MODERNTCN:A MODERN PURE CONVOLUTION STRUCTURE FORGENERAL TIME SERIES ANALYSIS
原文地址:ModernTCN:用于一般时间序列分析的现代纯卷积结构 |打开评论![]() https://openreview.net/forum?id=vpJMJerXHU
https://openreview.net/forum?id=vpJMJerXHU
发表会议:ICLR 2024
代码地址:https://github.com/luodhhh/ModernTCN
作者:罗东浩、王雪
团队:清华大学精密仪器系
目录
什么是modren卷积?以及如何想到将modern convolution应用到时间序列分析中。
Abstract+Conclusion
研究背景:基于Transformer 及 MLP 模型在时间序列分析中迅速崛起并占据主导,卷积在时间序列任务中因性能欠佳而势头渐弱。
研究目的:探讨如何在时间序列分析中更好地利用卷积,使卷积重回该领域。
研究方法:对传统 TCN 进行现代化改进,使其更适用于时间序列任务,提出 ModernTCN,在五个主流时间序列分析任务中达到先进水平,同时保持卷积模型的效率优势,揭示 ModernTCN 具有更大的有效感受野,能更好地发挥卷积在时间序列分析中的潜力,而且它也保持了基于卷积的模型的效率优势,提供了性能和效率的更好平衡。
INTRODUCTION
为什么之前修改卷积没有大的改变?
一些先前基于卷积的模型虽试图让卷积重回时间序列分析领域,但它们专注于设计复杂结构配合传统卷积,忽视卷积本身的更新,且性能不如先进的基于Transformer和MLP的模型。原因是这些模型的ERF有限,阻碍性能提升。
有两点可以改善TCN模型的方法:
图1所示,首先提升感受野。在CV领域,现代卷积都有着很大的卷积核
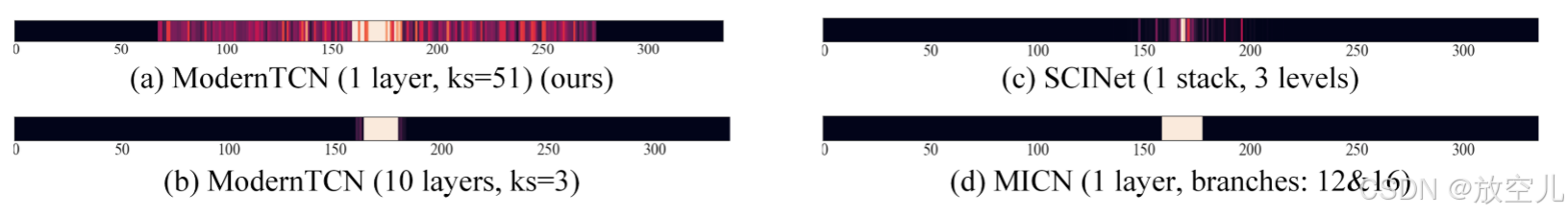
注:SCINet和MICN是两个基于TCN的预测模型,它们的感受野都很小。作者发现ModernTCN中采用大的卷积核所对应的感受野要大很多。
第二,用卷积可以捕获跨变量依赖性,也就是多变量时间序列中变量之间的关系。在PatchTST等最近的时间序列预测文章中,很多方法采用了通道独立策略,这种策略直接将多变量序列预测中变量之间关系忽略了,反而取得了更好的效果。作者认为,变量之间关系仍然重要,但是要精心设计模型结构来捕获。
科普:
- 变量独立嵌入:多变量时间序列中的每个单变量时间序列被视为一个独立的样本,每个样本具有1个特征,并独立进行嵌入处理。
- 变量混合嵌入:整个多变量时间序列被视为一个单一的样本,该样本具有M个特征(M是变量的数量),并作为一个整体进行嵌入处理
由于变量混合嵌入会导致严重的性能下降,所以使用变量独立嵌入进行这些实验。
什么是modren卷积?以及如何想到将modern convolution应用到时间序列分析中。
在计算机视觉中,最新研究专注于优化卷积本身并提出现代卷积。现代卷积受 Transformer 启发,结构与 Transformer 块类似,通常采用大卷积核以增加 ERF。其在 CV 中有效,但在时间序列领域受关注较少。我们打算在时间序列分析中对卷积进行现代化改进,以考察其能否增加 ERF 并提升性能。
idea:卷积可有效地捕捉多元时间序列中变量间的相关性,早期研究(Lai 等人,2018b)已尝试用卷积捕获交叉变量相关性,虽其性能尚不具竞争力,但证明了卷积在此方面的可行性。因此,经适当修改和优化,卷积有望成为捕获交叉变量依赖性的高效方法
ModernTCN block design:
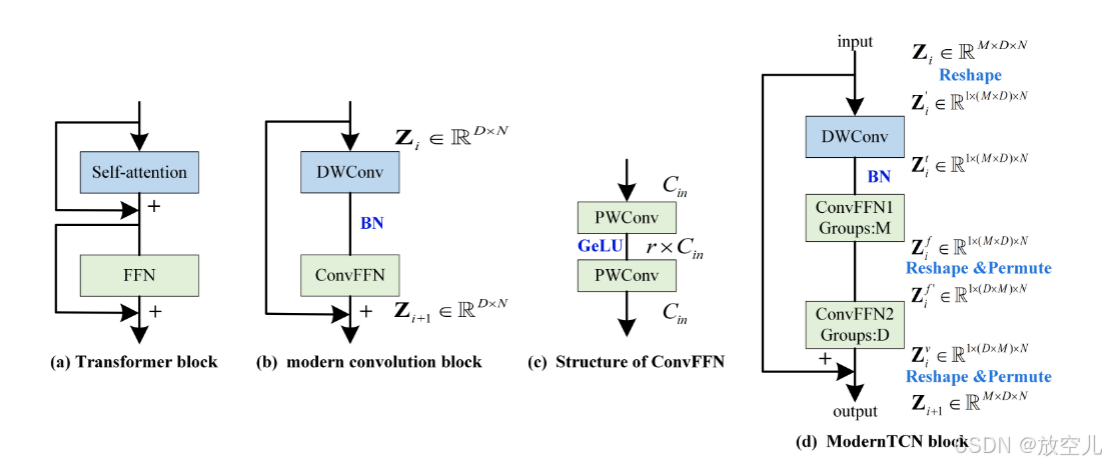
输入首先通过深度卷积(DWConv)和批归一化(BN)。
然后通过两个卷积前馈网络(ConvFFN1 和 ConvFFN2),每个网络都有其自己的组(Groups)。
ConvFFN1 使用 M 作为组数,而 ConvFFN2 使用 D 作为组数。
每个 ConvFFN 的输出通过 reshape 和 permute 操作调整形状,然后与残差连接相加。
最终输出通过 reshape 和 permute 操作调整回原始的维度。
MODERNTCN
1D卷积块的重新设计以及存在的问题
1、DWConv负责在每个特征的基础上学习token之间的时间信息,其作用与Transformer中的自注意力模块相同。
2、ConvFFN类似于Transformer中的FFN模块,由两个PWConvs组成,采用倒瓶颈结构,ConvFFN块的隐藏通道比输入通道宽r倍,用于独立学习每个令牌的新特征表示。 这种设计结构把时间信息和特征信息的混合给分开了。在这个分开的过程中,DWConv这个部分主要负责在时间维度上处理信息,ConvFFN这个部分主要负责在特征维度上处理信息。而传统的卷积呢,它是把时间和特征这两个方面的信息一起处理的。现在我们这种把时间和特征分开处理的设计(解耦设计),有两个好处:一个是能让我们要完成的任务变得更容易学习和理解,另一个是可以减少计算的复杂程度,让计算变得更简单、更快。
注:在本文中,设计了一种瓶颈结构来实现这一目标,这是一种简单直接的方法。具体来说,在输入ConvFFN1和ConvFFN2之前,通过一个投影层将变量数量投影到M',其中M'比M小很多。然后在ConvFFN1和ConvFFN2处理后,再用另一个投影层将变量数量恢复到M。用不同的M'进行实验来验证这个解决方案。如表1所示,作者的方法可以显著减少内存使用,且性能仅有少许下降。这个结果证明了交通数据集中的862个变量之间存在冗余。因此,可以根据这些变量之间的依赖关系,学习到它们的低秩近似。这种低秩近似有助于在不过多降低性能的情况下减少内存使用。

3、基于借鉴CV经验对1D卷积的现代化改进,发现在时间序列任务中该改进几乎未提升性能,原因是上述设计未考虑时间序列的变量维度,图2(b)中设计的卷积块堆叠骨干网络不能妥善处理此维度,因交叉变量信息在多元时间序列中关键,所以需要更多时间序列相关修改,以使现代1D卷积更适用于时间序列分析。
时间序列中如何维持变量维度以及为什么维持?
为什么维持变量维度?
在计算机视觉中,通常将每个像素的3通道RGB特征嵌入到一个D维向量中,以混合RGB通道的信息。 传统的变量混合嵌入(例如,简单地将M个变量嵌入到每个时间步的D维向量中)不适用于时间序列数据。 时间序列中的变量差异远大于图像中RGB通道的差异,仅使用嵌入层无法学习变量之间的复杂依赖关系,甚至可能丢失变量的独立特性。 这种嵌入设计忽略了变量维度,无法进一步研究变量之间的依赖关系。
解决策略
提出了一种分块的变量独立嵌入方法。
将长度为L的M变量输入时间序列
划分为N个大小为P的块,并在适当的填充后进行划分。
划分过程中的步长为S,这也表示两个连续块之间不重叠区域的长度。
然后将这些块嵌入到D维嵌入向量中。
科普:
1、嵌入过程

2、注:在原论文pipeline章节中讲了不同任务的pipeline
3、traffic 数据集的变量比其他数据集多很多,直接将模型应用于该数据集会导致内存占用过高。因为多元时间序列中的变量相互依赖,所以一种可能的解决办法是,当变量数量M很大时,为这些变量找到低秩近似。比如,FEDformer(2022)在频域中使用低秩近似变换来提高内存效率,Crossformer(2023)使用少量固定的路由器来聚合所有变量的信息以节省内存使用。
DWConv
DWConv 原本是用于学习时间信息的,但仅靠它同时学习跨时间和跨变量的依赖性有困难,所以不能让它负责跨变量维的信息混合。于是,把原本只与特征无关的 DWConv 算法改成了与特征和变量都无关,这样它就能单独学习每个单变量时间序列的时间相关性。而且,DWConv 中使用了大核函数来增大有效感受野(ERF),从而提升了时域建模的能力。用公式表示为:,其中
表示某种函数关系,kernel size 表示核函数的大小。
ConvFFN
因为 DWConv 是特征和变量都无关的,所以 ConvFFN 应该作为补充来混合跨特征和变量维度的信息。一种简单的方法是通过单个 ConvFFN 来共同学习特征和变量之间的依赖性,但这种方法会导致更高的计算复杂度和更差的性能。因此,通过将 PWConvs 替换为分组的 PWConvs 并设置不同的组数,将单个 ConvFFN 进一步分解为 ConvFFN1 和 ConvFFN2。ConvFFN1 负责为每个变量学习新的特征表示,ConvFFN2 负责捕捉每个特征的跨变量依赖性。经过上述修改,得到了如图 2(d)所示的最终 ModernTCN 块。并且 DWConv、ConvFFN1 和 ConvFFN2 中的每一个都只在时间、特征或变量维度中的一个上混合信息,这保持了现代卷积中解耦设计的理念。
整体架构
在嵌入(embedding)之后,嵌入向量被输入到主干网络中,以捕获跨时间和跨变量的依赖关系,并学习信息丰富的表示
。
这个过程可以用公式表示为:
主干网络(Backbone):
主干网络由堆叠的 ModernTCN 块组成。每个 ModernTCN 块以残差方式组织。
在第 个 ModernTCN 块中的前向过程是:
其中,,
是第
个块的输入。
○ 的定义如下:
- 当 时,
- 当时,
○ 表示 ModernTCN 块。最终的表示
将被进一步用于多个时间序列分析任务。
实验
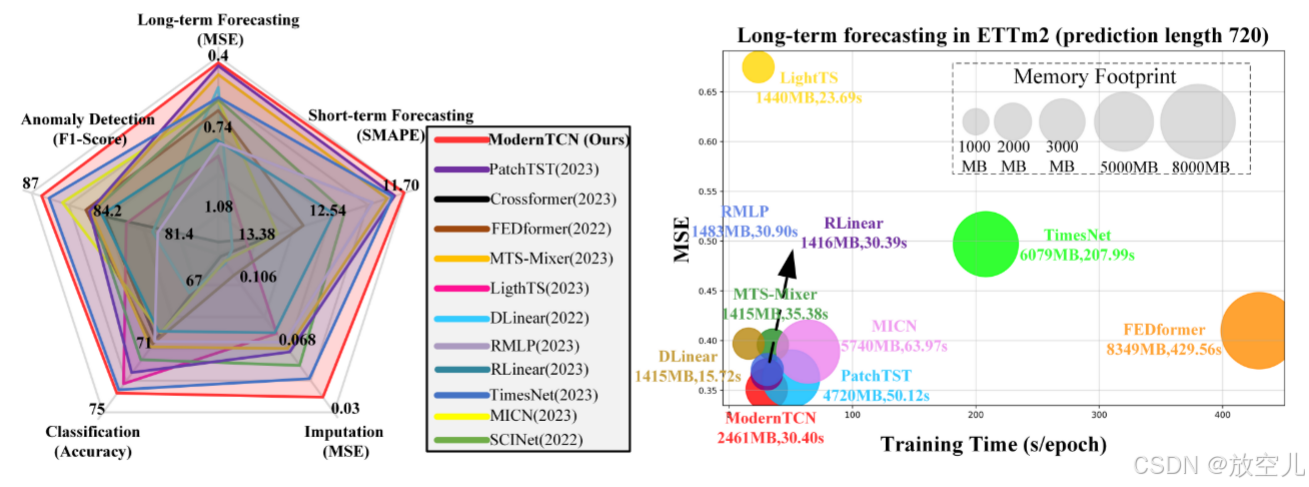
注:作者在不同任务(长短期预测、插值、分类和异常检测)上都做了实验,效果基本都趋于领先,只有像是weather或者traffic大数据集的效果稍弱一丢丢。
科普:几种评价指标的计算方式
,
T:通常表示时间序列的长度,即总的时间点或观测值的数量。
P:通常表示时间序列中用于预测的时间间隔或滞后期数。例如,在某些模型中,可能会使用前P个时间点的数据来预测下一个时间点的值。
对于单变量时间序列,naive 方法的预测是简单地取最后一个已知的观测值作为下一个时间点的预测值。
对于多变量时间序列,每个变量的预测可以独立地使用其自身的最后一个观测值。
补充:
M4 数据集只包含单变量时间序列,所以在 ModernTCN 和 Crossformer 中删除了交叉变量分量。模型中用于处理多个变量之间交互关系的部分。PatchTST和DLinear没有考虑交叉变量相关性
基于多层感知机(MLP)的模型为了实现轻量级的骨干结构,往往会舍弃一些特征维度。然而,这样做会使得模型的表示能力受到限制,进而导致分类性能不佳。
ModernTCN在分类任务中每个训练周期平均节省55.1%的时间(3.19秒 VS 7.10秒),在异常检测任务中平均节省57.3%的时间(132.65秒 VS 310.62秒)。
模型分析
观图4后,ModernTCN 在性能方面与最先进的基于 Transformer 的模型竞争表现良好甚至更优,且作为纯卷积模型,比基于 Transformer 的模型效率更高,训练速度更快,内存使用更少。ModernTCN 在所有五个任务中都优于所有基于 MLP 的基线,因为其具有更好的表示能力,而基于 MLP 的模型为减少内存使用采用轻量级骨干,导致表示能力不足和性能较差。尽管 ModernTCN 在内存使用上略逊一筹,但由于卷积的快速浮点运算速度,其运行时间效率与一些基于 MLP 的基线几乎相同。综合考虑性能和效率,ModernTCN 在一般时间序列分析中更具优势。
通过扩大卷积核尺寸来增加 ERF: ModernTCN 通过扩大卷积核尺寸来增加感受野(ERF),而不是像其他传统TCN(时序卷积网络)那样通过堆叠更多的层。
纯卷积结构中增加 ERF 的有效方式: 在纯卷积结构中,扩大卷积核尺寸是增加感受野的一种更有效的方式。 ERF 理论: 根据Luo et al. (2016)的理论,纯卷积模型中的感受野(ERF)与 O(ks×nl) 成正比,其中 ks 表示卷积核尺寸,nl 表示层数。 感受野(ERF)与卷积核尺寸呈线性增长,而与层数呈次线性增长。 通过扩大卷积核尺寸获得更大的 ERF: 通过扩大卷积核尺寸,ModernTCN 可以更容易地获得更大的感受野(ERF),从而进一步提升性能。
讨论(重点了解):
1、modernTCN和Times Net的有啥实质性区别?
思路、动机、方法完全不同。共同点都是用了卷积结构,但timesnet用的是2d卷积,这个用的是1d卷积,所以还是不同的。
2、和Cross-LKTCN:Modern Convolution Utilizing Cross-Variable Dependency for Multivariate Time Series Forecasting有相似处
3、要实现多变量预测单变量要怎么实现呢?
一种方案是把一些协变量embedding之后作为新的变量,将单变量扩充成多变量。另一种方案是修改模型中对多变量间建模的模块超参数,直接处理单变量。
4、在ModrenTCN,中为什么用batchnorm不用layernorm?
1. BatchNorm 更适合卷积结构:
-
BatchNorm 的设计初衷:BatchNorm 是为卷积神经网络(CNN)设计的,它通过对每个 mini-batch 的每个通道进行归一化,能够有效缓解内部协变量偏移(Internal Covariate Shift)问题。
-
卷积的特性:在卷积操作中,特征图的每个通道是独立处理的,BatchNorm 对每个通道进行归一化,能够更好地适应卷积的特性。
-
LayerNorm 的局限性:LayerNorm 是对每个样本的所有特征进行归一化,更适合全连接层或 Transformer 这样的结构,但在卷积网络中可能会导致特征图的空间信息丢失。
2. BatchNorm 对 mini-batch 的依赖性:
- BatchNorm 依赖于 mini-batch:BatchNorm 的归一化是基于 mini-batch 的统计量(均值和方差),这使得它在训练时能够动态适应数据分布的变化。
- ModernTCN 的训练数据:如果 ModernTCN 的训练数据是时间序列数据,且 mini-batch 的大小足够大,BatchNorm 可以很好地工作。
- LayerNorm 的独立性:LayerNorm 不依赖于 mini-batch,而是对每个样本进行归一化。虽然这在某些情况下(如小 batch 或在线学习)更有优势,但在 ModernTCN 中可能不如 BatchNorm 有效。
3. BatchNorm 对时间序列数据的适应性:
时间序列的特性:时间序列数据通常具有时间依赖性,BatchNorm 能够通过 mini-batch 的统计量捕捉到这种依赖性。
LayerNorm 的局限性:LayerNorm 对每个时间步独立归一化,可能会破坏时间序列的时间依赖性,导致模型性能下降。
4. BatchNorm 的加速训练效果:
加速收敛:BatchNorm 能够加速模型的训练过程,因为它减少了内部协变量偏移,使得梯度更加稳定。
LayerNorm 的效果:虽然 LayerNorm 也能加速训练,但在卷积网络中,BatchNorm 的效果通常更好。
5. BatchNorm 的数学表达:

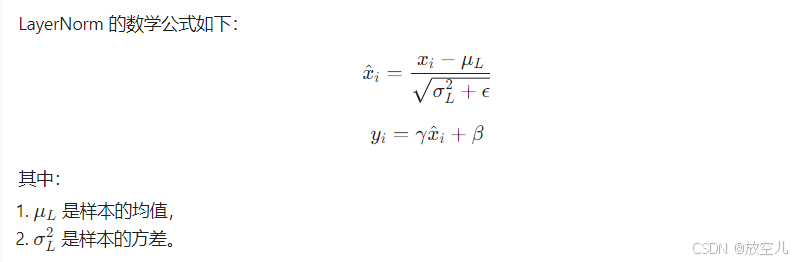
6. BatchNorm 的潜在问题与解决方案:
小 batch 问题:当 batch size 较小时,BatchNorm 的统计量可能不准确。可以通过以下方法缓解:
- 使用 Group Normalization 或 Instance Normalization*作为替代。
- 使用Batch Renormalization 或 Moving Average BatchNorm。
- 推理时的统计量:在推理时,BatchNorm 使用训练时计算的移动平均值,而不是 mini-batch 的统计量,这可以保证推理时的稳定性。
总结:
在 ModernTCN*中使用 BatchNorm而不是 LayerNorm,主要是因为:
- 1. BatchNorm 更适合卷积结构,能够更好地处理时间序列数据。
- 2. BatchNorm 依赖于 mini-batch 的统计量,能够捕捉时间序列的时间依赖性。
- 3. BatchNorm 在卷积网络中的效果和稳定性已经得到广泛验证。
当然,如果任务场景特殊(如 batch size 非常小),也可以尝试使用 LayerNorm 或其他归一化方法。
代码
代码部分,为了大家更好的阅读和探讨我在飞书进行上传,有问题大家可以在疑问区域直接评论和且代码部分每个公式我也做了详细数学介绍,绝对通俗易懂!
代码位置:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)