TimeBridge——长、短期时间序列预测中的非平稳性问题
原文地址:TimeBridge: Non-Stationarity Matters for Long-term Time Series Forecasting | OpenReview
发表会议:ICLR 2025
代码地址:https://github.com/Hank0626/TimeBridge
作者:刘培源、吴贝良、胡一凡、李乃启、戴涛、鲍继刚、夏树涛
团队:清华大学、深圳大学
贡献:
这篇论文提出了一种名为 TimeBridge 的新框架,旨在解决多变量时间序列预测中非平稳性带来的挑战。非平稳性(如短期波动和长期趋势)可能导致虚假回归或掩盖重要的长期关系。现有方法通常要么完全消除非平稳性,要么完全保留,未能有效区分其对短期和长期建模的不同影响。
TimeBridge 的核心思想是通过将输入序列分割为小块(patches),分别处理短期和长期依赖关系:
1、Integrated Attention:用于缓解短期非平稳性,捕捉每个变量内部的稳定依赖关系。
2、Cointegrated Attention:保留非平稳性,建模变量之间的长期协整关系。
实验结果表明,TimeBridge 在短期和长期预测中均取得了最先进的性能,尤其是在金融预测(如 CSI 500 和 S&P 500 指数)中表现出色,验证了其鲁棒性和有效性
科普:
虚假回归(Spurious Regression)是指在统计分析中,两个或多个非平稳时间序列之间看似存在显著的统计关系,但实际上这种关系是虚假的,仅仅是因为这些序列具有共同的趋势或随机性,而非真正的因果关系。这种现象会导致错误的结论,例如误认为两个无关的变量之间存在相关性。
时间序列预测方法分为Normalization和Dependency Modeling
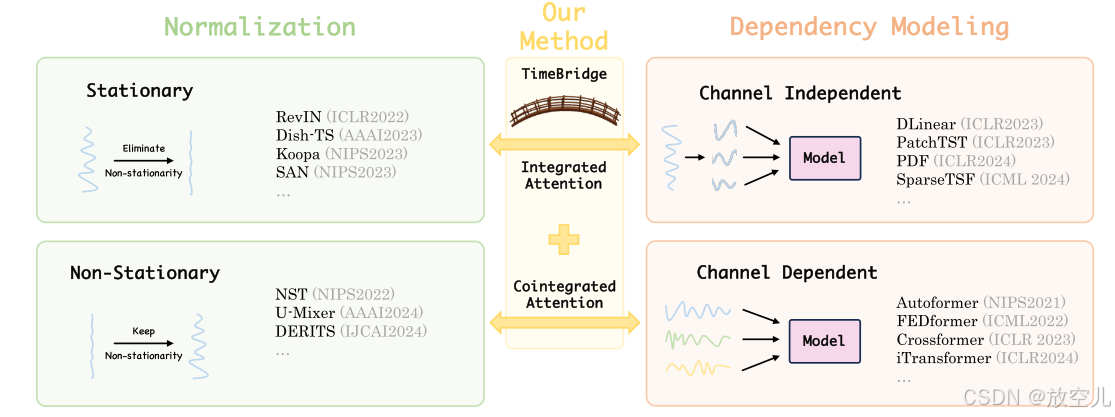
CI 方法:适合捕捉单个变量的快速变化,训练稳定,但忽略了变量之间的关系。
CD 方法:适合捕捉变量之间的复杂关系,但可能受到虚假回归的影响,且在短期建模上表现较差。
模型框架
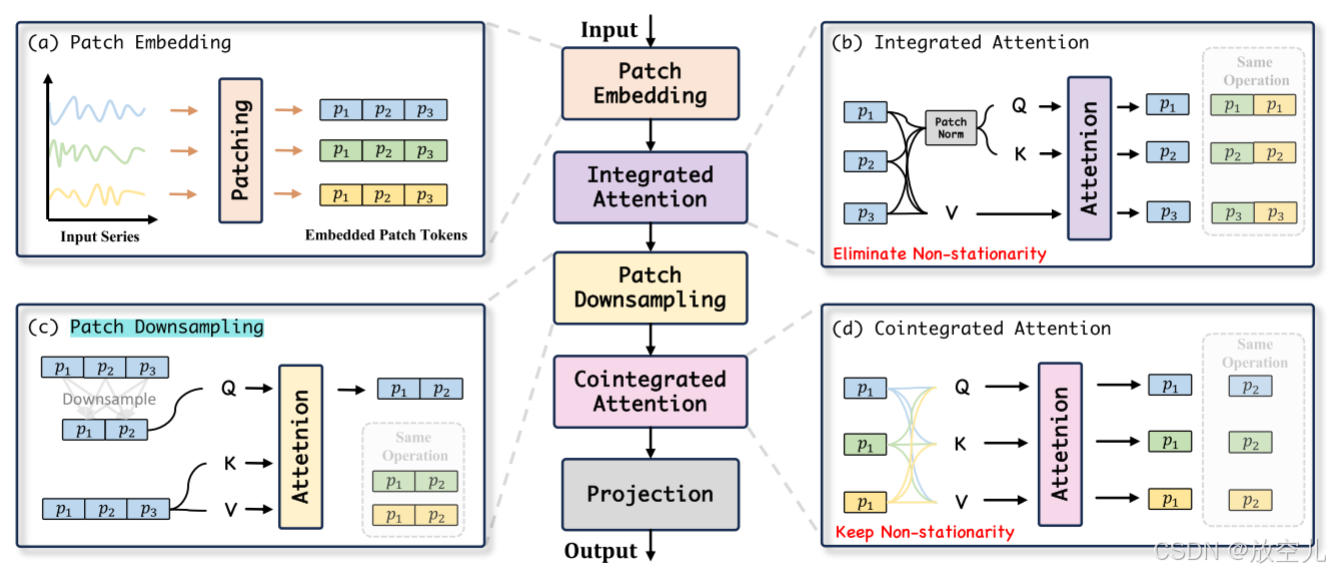
Patch Embedding:将输入序列分割成不重叠的Patch ,并将每个Patch 转换为Patch Token
IntegratedAttention:对相同变量的所有Patch Token之间的依赖关系进行建模。通过消除每个Patch Token内的非平稳性,它减轻了可能由突然的短期变化引起的虚假回归的风险
Patch Downsampling:聚合全局信息并减少Patch的数量,以在每个Patch中封装更丰富的长期特征,同时降低计算复杂度;
Cointegrated Attention:保留了序列的非平稳特征,并在同一时间窗口内对不同变量之间的长期协整关系进行建模。
Patch Embedding:
在这里,每个片段的长度为
,片段的数量
。Embedding(
) 操作通过一个可训练的线性层将每个片段从其原始长度
转换为隐藏维度
。这产生了嵌入片段标记
,其中每个
变量包含
个片段,捕获通常受到快速短期波动影响的局部信息。为了方便起见,我们用
表示单个变量内所有片段的集合,并在后续章节中用
表示在相同时间位置上所有变量的片段。
IntegratedAttention:
对一个变量中的所有patch应用patch-wise归一化:
通过特定的注意力机制(一个平稳的注意力图,可以直接与值相乘,无需后续的去归一化步骤。)设计,允许模型在不被短期波动干扰的情况下,捕捉时间序列中的长期依赖关系:
Patch Downsampling:
在这里,通过使用多层感知器
将
中的
个片段减少到
个片段
。通过在注意力机制中使用降采样后的
作为查询(Query),并将原始的
作为键(Key)和值(Value),我们利用注意力机制的长距离建模能力来动态聚合全局信息。这使得每个片段能够封装更丰富的长期信息,从而有可能捕捉到仅在足够长的时间范围内才会出现的复杂协整关系。
Cointegrated Attention:
这种注意力机制不仅捕捉了变量之间的全局协整关系,还自适应性地评估这些关系的强度:更强的协整关系通过更高的注意力权重反映出来,而较弱的连接则获得较低的权重。最后,嵌入的片段标记 被展开并投影到最终输出
。
实验
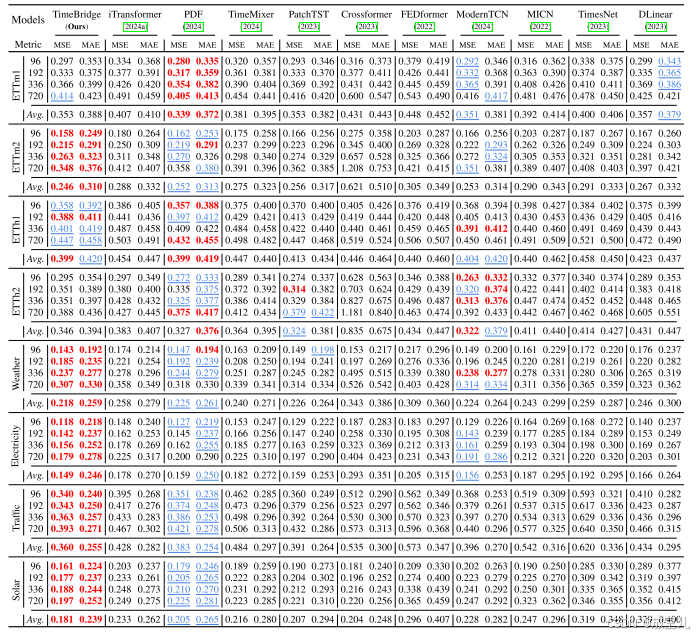
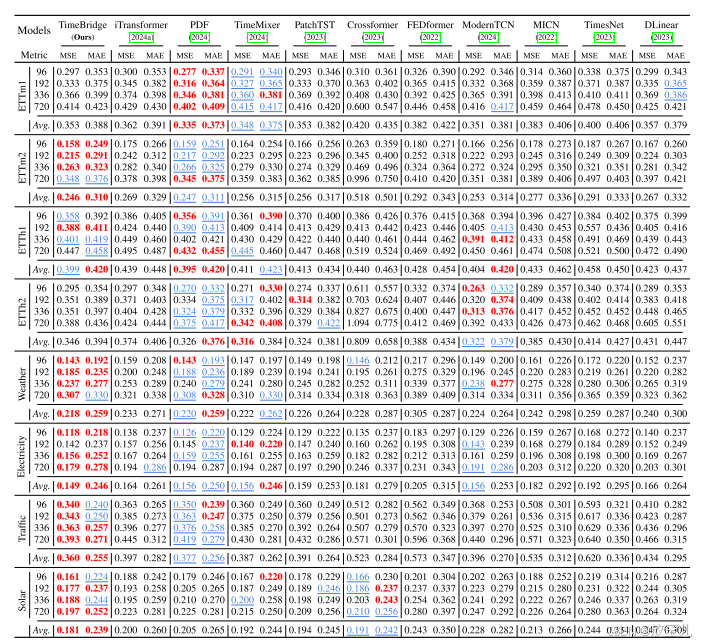
长期预测结果表格1 更侧重于展示原始论文中报告的结果,而 表格2 则展示了通过超参数搜索得到的结果,可能包括一些原始论文中未涉及的模型或设置。
消融实验
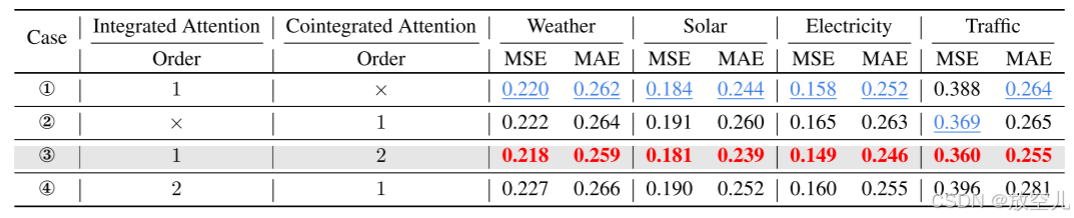
- 评估在集成注意力(Integrated Attention)和协整注意力(Cointegrated Attention)中去除或保留非平稳性的效果

- 研究集成注意力(Integrated Attention)和协整注意力(Cointegrated Attention)对模型性能的影响及其顺序
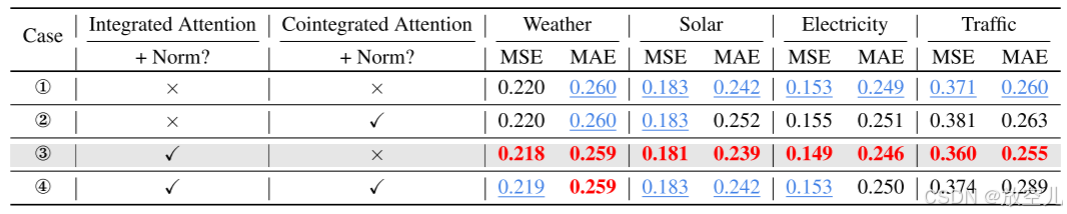
- 在通道较少的场景中,CI建模通常更优,而在通道较多的场景中,CD建模更优。
非平稳性和相关性建模分析
当保留非平稳性时,模型的注意力图在时间维度上分散,关注更广泛的时间段。 去除非平稳性后,注意力图更集中在相邻的时间点上,这符合时间序列中相近时间点通常更相关的规律。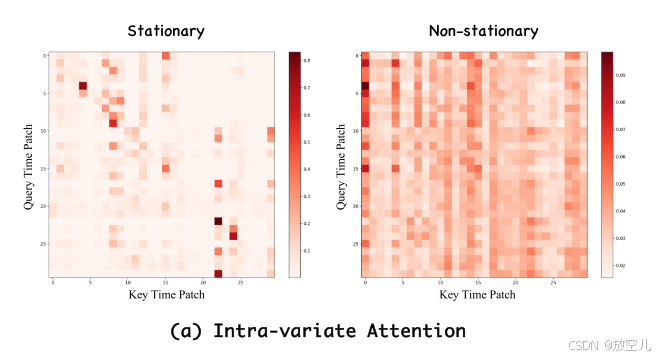
去除非平稳性后,模型的注意力集中在少数几个变量间的关系上。而保留非平稳性可以让模型捕捉到更多样和丰富的关系。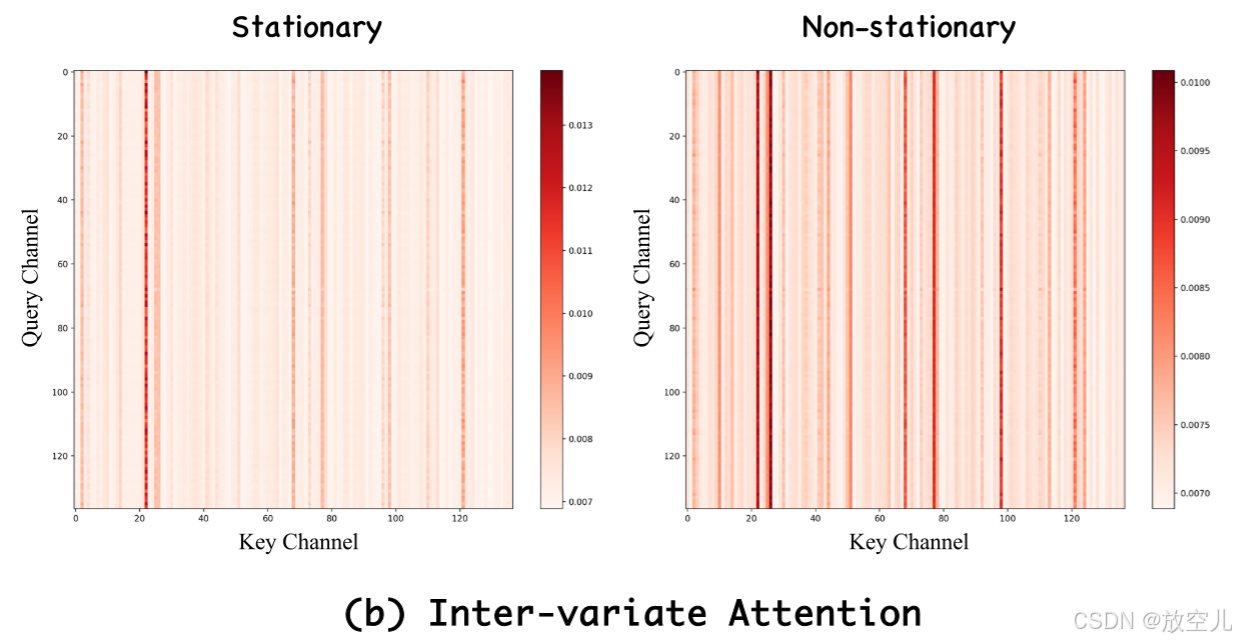
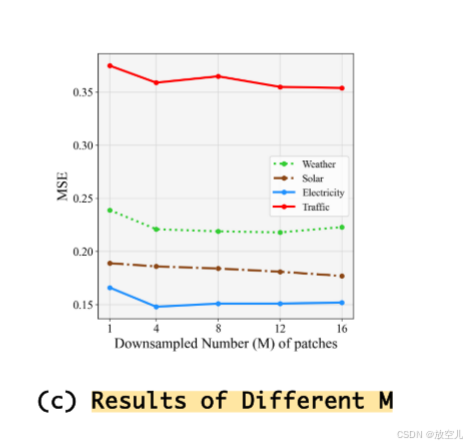
不同下采样率(即减少片段数量)对模型预测性能的影响。对于通道更多、协整性更强的数据集(如太阳能和交通),增加下采样片段数量最初可以改善预测,然而,过多的下采样会增加计算成本,并对通道较少的数据集(如天气)产生负面影响。
idea:
针对长短期预测采用不同的注意力,注意力方向的改近(换一个框架。。。),思想可以学习
代码讲解
代码部分,为了大家更好的阅读和探讨我在飞书进行上传,有问题大家可以在疑问区域直接评论和且代码部分每个公式我也做了详细数学介绍,绝对通俗易懂!
代码位置:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)