基于CEVA DSP BX2的架构分析(二)
CEVA-BX2是一款基于VLIW模型和SIMD概念的DSP。这种方法使处理器能够实现高水平的并行性、低功耗和高代码密度。CEVA-BX2体系结构基于仅使用RISC操作和指令的加载存储计算机体系结构。该体系结构具有专用的加载和存储单元,负责将数据从数据存储器直接加载存储到寄存器。所有其他计算指令始终使用这些寄存器作为源和目标。CEVA-BX2指令集可以是16位、32位、48位或64位宽。这些指令中
目录
3.体系结构概述
3.1 概述
CEVA-BX2是一款基于VLIW模型和SIMD概念的DSP。这种方法使处理器能够实现高水平的并行性、低功耗和高代码密度。
CEVA-BX2体系结构基于仅使用RISC操作和指令的加载/存储计算机体系结构。该体系结构具有专用的加载和存储单元,负责将数据从数据存储器直接加载/存储到寄存器。所有其他计算指令始终使用这些寄存器作为源和目标。
CEVA-BX2指令集可以是16位、32位、48位或64位宽。这些指令中最多可以有四个被分组以形成指令包,该指令包在单个周期中执行。指令包中的每个指令都与核心中的不同功能单元相关联。
3.2 CEVA-BX2方框图
图 2-1个 显示了CEVA-BX2的框图。
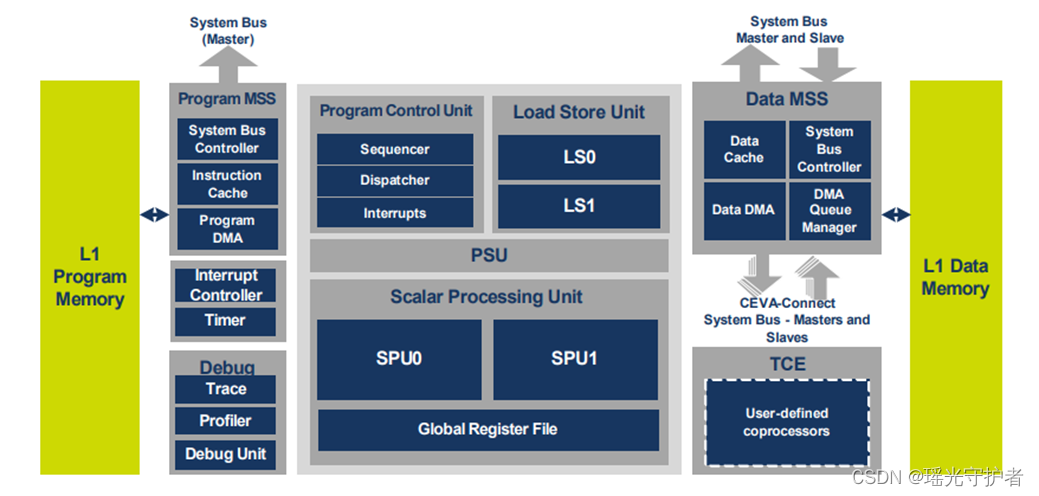
图2-1.CEVA-BX2处理器框图
CEVA-BX2由程序控制单元(PCU)、由两个子单元SPU0和SPU1组成的标量处理单元(SPU)、加载/存储单元(LSU)、功率缩放单元(PSU)、存储子系统(MSS)和调试接口组成。以下各节详细描述了每个CEVA-BX2块。
3.2.1 程序控制单元
程序控制单元(PCU)分为以下子单元:
- 调度器:从程序存储器中对齐指令,并将它们分派到不同的单元。它包括一个指令队列,并管理16位和32位指令对齐。
- 中断处理程序:处理来自中断控制器或内部原因的传入中断,并相应地更改程序计数器和处理器状态。
- 程序定序器:确保正确的程序流,无论是顺序的还是非顺序的。它还管理程序计数器(PC),并对不同类型的不连续指令使用以下机制:
- 分支机制:管理所有分支、循环、子例程调用和子例程返回操作
- 分支目标缓冲区(BTB):最小化流执行更改的惩罚
- Loop Buffer:存储和执行内部缓冲区中的短循环,而不从程序内存中重新获取迭代代码
3.2.2 标量处理单元
标量处理单元(SPU)处理所有标量计算和位操作,并为控制和面向DSP的操作提供有效的OOB C编译器支持。SPU由两个单独的计算子单元组成,分别命名为SPU0和SPU1。子单元是独立的,可以与其他子单元并行执行指令。
算术运算包括加法、减法、比较、最小值、最大值和其他。逻辑运算包括按位与、与、或、不或、排他或、排他的或和其他。位操作操作包括移位、提取等。
此外,SPU可以执行乘法运算和专用运算。乘法运算包括乘法、乘法累加和复数算术。
所有SPU指令都可以使用谓词作为条件。
3.2.3 加载和存储单元
加载和存储单元(LSU)负责所有数据存储器访问。该单元被划分为名为LS0和LS1的两个子单元,它们能够使用各种寻址模式从数据存储器加载或存储数据存储器。
LSU支持每个周期高达128位的负载带宽,并且并行支持每个周期最高128位的存储带宽。
LSU在每个周期中根据以下寻址模式生成两个独立的32位地址(一个用于加载,一个用于存储):
- 间接寻址,包括后期修改
- 使用基址寄存器和立即数或指针进行索引,包括后期修改
- 直接,完全嵌入到指令中(长直接)
- 堆栈,使用堆栈指针(SP)寄存器向软件堆栈推送和弹出
LSU支持在访问后执行的以下类型的地址寄存器修改:
- 线性修改
- 模数修正
所有LSU指令都可以使用谓词作为条件。
存储/加载到数据存储器/从数据存储器加载的数据的源/目标可以是核心通用寄存器文件(GRF)和一些专用寄存器中的任何一个,如中所述。
3.2.4 存储器子系统
CEVA-BX2存储器子系统(MSS)是一个扩展系统,可以轻松适应全SoC集成。MSS由以下部件组成:
- 程序存储器子系统(PMSS):包含可选的一级程序存储器和四路或双向高速缓存
- 数据存储器子系统(DMSS):包含L1数据存储器和可选的双向高速缓存
- 通用单元:包括队列和缓冲区管理器、程序中断控制器和用作看门狗计时器、RTOS或通用计时器的计时器
核心在没有等待状态的情况下访问L1存储器和高速缓存;然而,访问外部存储器可能需要几个等待状态。
CEVA-BX2支持高达4 GB的内存空间,并具有多达八个单独的物理接口(最多七个用于数据存储器,一个用于程序存储器)。这使得内核能够与紧耦合扩展(TCE)并行地同时访问程序和数据存储器。MSS为内核提供对一个指令获取流和一个数据获取流的同时访问。PCU访问程序存储器,LSU访问数据存储器。
MSS包含用于将内核连接到外部设备和/或外围设备的标准接口。这些接口包括:
- 最多三个主端口用于数据,一个AXI主端口用于程序
- 外部主机最多四个AXI从机端口
- 一个APB3端口
所有端口都完全符合高级微控制器总线体系结构(AMBA)。
CEVA-BX2支持4 GB的数据存储空间和4 GB的程序存储空间。在每个周期中,最多可以向数据存储器发出两个32位数据地址,以及向程序存储器发出单个32位程序地址。
程序内存访问始终对齐为单个256位线(提取线)。仅当PCU需要时才提取提取线。由于PCU中的Dispatcher负责对齐它们,因此程序内存中的指令不会对齐。
CEVA-BX2 DMSS使用数据DMA(DDMA)在本地存储器和外部存储器之间传输数据,而不会干扰核心执行。此外,DMSS实现了一种特殊的DMA队列管理器(QMAN)机制,使用户能够激活DDMA,而无需核心干预,也无需使用实时软件。
CEVA-BX2体系结构支持复杂的电源管理。MSS包含一个功率缩放单元(PSU),该单元控制系统中的所有时钟信号。PSU功能使用户能够获得所需的应用马力,同时将功耗降至最低。
MSS还包括使用专用指令、专用空间配置和端口的I/O空间。该空间用于将外围设备连接到核心。
CEVA-BX2 MSS使用以下专用的外部和内部同步机制支持多核通信和共享内存一致性:
- 专用外部存储器访问同步,使用AXI接口
- 核心之间的多核消息传递接口,使用专用命令和消息传递接口
- 内部数据存储器(IDM)访问同步,使用侦听机制通知内核关于外部主设备访问的任何首选地址空间
3.2.5 CEVA-BX2硬件配置
CEVA-BX2支持多个硬件配置选项。这些配置使用户能够选择最适合其系统要求的硬件配置。介绍了CEVA-BX2中支持的配置。表2-1
表2-1.CEVA-BX2硬件配置选项
|
硬件配置名称 |
配置选项 |
备注 |
|
标量浮点 |
2/0 |
每个SPU一个浮点 |
|
附加SPU 32x32乘法器 |
是/否 |
支持SPU单元的额外32x32乘法器 |
|
双精度浮点 |
是/否 |
在单精度浮点上方选择 |
|
BTB大小 |
128/256个 |
BTB条目总数 |
|
BTB#方式 |
2/4 |
每个BTB表格行的条目数 |
|
循环缓冲区大小 |
无/5/10 |
可以迭代的数据包数 |
|
编程TCM大小 |
None/32/64/128/256KB |
|
|
程序高速缓存 |
无/32/64/128KB |
|
|
错误更正代码 |
启用/禁用 |
仅用于编程TCM和高速缓存 |
|
数据TCM大小 |
64/128/256/512 |
|
|
数据高速缓存 |
无/16/32/64KB |
|
|
AXI从端口 |
1/2/3/4号 |
|
|
AXI宽度 |
64/ 128 |
每个辅助端口的独立宽度配置可以是64位或128位。 EDAP是64位或128位。 要求AXIS0宽度≥AXIS1/AXIS2/AXIS3宽度。 |
|
AXI数据主端口 |
1/2/3/4号 |
|
|
AXIM宽度 |
64/ 128 |
要求AXI0宽度≥AXI1宽度。 |
|
队列管理器 |
0,1,2,3,4 |
|
|
中断控制器 |
无/32/64 |
ICU中断的可配置数量。无表示中断控制器是外部的。 |
|
计时器 |
0/4 |
|
|
实时跟踪(ETM) |
启用/禁用 |
|
|
SPU扩展 |
启用/禁用 |
包括/不包括SPU XTEND |
3.2.6 调试支持
3.2.6.1 调试单元
调试单元支持通过标准JTAG接口或与CoreSight兼容的APB从总线与主机调试器接口。它提供各种调试功能,例如:
- 内核暂停的调试模式,或调试异常
- 计数的程序地址断点
- 数据地址断点
- 数据值匹配断点、组合数据值断点和数据地址断点
- 单个步骤
3.2.6.2 仿形装置
分析单元有八个计数器,可以从80个事件中进行计数,例如,分析核心性能、缓存和内存系统性能、接口负载以及其他事件。
Profiler可以由核心软件(自配置文件)或SoC中的外部主控程序激活。它也可以动态激活和停用,以仅评测感兴趣的区域。
3.2.6.3 实时跟踪
CEVA-BX2支持可选的实时跟踪(RTT)功能。RTT硬件是可选的,可以在CEVA-BX2安装期间提取。
CEVA-BX2 RTT的目的是促进程序指令和数据跟踪,并将对核心性能的影响降至最低:
- 程序指令跟踪可以显示由CEVA-BX2执行的所有指令的列表,包括每个指令是否传递了其谓词代码。
- 指令预取跟踪可以在指令预取更新时显示它们的值,这使用户能够理解哪些预取指令会被执行。
- 数据跟踪可以显示内核执行的加载和存储访问。可以为地址、数据值或两者启用数据跟踪。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)