查询,提出了不确定性最小查询选择,通过显示优化不确定性为解码器提供了高质量的初试查询,从而提高准确性。最后,由于 DETR 的多层解码器架构,RT-DETR == 支持灵活的速度调整以适应各种实时场景而无需重新训练。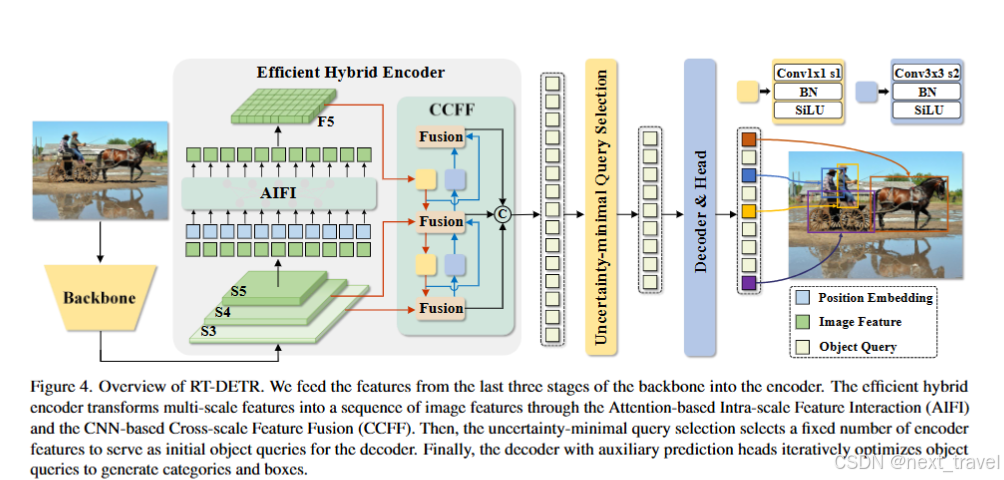
上图中将骨干网络的最后三个阶段的特征输入编码器中。高效的编码器通过基于注意力的尺度内特征交互(AIFI)和基于CNN的跨尺度特征融合(CCFF)==将多尺度特征转换为图像特征序列。在通过不确定性最小查询选择固定数量的编码器特征作为解码器的初始对象查询。最后,通过具有辅助预测头的解码器迭代优化对象查询来生成类别和框。
注意力的尺度内特征交互(AIFI)
核心思想:
尺度内特征交互是指在同一特征尺度内进行局部或全局的信息交互,提高特征表达能力。AIFI使用注意力机制(通道注意力机制和空间注意力)对特征进行加权处理,使模型能够更加关注特征图中对检测任务重要的区域。
- 输入网络来自骨干网络生成的多层特征(S3、S4、S5)
- 在每个特征层内,AIFI使用注意力机制:(空间维度、通道维度)
- 融合后的特征会在同一尺度内进行进一步传递
基于CNN的跨尺度特征融合(CCFF)
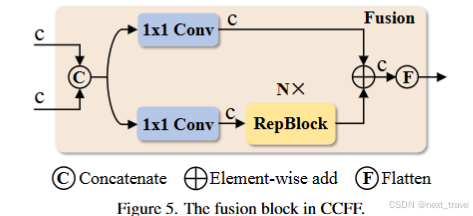
核心思想:
跨尺度特征融合通过卷积操作将不同分辨率的特征图(S3、S4、S5)融合到一起,使得模型能够同时捕捉小目标的细节和大目标的全局语义信息。
- 特征上采样:将低分辨率特征(深层,S5)上采样到与高分辨率特征对齐。
- 特征下采样:将高分辨率(浅层,S3)下采样到低分辨率特征的大小。
- 融合操作:通过卷积操作(逐点卷积+标准卷积)对多尺度特征进行加权融合,统一输出。
- 结果处理:融合后的特征通过标记为fusion节点输入到后续的模块中。
上述CCFF模块中,RepBlock(Re-parameterization Block)是一种基于重参数化思想的结构。在训练阶段采用跟复杂的网络结构(如多分支结构),以增强特征学习能力;而在推理阶段,通过结构重参数化,将多分支结构等价的替换为单分支结构,而从大幅度提高推理速度。
不确定性最小查询
核心思想:
不确定性最小查询是一种优化目标查询机制的方法,旨在选择最有可能代表目标的查询,减少无效查询,提高检测效率。
- transformer编码器的输出中,不同的目标查询向量可能存在不确定性差异。
- 通过不确定性度量方法(基于分类置信度或定位偏差),选择不确定最低的查询。
- 仅将这些有效查询传递到Transformer解码器,减少冗余计算。
变体编码器结构
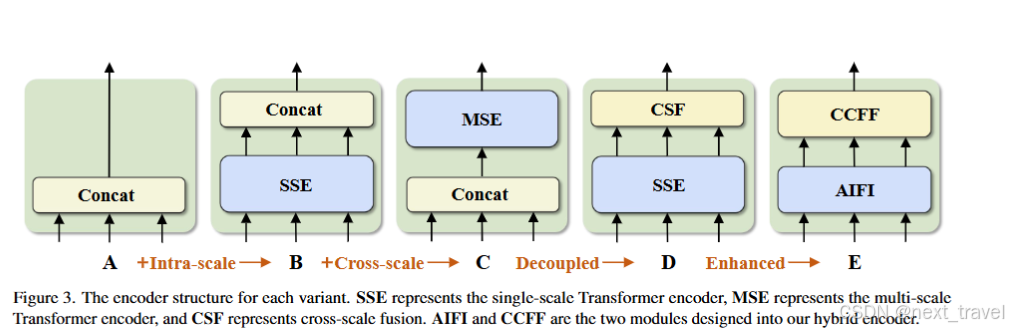
- A → B:变体 B 将单尺度 Transformer 编码器插入到 A 中,它使用一层 Transformer 块。多尺度特征共享编码器进行尺度内特征交互,然后concat作为输出。
- B → C:变体 C 引入了基于 B 的跨尺度特征融合,并将拼接的特征馈送到多尺度 Transformer 编码器以执行同时尺度内和跨尺度特征交互。
- C→D:变体D将尺度内相互作用和跨尺度融合解耦,前者采用单尺度Transformer编码器,后者采用 PANet-style风格的结构。
- D→E:变体E在D的基础上增强尺度内相互作用和跨尺度融合,采用我们设计的高效混合编码器。
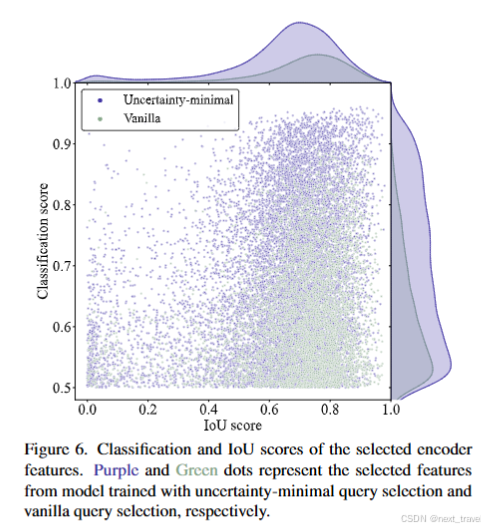
点越接近图右上角,对应特征的质量越高,即预测类别和框越有可能描述真实对象。图上面和图右侧密度曲线反映了两种类型的点数。散点图最显着的特点是紫色点集中在图的顶部,而绿色点集中在右下角。这表明不确定性最小查询选择会产生更高质量的编码器特征。
实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet50
# -------------------- Backbone --------------------
class Backbone(nn.Module):
def __init__(self):
super(Backbone, self).__init__()
resnet = resnet50(pretrained=True)
self.stage1 = nn.Sequential(*list(resnet.children())[:4])
self.stage2 = nn.Sequential(*list(resnet.children())[4])
self.stage3 = nn.Sequential(*list(resnet.children())[5])
self.stage4 = nn.Sequential(*list(resnet.children())[6])
def forward(self, x):
s1 = self.stage1(x) # Low-level features
s2 = self.stage2(s1)
s3 = self.stage3(s2)
s4 = self.stage4(s3)
return s3, s4 # Multi-scale features
# -------------------- Attention Interaction Feature Integration (AIFI) --------------------
class AIFI(nn.Module):
def __init__(self, in_channels):
super(AIFI, self).__init__()
self.attention = nn.MultiheadAttention(embed_dim=in_channels, num_heads=8)
def forward(self, x):
# Reshape for attention: (B, C, H, W) -> (HW, B, C)
B, C, H, W = x.shape
x = x.flatten(2).permute(2, 0, 1)
x, _ = self.attention(x, x, x)
# Reshape back: (HW, B, C) -> (B, C, H, W)
x = x.permute(1, 2, 0).reshape(B, C, H, W)
return x
# -------------------- Cross-Scale Feature Fusion (CCFF) --------------------
class CCFF(nn.Module):
def __init__(self, in_channels):
super(CCFF, self).__init__()
self.conv1x1 = nn.Conv2d(in_channels, in_channels // 2, kernel_size=1)
self.conv3x3 = nn.Conv2d(in_channels // 2, in_channels, kernel_size=3, padding=1)
def forward(self, high_res, low_res):
# Upsample low-resolution feature
low_res = F.interpolate(low_res, scale_factor=2, mode="bilinear", align_corners=False)
# Fuse features
fused = self.conv1x1(high_res + low_res)
fused = F.relu(self.conv3x3(fused))
return fused
# -------------------- Decoder --------------------
class TransformerDecoder(nn.Module):
def __init__(self, num_queries, hidden_dim):
super(TransformerDecoder, self).__init__()
self.query_embed = nn.Embedding(num_queries, hidden_dim)
self.decoder_layer = nn.TransformerDecoderLayer(d_model=hidden_dim, nhead=8)
self.decoder = nn.TransformerDecoder(self.decoder_layer, num_layers=6)
def forward(self, memory, pos_embed):
# Generate queries
B, _, H, W = memory.shape
query_embed = self.query_embed.weight.unsqueeze(1).repeat(1, B, 1) # (num_queries, B, hidden_dim)
memory = memory.flatten(2).permute(2, 0, 1) # (HW, B, hidden_dim)
pos_embed = pos_embed.flatten(2).permute(2, 0, 1) # (HW, B, hidden_dim)
# Decode queries
output = self.decoder(query_embed, memory, memory_key_padding_mask=None, pos=pos_embed)
return output
# -------------------- RT-DETR --------------------
class RTDETR(nn.Module):
def __init__(self, num_classes, num_queries):
super(RTDETR, self).__init__()
self.backbone = Backbone()
self.aifi = AIFI(in_channels=1024) # Feature interaction
self.ccff = CCFF(in_channels=1024) # Cross-scale fusion
self.decoder = TransformerDecoder(num_queries=num_queries, hidden_dim=256)
# Prediction heads
self.class_embed = nn.Linear(256, num_classes)
self.bbox_embed = nn.Linear(256, 4) # [cx, cy, w, h]
def forward(self, x):
s3, s4 = self.backbone(x) # Multi-scale features
s4 = self.aifi(s4) # Apply AIFI
fused_features = self.ccff(s3, s4) # Apply CCFF
# Generate position embeddings
B, C, H, W = fused_features.shape
pos_embed = torch.randn(B, C, H, W).to(x.device)
# Transformer decoder
queries = self.decoder(fused_features, pos_embed)
# Prediction
class_logits = self.class_embed(queries) # (num_queries, B, num_classes)
bbox_preds = self.bbox_embed(queries) # (num_queries, B, 4)
return class_logits.transpose(0, 1), bbox_preds.transpose(0, 1)
# -------------------- Example Usage --------------------
if __name__ == "__main__":
# Example input
inputs = torch.randn(2, 3, 224, 224) # Batch size 2, 3 channels, 224x224 image
# Create model
model = RTDETR(num_classes=80, num_queries=100)
# Forward pass
class_logits, bbox_preds = model(inputs)
print("Class logits shape:", class_logits.shape) # (B, num_queries, num_classes)
print("BBox preds shape:", bbox_preds.shape) # (B, num_queries, 4)
总结
RT-DETR提出了一种高效的目标检测方法,凭借混合编码器、注意力的尺度内特征交互(AIFI)以及基于CNN的跨尺度特征融合(CCFF)实现了高效的特征处理和融合。其创新点包括:1)通过解耦尺度内交互和跨尺度融合,显著提升推理速度;2)引入不确定性最小查询选择,为解码器提供高质量的初始查询,提升检测精度;3)支持灵活调整解码器数量以适应不同场景,无需重新训练。这使RT-DETR在速度和准确性上均优于先进的YOLO检测器,同时避免了NMS后处理对实时检测的负面影响。RT-DETR的多尺度特征融合和灵活调整能力为实时目标检测任务提供了强有力的技术支持。
参考文献
链接:https://arxiv.org/abs/2304.08069

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)