Transformer代码解读【纯分享】
写在前面:前面分享了Transformer论文笔记,干脆把代码一起分享了,和论文一样,文章中有不尽详实或有错误的地方,欢迎批评指正
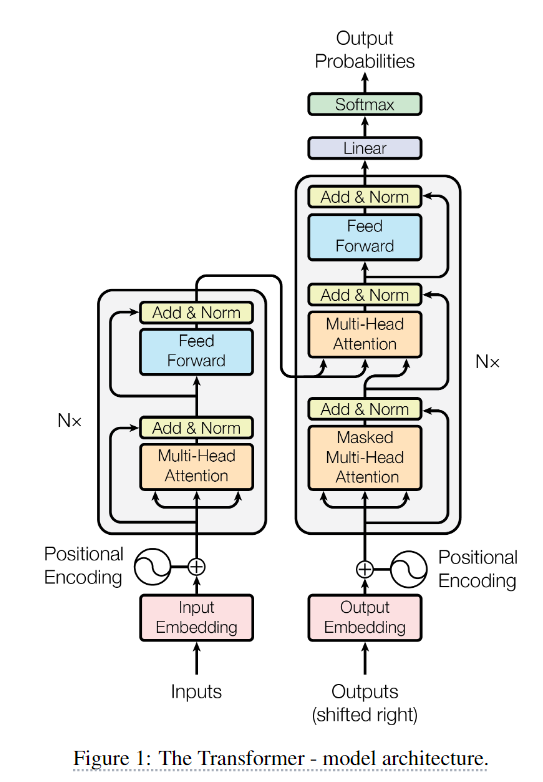
transformer架构
代码
多头注意力
class MultiHeadAttention(nn.Module):
"""多头注意力机制"""
def __init__(self, d_model=512, n_heads=8, dropout=0.1):
super().__init__()
assert d_model % n_heads == 0, "d_model必须能被n_heads整除"
self.d_k = d_model // n_heads # 每个头的输出维度
self.n_heads = n_heads # 头的数量
# 线性变换层(将输入映射到Q/K/V)
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
self.W_O = nn.Linear(d_model, d_model)
self.attention = ScaledDotProductAttention(dropout) # 缩放点积注意力机制
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x, enc_output=None, mask=None):
"""
Args:
x: 输入序列 [batch_size, seq_len, d_model]
enc_output: 编码器输出(解码器交叉注意力时使用)
mask: 掩码(解码器自注意力用)
"""
residual = x # 残差连接
batch_size, seq_len, _ = x.size()
# 生成Q/K/V(区分自注意力和交叉注意力)
if enc_output is None: # 自注意力
Q = self.W_Q(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # [batch, h, seq_len, d_k]
K = self.W_K(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_V(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
else: # 交叉注意力(解码器使用编码器输出)
Q = self.W_Q(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = self.W_K(enc_output).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_V(enc_output).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# 计算注意力
attn_output, attn_weights = self.attention(Q, K, V, mask) # [batch, h, seq_len, d_k]
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1) # 合并多头
output = self.W_O(attn_output)
# dropout + 残差连接 + LayerNorm
output = self.layer_norm(residual + self.dropout(output))
return output, attn_weights
网络输入:
- 交叉注意力:K V: 编码器的输出
enc_output,Q:前一层解码器的输出 - 自注意力:外部输入
x
初始化:
-
self.d_k: 每个头的输出维度 -
self.n_heads: 头的数量 -
self.W_Qself.W_Kself.W_V: 线性变换层,对输入的x做线性变换
为什么是从d_model 到 d_model的映射,而不是从d_model到d_k的映射?-
数学计算上二者是等价的:
- 对于每个头的查询: Q i = X ∗ W q i (其中 W q i ∈ R d m o d e l × d k ) Q_i = X * W_q^i (其中 W_q^i ∈ R^{d_{model}×d_k}) Qi=X∗Wqi(其中Wqi∈Rdmodel×dk)
- 所有头的输出拼接: Q = [ Q 1 , Q 2 , . . . , Q h ] ∗ W o ( h 个头, W o ∈ R h ∗ d k × d m o d e l ) Q = [Q_1, Q_2, ..., Q_h] * W_o (h个头,W_o ∈ R^{h*d_k×d_{model}}) Q=[Q1,Q2,...,Qh]∗Wo(h个头,Wo∈Rh∗dk×dmodel)
- 合并参数矩阵: 将 h 个 $W_q^i $拼接成一个大矩阵:
- W Q = [ W q 1 ∣ W q 2 ∣ . . . ∣ W q h ] (形状 d m o d e l × d m o d e l ) W_Q = [W_q^1 | W_q^2 | ... | W_q^h] (形状 d_{model}×d_{model}) WQ=[Wq1∣Wq2∣...∣Wqh](形状dmodel×dmodel)
- 矩阵运算等效性: X ∗ W Q = X ∗ [ W q 1 ∣ W q 2 ∣ . . . ∣ W q h ] = [ X ∗ W q 1 ∣ X ∗ W q 2 ∣ . . . ∣ X ∗ W q h ] X * W_Q = X * [W_q^1 | W_q^2 | ... | W_q^h] = [X*W_q^1 | X*W_q^2 | ... | X*W_q^h] X∗WQ=X∗[Wq1∣Wq2∣...∣Wqh]=[X∗Wq1∣X∗Wq2∣...∣X∗Wqh]
-
并行更高效
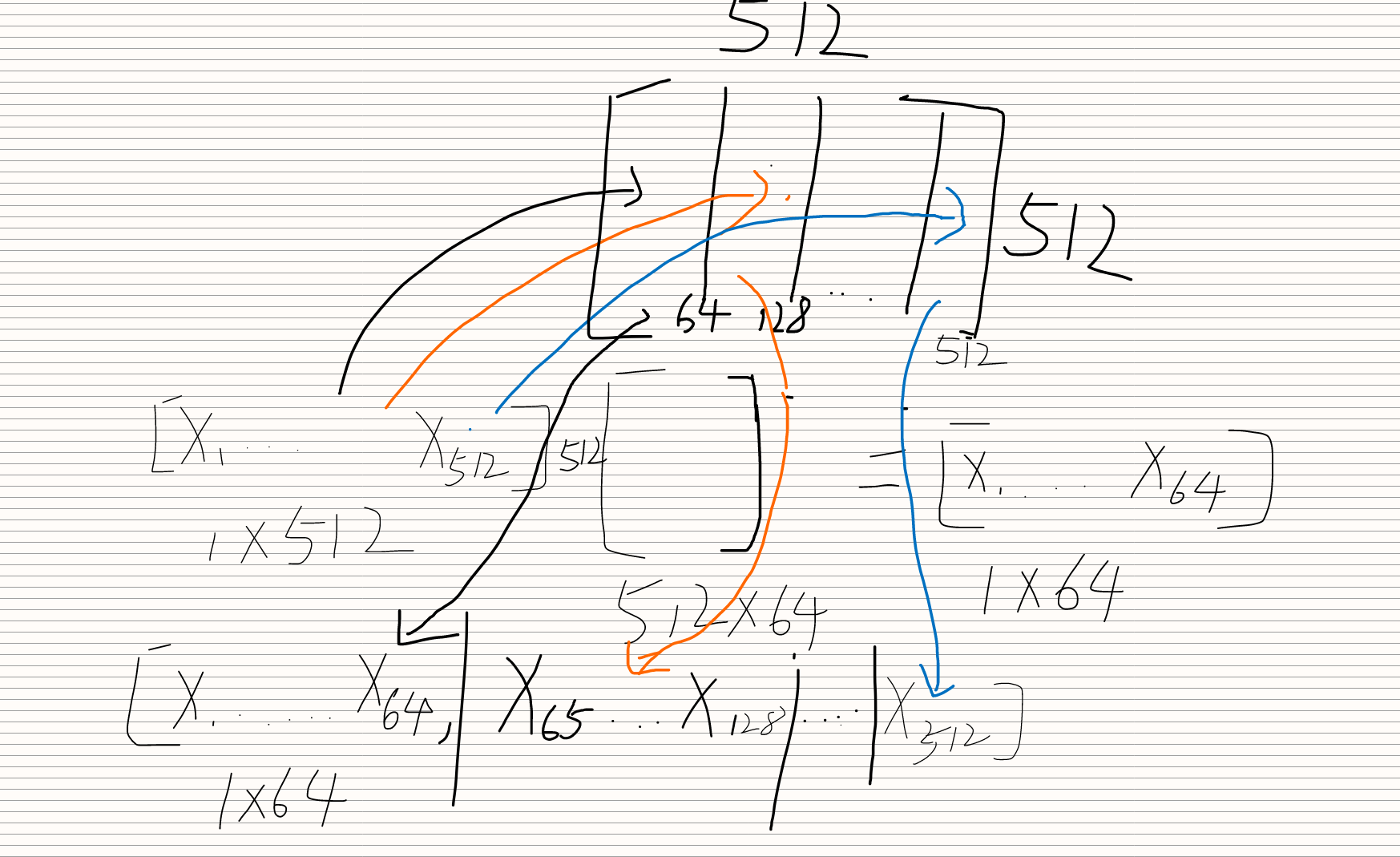
咳咳,草图画的有些许粗糙,大概就是怎么个意思:原本应该从512维映射到64维,但在实现中发现从512维映射到512维也可以,因为输入的512维向量和512x512的变换矩阵的第i个512x64的矩阵做乘法就会得到第i个1x64的向量,这个512x64的矩阵和直接往64维映射的矩阵是一样的,结果也一样,所以直接合在一起计算一次,后面再分割成几个头就行了
-
-
self.W_O: 线性变换层,对多头合并后的输出做线性变换
流程:
- 根据是自注意力还是交叉注意力 将输入进行线性映射,再将结果拆成(view)n_heads头,每个头d_k 维,再交换1 2维
# 生成Q/K/V(区分自注意力和交叉注意力)
if enc_output is None: # 自注意力
Q = self.W_Q(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2) # [batch, h, seq_len, d_k]
K = self.W_K(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_V(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
else: # 交叉注意力(解码器使用编码器输出)
Q = self.W_Q(x).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
K = self.W_K(enc_output).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
V = self.W_V(enc_output).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
- 通过缩放点积注意力获得输出
attn_output, attn_weights = self.attention(Q, K, V, mask) # [batch, h, seq_len, d_k]
- 合并多个头的输出
attn_output = attn_output.transpose(1, 2).contiguous().view(batch_size, seq_len, -1) # 合并多头
- 输出做映射
output = self.W_O(attn_output)
- dropout + 残差连接 + LayerNorm
output = self.layer_norm(residual + self.dropout(output))
缩放点积注意力
class ScaledDotProductAttention(nn.Module):
"""缩放点积注意力机制"""
def __init__(self, dropout=0.1):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, Q, K, V, mask=None):
"""
Args:
Q: [batch_size, n_heads, seq_len, d_k]
K, V: [batch_size, n_heads, seq_len, d_k]
mask: 掩码(解码器自注意力用)
"""
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(Q.size(-1)) # [batch, h, seq_len, seq_len]
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9) # 将掩码位置设为极大负数
attn_weights = F.softmax(attn_scores, dim=-1)
attn_weights = self.dropout(attn_weights)
output = torch.matmul(attn_weights, V) # [batch, h, seq_len, d_k]
return output, attn_weights
公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt d_k})V Attention(Q,K,V)=softmax(dkQKT)V
- Q 和 K T K^T KT做矩阵乘法再除 d k \sqrt d_k dk
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(Q.size(-1)) # [batch, h, seq_len, seq_len]
- 判断使用掩码
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9) # 将掩码位置设为极大负数
-
掩码匹配:将
mask中值为0的位置(需屏蔽的位置)对应到注意力分数矩阵attn_scores -
数值替换:将对应位置的分数替换为极小的负数(-1e9 ≈ -1000000000)
- 对最后一维
seq_len做softmax
attn_weights = F.softmax(attn_scores, dim=-1)
- 正则化
attn_weights = self.dropout(attn_weights)
- 和V矩阵做乘法,返回输出和权重(Q K相似性)
output = torch.matmul(attn_weights, V) # [batch, h, seq_len, d_k]
return output, attn_weights
位置前馈网FFN
class PositionWiseFFN(nn.Module):
"""位置前馈网络"""
def __init__(self, d_model=512, d_ff=2048, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x):
residual = x
x = self.linear1(x)
x = F.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return self.layer_norm(residual + self.dropout(x))
可看成单隐藏层的MLP,对输入做两次映射
网络输入:前一层注意力的输出
流程:
-
将输入从 d m o d e l d_{model} dmodel维映射到 d f f d_{ff} dff维(512->2048),扩大四倍
x = self.linear1(x)self.linear1 = nn.Linear(d_model, d_ff) -
做relu激活和正则化
x = F.relu(x) x = self.dropout(x) -
映射回 d m o d e l d_{model} dmodel维
x = self.linear2(x)self.linear2 = nn.Linear(d_ff, d_model) -
正则化+残差连接+LN 返回
return self.layer_norm(residual + self.dropout(x))
位置编码
class PositionalEncoding(nn.Module):
"""正弦位置编码(固定参数)"""
def __init__(self, d_model=512, max_len=5000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置
pe = pe.unsqueeze(0) # [1, max_len, d_model]
self.register_buffer('pe', pe)
def forward(self, x):
"""
Args:
x: [batch_size, seq_len, d_model]
"""
return x + self.pe[:, :x.size(1)] # 自动广播到batch维度
编码公式:
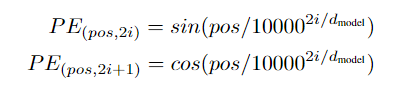
将位置编码嵌入到输入x中,返回
return x + self.pe[:, :x.size(1)] # 自动广播到batch维度
整体实现
编码器层
class EncoderLayer(nn.Module):
"""编码器层(包含多头自注意力和前馈网络)"""
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = PositionWiseFFN(d_model, d_ff, dropout)
def forward(self, x, mask=None):
# 自注意力
x, _ = self.self_attn(x, mask=mask)
# 前馈网络
x = self.ffn(x)
return x
编码过程:
- 先将输入通过多头注意力MultiHeadAttention
- 再将注意力层的输出通过前馈网FFN
每一层返回的输出已经加入了正则化、残差和LN
编码器中使用src_mask掩码的原因:
- 屏蔽填充位置:
- 当输入序列长度不足时,会用padding(如0)填充
- 需要防止注意力机制处理这些无效位置
关于序列为什么会被填充:
输入的句子中各个单词的长度不一致,但深度学习框架要求输入张量的维度是一致的
解码器层
class DecoderLayer(nn.Module):
"""解码器层(包含自注意力、交叉注意力和前馈网络)"""
def __init__(self, d_model=512, n_heads=8, d_ff=2048, dropout=0.1):
super().__init__()
self.self_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, n_heads, dropout)
self.ffn = PositionWiseFFN(d_model, d_ff, dropout)
def forward(self, x, enc_output, src_mask=None, tgt_mask=None):
# 自注意力(使用目标序列掩码)
x, _ = self.self_attn(x, mask=tgt_mask)
# 交叉注意力(使用编码器输出)
x, _ = self.cross_attn(x, enc_output, mask=src_mask)
# 前馈网络
x = self.ffn(x)
return x
解码过程:
- 先将原始
x输入通过自注意力 - 再将编码器的输入
enc_output和x一起通过交叉注意力(带掩码的) - 最后将注意力机制的输出送入前馈网FFN计算,得到解码输出
完整Transformer架构
class Transformer(nn.Module):
"""完整的Transformer模型(编码器-解码器架构)"""
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, n_heads=8,
num_layers=6, d_ff=2048, dropout=0.1, max_len=5000):
super().__init__()
# 嵌入层
self.src_embed = nn.Embedding(src_vocab_size, d_model)
self.tgt_embed = nn.Embedding(tgt_vocab_size, d_model)
self.pos_encoder = PositionalEncoding(d_model, max_len)
# 编码器栈
self.encoder = nn.ModuleList([
EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers)
])
# 解码器栈
self.decoder = nn.ModuleList([
DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers)
])
# 输出层
self.linear = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
# 参数初始化
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def encode(self, src, src_mask=None):
# 输入嵌入 + 位置编码
src = self.dropout(self.pos_encoder(self.src_embed(src)))
# 逐层编码
for layer in self.encoder:
src = layer(src, src_mask)
return src
def decode(self, tgt, enc_output, src_mask=None, tgt_mask=None):
# 目标嵌入 + 位置编码
tgt = self.dropout(self.pos_encoder(self.tgt_embed(tgt)))
# 逐层解码
for layer in self.decoder:
tgt = layer(tgt, enc_output, src_mask, tgt_mask)
return tgt
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
enc_output = self.encode(src, src_mask)
dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask)
return self.linear(dec_output)
def generate_mask(self, src, tgt, pad_idx=0):
"""生成序列掩码(处理填充和未来信息)"""
# 源序列填充掩码 [batch, 1, 1, src_len]
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)
# 目标序列填充掩码 + 未来掩码
tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(3) # [batch, 1, tgt_len, 1]
tgt_len = tgt.size(1)
tgt_sub_mask = torch.tril(torch.ones(tgt_len, tgt_len)).bool().to(tgt.device) # 下三角矩阵
tgt_mask = tgt_pad_mask & tgt_sub_mask # 合并两种掩码
return src_mask, tgt_mask
初始化变量:
-
self.src_embedself.tgt_embed:将离散的单词索引转换为连续的d_model维向量self.src_embed = nn.Embedding(src_vocab_size, d_model) self.tgt_embed = nn.Embedding(tgt_vocab_size, d_model) -
self.pos_encoder: 获得位置编码self.pos_encoder = PositionalEncoding(d_model, max_len) -
编码器栈:
self.encoder: 堆叠num_layers个编码器层# 编码器栈 self.encoder = nn.ModuleList([ EncoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers) ]) -
解码器栈:
self.decoder: 堆叠num_layers个解码器层# 解码器栈 self.decoder = nn.ModuleList([ DecoderLayer(d_model, n_heads, d_ff, dropout) for _ in range(num_layers) ]) -
输出层线性变换:Transformer的最终输出需要做Linear
# 输出层 self.linear = nn.Linear(d_model, tgt_vocab_size) -
参数初始化
# 参数初始化 for p in self.parameters(): if p.dim() > 1: nn.init.xavier_uniform_(p)
方法实现:
-
编码encode:
def encode(self, src, src_mask=None): # 输入嵌入 + 位置编码 src = self.dropout(self.pos_encoder(self.src_embed(src))) # 逐层编码 for layer in self.encoder: src = layer(src, src_mask) return src- 将
src通过self.src_embed,经过embedding转换成d_model维的连续向量 - 对每一层编码器(共num_layers层)进行前向传播,获得输出src
- 将输出返回,作为后面解码器的交叉注意力的输入
- 将
-
解码decode:
def decode(self, tgt, enc_output, src_mask=None, tgt_mask=None): # 目标嵌入 + 位置编码 tgt = self.dropout(self.pos_encoder(self.tgt_embed(tgt))) # 逐层解码 for layer in self.decoder: tgt = layer(tgt, enc_output, src_mask, tgt_mask) return tgt-
先将解码器的原始输入tgt经过embedding转换成向量
self.tgt_embed(tgt) -
再将这个向量送入计算位置编码
self.pos_encoder(self.tgt_embed(tgt)) -
再做正则化,得到可以送入解码器的输入(简单说就是先将原始输入embedding后加入位置编码,正则化后送入解码器)
-
逐层将输入送入解码器,进行解码
for layer in self.decoder: tgt = layer(tgt, enc_output, src_mask, tgt_mask) return tgt -
返回解码结果,最后将该结果经过线性变换linear后得到模型最终的输出
-
-
前向传播 forward:
def forward(self, src, tgt, src_mask=None, tgt_mask=None): enc_output = self.encode(src, src_mask) dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask) return self.linear(dec_output)-
先通过编码器,拿到编码器的输出enc_output
enc_output = self.encode(src, src_mask) -
再将编码器的输出和解码器的原始输入tgt一起送入解码器
dec_output = self.decode(tgt, enc_output, src_mask, tgt_mask) -
最后将解码器的输出做线性变换,返回
return self.linear(dec_output)
-
-
掩码生成函数 generate_mask:
def generate_mask(self, src, tgt, pad_idx=0): """生成序列掩码(处理填充和未来信息)""" # 源序列填充掩码 [batch, 1, 1, src_len] src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2) # 目标序列填充掩码 + 未来掩码 tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(3) # [batch, 1, tgt_len, 1] tgt_len = tgt.size(1) tgt_sub_mask = torch.tril(torch.ones(tgt_len, tgt_len)).bool().to(tgt.device) # 下三角矩阵 tgt_mask = tgt_pad_mask & tgt_sub_mask # 合并两种掩码 return src_mask, tgt_mask-
生成源序列掩码
src_mask = (src != pad_idx).unsqueeze(1).unsqueeze(2)- 目的:屏蔽源序列中的填充符号(如
<pad>)。 - 操作:
- 布尔掩码:
src != pad_idx生成布尔张量,形状[batch_size, src_len],其中非填充位置为True,填充位置为False。 - 维度扩展:通过
unsqueeze(1).unsqueeze(2),将形状变为[batch_size, 1, 1, src_len],以适配多头注意力机制。
- 布尔掩码:
- 目的:屏蔽源序列中的填充符号(如
-
生成目标序列掩码
# 目标序列填充掩码 + 未来掩码 tgt_pad_mask = (tgt != pad_idx).unsqueeze(1).unsqueeze(3) # [batch, 1, tgt_len, 1] tgt_len = tgt.size(1) tgt_sub_mask = torch.tril(torch.ones(tgt_len, tgt_len)).bool().to(tgt.device) # 下三角矩阵 tgt_mask = tgt_pad_mask & tgt_sub_mask # 合并两种掩码- 目的:屏蔽目标序列的填充符号和未来信息(防止解码器在训练时“偷看”后续位置)。
- 操作:
- 目标填充掩码:
tgt_pad_mask生成布尔张量,形状[batch_size, 1, tgt_len, 1],标识非填充位置。 - 未来信息掩码:
生成下三角矩阵tgt_sub_mask(形状[tgt_len, tgt_len]),其中主对角线及以下为True,其余为False,确保当前位置只能关注之前的位置。 - 合并掩码:
将tgt_pad_mask和tgt_sub_mask进行逻辑与操作,得到最终掩码tgt_mask,形状[batch_size, 1, tgt_len, tgt_len]。
- 目标填充掩码:
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 46
46 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)