SHAP可解释学习,几行代码发一区!
Shapley值是一种分配给合作博弈中的每个参与者的贡献度的方法,SHAP在这个基础上应用于特征对模型输出的贡献度分析。SHAP的核心思想是将特征值的贡献分配到不同的特征中,计算每个特征的Shapley值,并将其与特征值相乘得到该特征对于预测结果的贡献。SHAP可以用于多种机器学习模型,包括分类和回归模型,可以生成图形化和定量的解释结果,帮助用户理解模型的决策过程。SHERPA结合了传统研究者驱动
2024深度学习发论文&模型涨点之——SHAP可解释学习
SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,它基于合作博弈理论中的Shapley值概念而建立的解释框架。Shapley值是一种分配给合作博弈中的每个参与者的贡献度的方法,SHAP在这个基础上应用于特征对模型输出的贡献度分析。
SHAP的核心思想是将特征值的贡献分配到不同的特征中,计算每个特征的Shapley值,并将其与特征值相乘得到该特征对于预测结果的贡献。SHAP可以用于多种机器学习模型,包括分类和回归模型,可以生成图形化和定量的解释结果,帮助用户理解模型的决策过程。
需要的同学关注公人人人号“AI创新工场”回复“SHAP可解释学习”即可全部领取
论文精选
论文1:
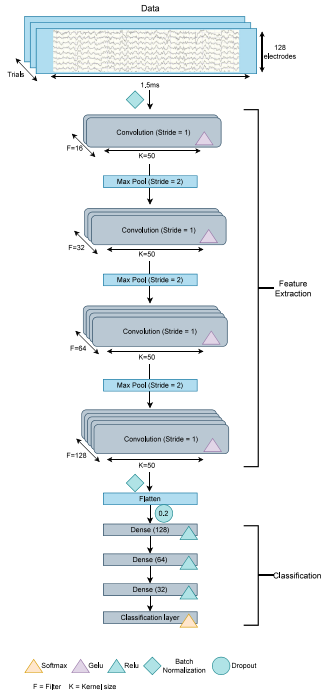
SHAP value-based ERP analysis (SHERPA): Increasing the sensitivity of EEG signals with explainable AI methods
基于SHAP值的ERP分析(SHERPA):用可解释的AI方法提高EEG信号的敏感性
方法
-
卷积神经网络(CNN):用于对实验条件进行分类。
-
SHapley Additive exPlanations(SHAP):作为事后解释器,识别重要的时间和空间特征。
-
特征重要性评分:通过计算“重要性评分”来量化ERP对心理机制的相关性。
-
数据驱动方法:通过数据驱动的方法来分析EEG信号,避免研究者偏见。
-
传统ERP分析:基于先前文献选择相关数据点和电极,构成事件相关电位(ERP)。
创新点
-
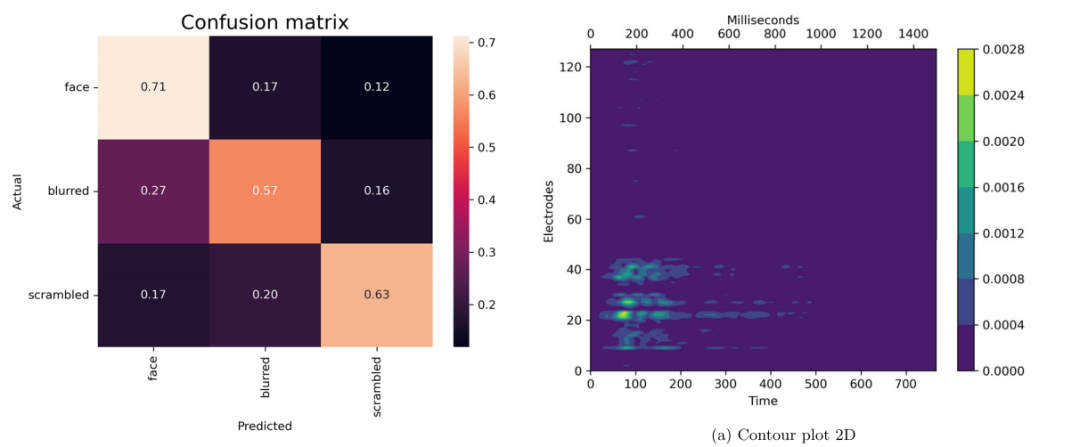
SHERPA方法:提出了一种新的基于可解释人工智能(XAI)的方法,用于客观地找到相关的潜伏期范围和电极。
-
重要性评分量化:首次允许通过计算ERP的“重要性评分”来量化ERP对心理机制的相关性。
-
负选择过程的识别:SHERPA表明在处理的早期和后期阶段存在负选择过程。
-
敏感性提升:新方法提供了适合于对效果先验知识有限的情况的分析方法,并且提高了能够高精度区分神经过程的敏感性。
-
结合传统与数据驱动方法:SHERPA结合了传统研究者驱动方法和数据驱动方法的优势,提供了一种新的分析EEG数据的方法。
论文2:
SHapley Additive exPlanations (SHAP) for Efficient Feature Selection in Rolling Bearing Fault Diagnosis
SHAP在滚动轴承故障诊断中的特征选择
方法
-
三阶段方法论:研究提出了一个三阶段的高效方法论,分别针对故障检测、分类和严重程度估计。
-
支持向量机(SVM):作为机器学习技术,用于上述三个任务。
-
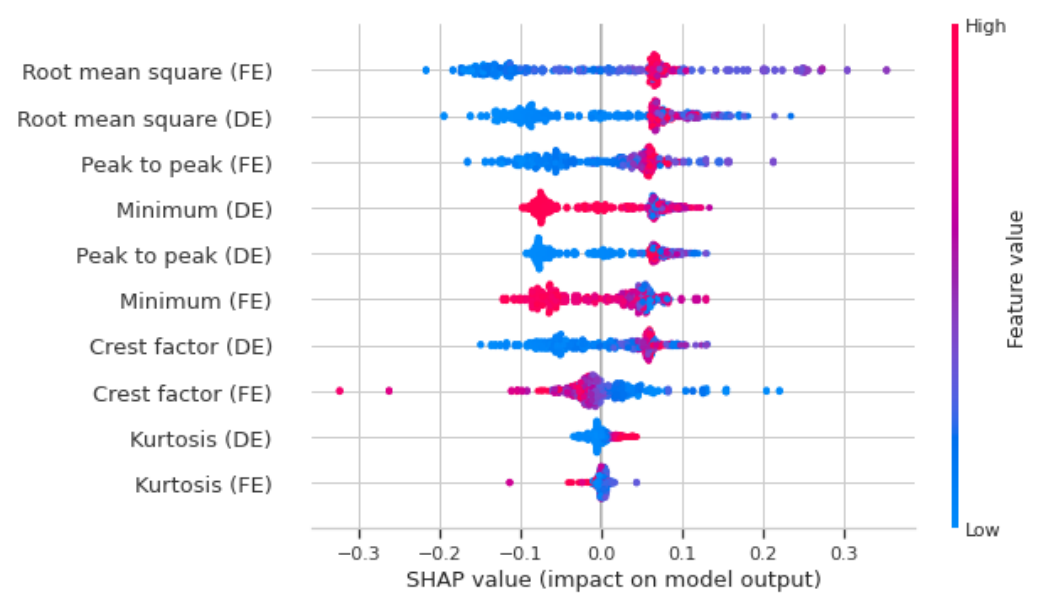
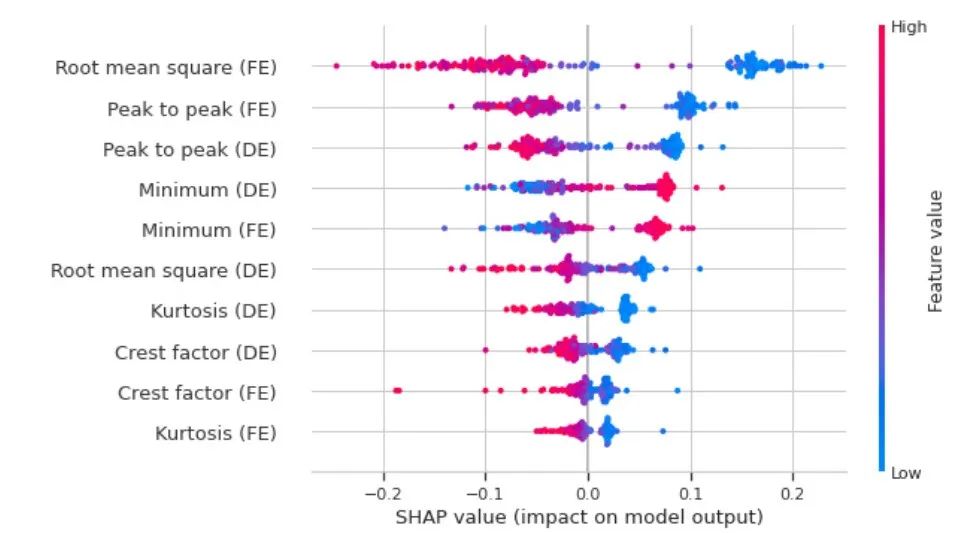
解释性人工智能(XAI)技术:整合了XAI技术,特别是SHAP,用于精心选择机器学习模型的最优特征。
-
特征选择:通过SHAP值来量化特征对模型预测的个体重要性。
-
特征重要性评估:使用SHAP值来评估每个特征对模型性能的贡献,并据此构建简化模型。
创新点
-
顺序三阶段方法:创新性地提出了一个顺序三阶段方法,每个阶段的信息用于优化后续阶段,提高了故障诊断的有效性。
-
SHAP值的应用:在滚动轴承故障诊断中,使用SHAP值进行特征选择,提高了模型的准确性和效率。
-
特征选择的优化:即使在特征数量非常有限的情况下,也能通过SHAP值选择最重要的特征,保持高准确率。
-
解释性与效率的结合:不仅提高了模型的预测性能,还通过XAI技术增强了模型的可解释性。
-
灵活性和普适性:提出的方法不仅适用于特定的数据集,还能够适应不同的特征集和多样的机器学习技术。
论文3:
The importance of interpreting machine learning models for blood glucose prediction in diabetes: an analysis using SHAP
糖尿病血糖预测中解释机器学习模型的重要性:使用SHAP的分析
方法
-
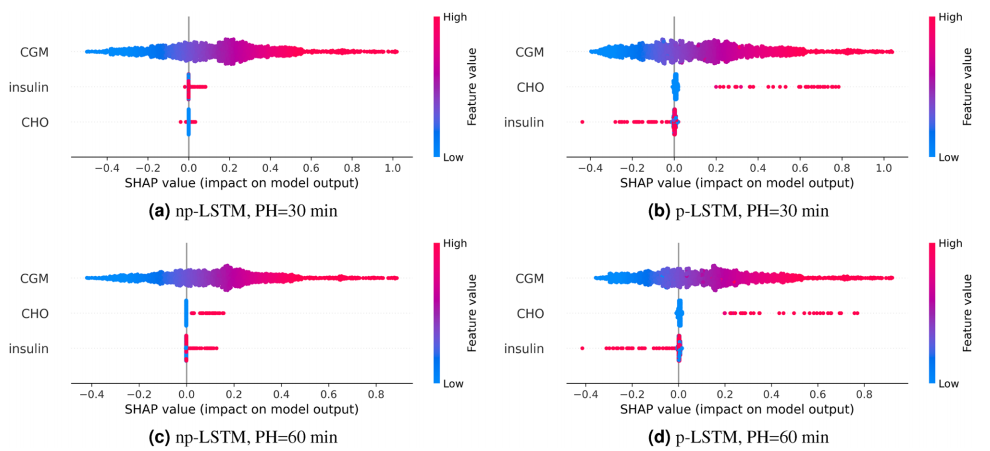
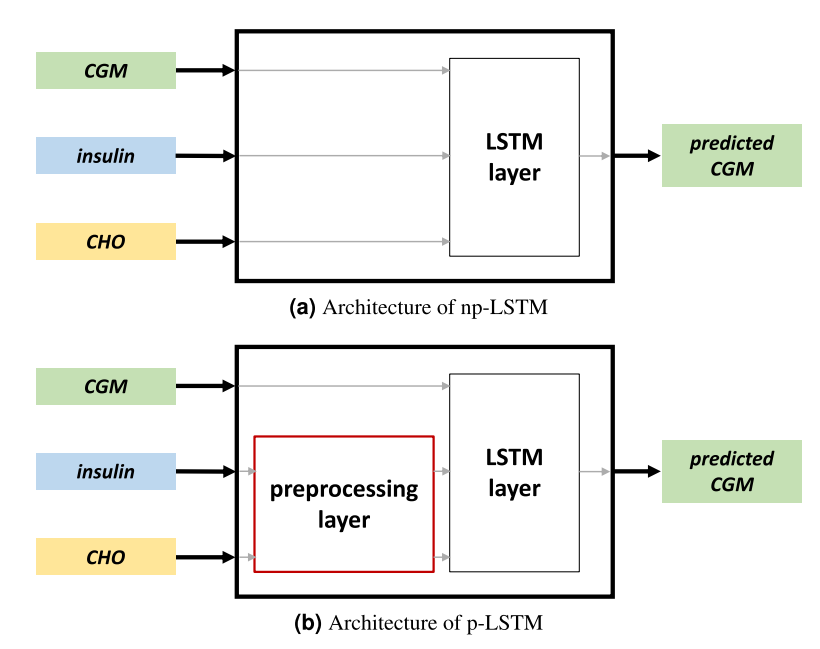
长短期记忆神经网络(LSTM):选择了LSTM作为案例研究的模型架构,特别适合于时间序列预测问题。
-
SHAP(SHapley Additive exPlanation):采用SHAP工具解释黑盒模型的输出,提供了每个输入对模型输出的贡献度量。
-
数据集和预处理:使用OhioT1DM数据集,对数据进行同步、插值和预处理,以适应模型训练和测试。
-
模型训练和评估:训练两个LSTM模型(p-LSTM和np-LSTM),并使用MAE、RMSE和TG等标准指标评估预测准确性。
创新点
-
生理学解释的重要性:强调了在T1D管理中选择预测算法时,除了预测准确性外,模型的生理学解释能力同样重要。
-
SHAP在血糖预测模型中的应用:首次将SHAP应用于血糖预测模型,揭示了模型是否学习到了输入与血糖预测之间的生理关系。
-
p-LSTM与np-LSTM的比较:通过比较两种LSTM模型,展示了预处理层在帮助模型理解胰岛素和碳水化合物对血糖水平变化的正确影响方面的作用。
-
决策支持系统(DSS)的集成:将解释性工具SHAP与DSS集成,用于评估模型在实际临床决策中的表现,特别是在建议校正性胰岛素剂量方面。
论文4:
Predicting graft and patient outcomes following kidney transplantation using interpretable machine learning models
使用可解释机器学习模型预测肾脏移植后的移植物和患者结果
方法
-
生存分析模型:比较了多种生存分析模型,包括Cox比例风险模型、神经网络和随机生存森林。
-
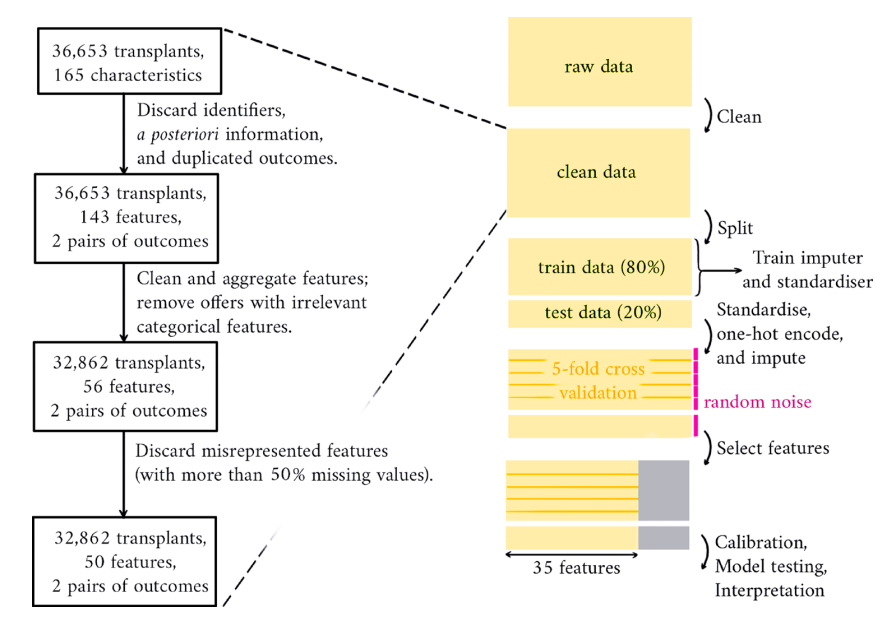
数据预处理:对来自英国移植注册处的数据集进行清洗、标准化和编码,以及缺失值的插补。
-
模型训练和验证:使用80%的数据进行模型训练,剩余20%用于测试,通过5折交叉验证进行特征选择和模型训练。
-
模型校准:通过训练逻辑回归模型调整预测,以匹配观察到的结果比例。
创新点
-
神经网络在生存分析中的应用:展示了神经网络在预测肾脏移植结果方面与传统的Cox比例风险模型具有可比的性能。
-
模型的临床验证:使用SHAP值对模型进行事后解释,提供了比Cox模型更丰富的临床描述,增强了模型的可解释性。
-
模型性能的比较:通过比较不同模型的性能,提供了对各种模型在预测移植结果方面的深入理解。
-
模型的可解释性和可用性:强调了在构建临床决策支持系统时,模型的可解释性和可用性的重要性,并展示了如何通过SHAP实现这一点。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)