24/10/7 YOLOv8实验日记
这里先描述一下任务,这里是昨天晚上跑了一个200 epochs的训练,这里是没有添加任何模块实验结果:这里是训练了167轮之后没有什么提升就给停止了,这里说最好的模型是第67轮的模型,这里去看下,我们每次跑实验都要记录一下哪些参数,应该有哪些参数的设置,然后就是加模块跑下实验,看最后的评价标是否有提升。
这里先描述一下任务,这里是昨天晚上跑了一个200 epochs的训练,这里是没有添加任何模块
训练指令:
yolo detect train data=D:\YOLOv8Detection\ultralytics-main\datasets\strawberries\data.yaml model=D:\YOLOv8Detection\ultralytics-main\ultralytics\cfg\models\v8\yolov8.yaml pretrained=yolov8n.pt epochs=200 batch=2 lr0=0.01 resume=True workers=1打印参数:
engine\trainer: task=detect, mode=train, model=D:\YOLOv8Detection\ultralytics-main\ultralytics\cfg\models\v8\yolov8.yaml, data=D:\YOLOv8Detection\ultralytics-main\datasets\strawberri
es\data.yaml, epochs=200, time=None, patience=100, batch=2, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=1, project=None, name=train12, exist_ok=False, pre
trained=yolov8n.pt, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=None, amp=True, fraction=1.0, profil
e=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=
False, dnn=False, plots=True, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=F
alse, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimi
ze=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0
.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0
.0, perspective=0.0, flipud=0.0, fliplr=0.5, bgr=0.0, mosaic=1.0, mixup=0.0, copy_paste=0.0, auto_augment=randaugment, erasing=0.4, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, save_dir=runs\detect\train12
Overriding model.yaml nc=80 with nc=3模型的信息:
from n params module arguments
0 -1 1 464 ultralytics.nn.modules.conv.Conv [3, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 7360 ultralytics.nn.modules.block.C2f [32, 32, 1, True]
3 -1 1 18560 ultralytics.nn.modules.conv.Conv [32, 64, 3, 2]
4 -1 2 49664 ultralytics.nn.modules.block.C2f [64, 64, 2, True]
5 -1 1 73984 ultralytics.nn.modules.conv.Conv [64, 128, 3, 2]
6 -1 2 197632 ultralytics.nn.modules.block.C2f [128, 128, 2, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 460288 ultralytics.nn.modules.block.C2f [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 1 148224 ultralytics.nn.modules.block.C2f [384, 128, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 1 37248 ultralytics.nn.modules.block.C2f [192, 64, 1]
16 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 1 123648 ultralytics.nn.modules.block.C2f [192, 128, 1]
19 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 1 493056 ultralytics.nn.modules.block.C2f [384, 256, 1]
22 [15, 18, 21] 1 751897 ultralytics.nn.modules.head.Detect [3, [64, 128, 256]]
YOLOv8 summary: 225 layers, 3011433 parameters, 3011417 gradients, 8.2 GFLOPs实验结果:
这里是训练了167轮之后没有什么提升就给停止了,
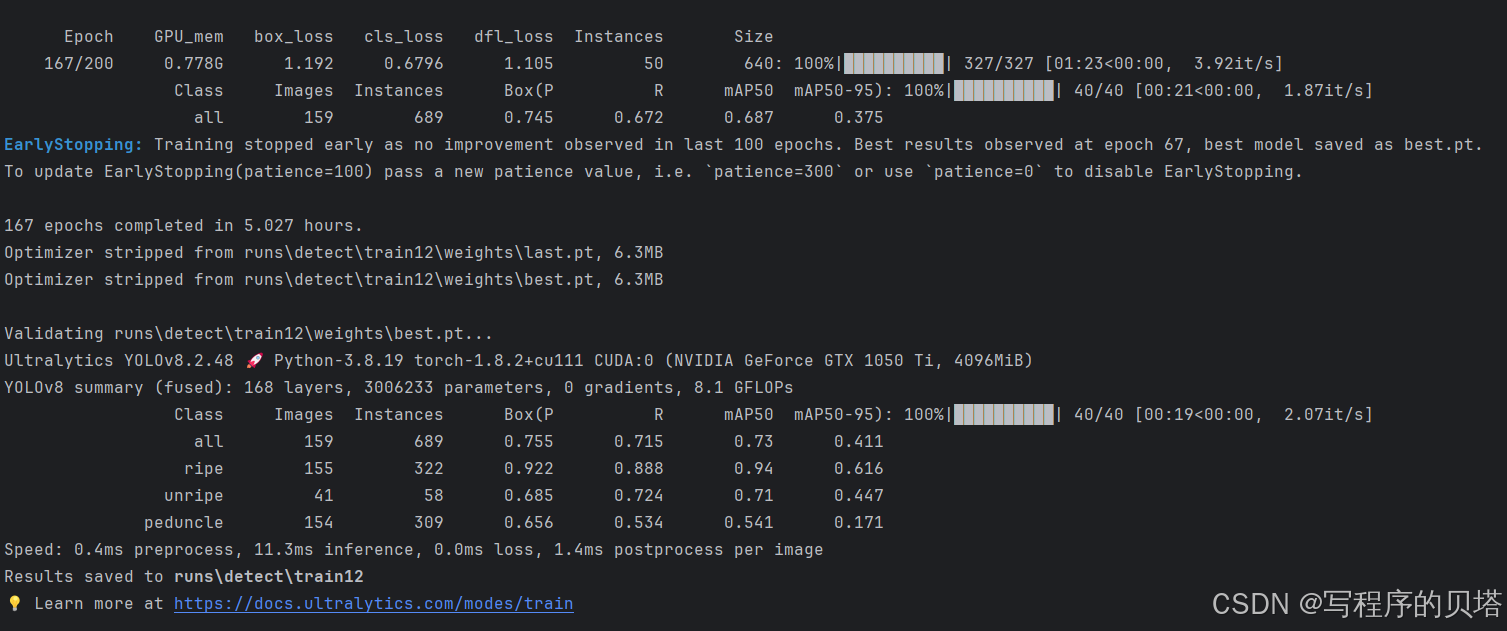
实验结果文字:
EarlyStopping: Training stopped early as no improvement observed in last 100 epochs. Best results observed at epoch 67, best model saved as best.pt.
To update EarlyStopping(patience=100) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping.
167 epochs completed in 5.027 hours.
Optimizer stripped from runs\detect\train12\weights\last.pt, 6.3MB
Optimizer stripped from runs\detect\train12\weights\best.pt, 6.3MB
Validating runs\detect\train12\weights\best.pt...
Ultralytics YOLOv8.2.48 🚀 Python-3.8.19 torch-1.8.2+cu111 CUDA:0 (NVIDIA GeForce GTX 1050 Ti, 4096MiB)
YOLOv8 summary (fused): 168 layers, 3006233 parameters, 0 gradients, 8.1 GFLOPs
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 40/40 [00:19<00:00, 2.07it/s]
all 159 689 0.755 0.715 0.73 0.411
ripe 155 322 0.922 0.888 0.94 0.616
unripe 41 58 0.685 0.724 0.71 0.447
peduncle 154 309 0.656 0.534 0.541 0.171
Speed: 0.4ms preprocess, 11.3ms inference, 0.0ms loss, 1.4ms postprocess per image
Results saved to runs\detect\train12
💡 Learn more at https://docs.ultralytics.com/modes/train这里说最好的模型是第67轮的模型,
这里去看下,我们每次跑实验都要记录一下哪些参数,应该有哪些参数的设置,然后就是加模块跑下实验,看最后的评价标是否有提升
这里记录下报的警告
报了3个WARING:
第1个是WARNING ⚠️ no model scale passed. Assuming scale='n'

这里我一会放解决方案
补充一下解决方案,这里的问题是,cfg文件夹下v8的yaml文件中,没有叫yolov8n.yaml的文件,所以我们只需要复制一份yolov8.yaml 文件,给它重命名为yolov8n.yaml就不会报这个WARNING
yolo detect train data=D:\YOLOv8Detection\ultralytics-main\datasets\strawberries\data.yaml model=D:\YOLOv8Detection\ultralytics-main\ultralytics\cfg\models\v8\yolov8n.yaml pretrained=yolov8n.pt epochs=200 batch=2 lr0=0.01 resume=True workers=1这里的运行代码和之前一样,就是在model的哪里最后加个n就可以
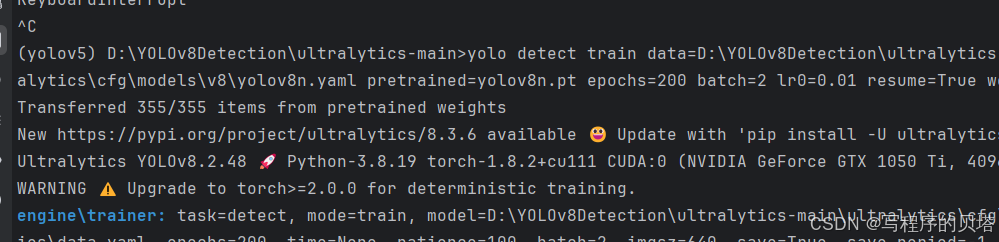
这里就不会报警告了
第2个WARNING是WARNING ⚠️ Upgrade to torch>=2.0.0 for deterministic training.
是说pytorch的版本太低了,他现在也不影响我们玩模型这个就先不管

第3个WARNING是train: WARNING ⚠️ D:\YOLOv8Detection\ultralytics-main\datasets\strawberries\train\images\100.jpg: corrupt JPEG restored and saved
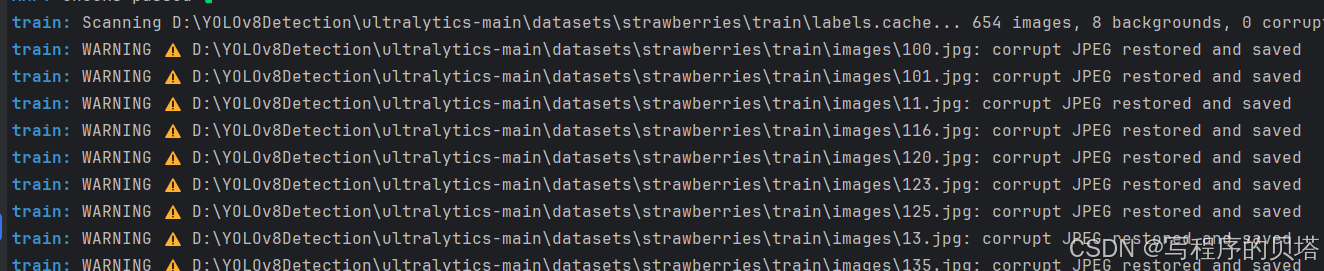
这里是图片转换的问题,下面是解决办法的链接

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)