Transformer:Positional Encoding
目录一、为什么需要位置编码?1.1 问题背景1.2 深层分析1.2.1 丧失顺序信息1.2.2 语义信息的丢失1.2.3 无法区分长短依赖1.2.4 模型的性能下降1.3 Solution二、位置编码长什么样三、具体数值例子四、这样做的好处是什么?4.1 Why?4.2 如何实现推断更长序列的能力?4.3 举个例子五、位置编码是怎么加进去的?六、相对 vs 绝对位置编码6.1 绝对位置编码(Abs
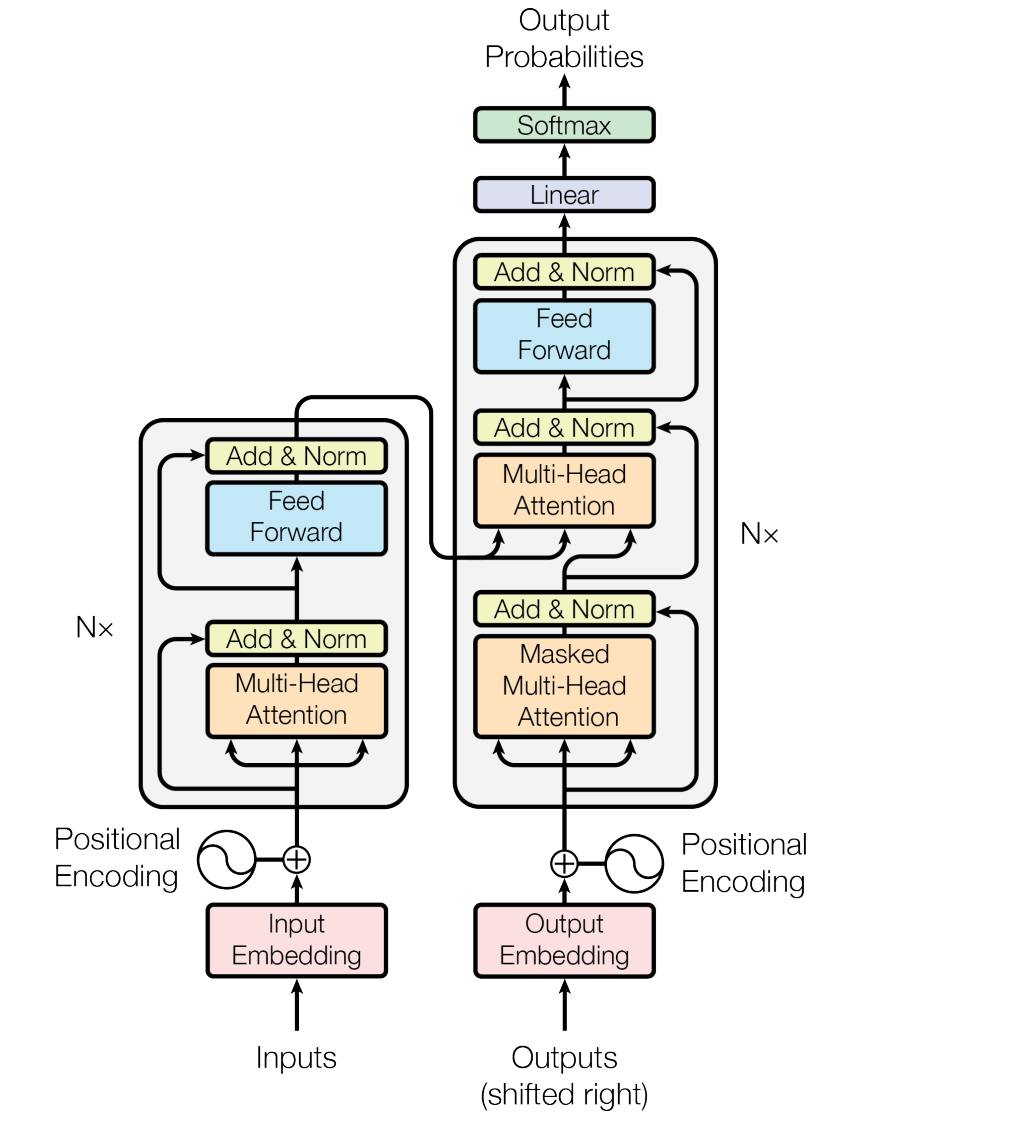
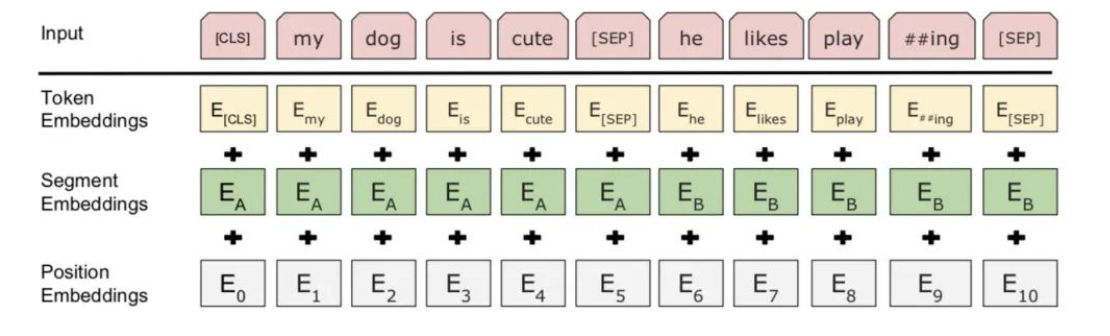
在Transformer的输入中,会使用到Positional Encoding,本文会从多个维度对Position Encoding进行解析,下图取自:《Attention is all you need》
目录
6.1 绝对位置编码(Absolute Positional Encoding)
八、变种:Learnable Positional Encoding
一、为什么需要位置编码?
1.1 问题背景
我们先回顾一下,以前在处理序列数据时,所用的RNN模型。“RNN模型是一种深度学习模型,经过训练后可以处理顺序数据输入并将其转换为特定的顺序数据输出。顺序数据是指单词、句子或时间序列数据之类的数据,其中的顺序分量根据复杂的语义和语法规则相互关联。RNN是一种由许多相互连接的组件组成的软件系统,这些组件模仿人类进行顺序数据转换的方式,例如将文本从一种翻译语言转换成另一种语言。”
下图为RNN示意图(取自:Cloud Computing Services - Amazon Web Services (AWS)):
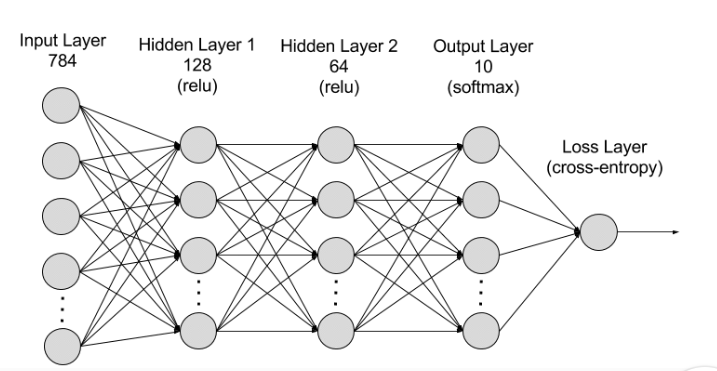
可以看到,RNN的结构简单,可以处理序列数据,但是它无法并行,这是一个缺点。另外RNN是一个链式结构,信息的传递是通过乘以权重矩阵W一路传下去,问题来了,如果W < 1, 且是长距离依赖,那最后的W矩阵的值会特别小,这就会造成信息丢失
紧接着,LSTM出现了,它引入了门控机制,能记住长期信息,缓解梯度消失。但是,这玩意结构太复杂了,计算还慢,且仍然无法并行。下图为LSTM的结构图:
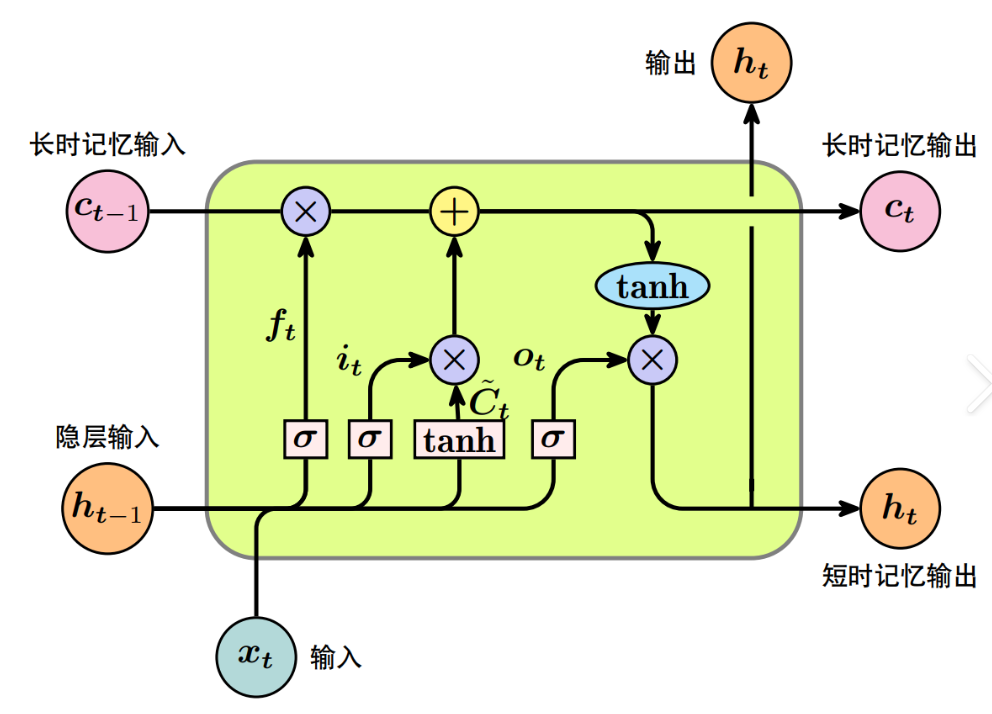
(当然,还有GRU,这里就不过多介绍了)
在2017年,Google提出了Transformer,原论文是:《Attention is all you need》,它解决了并行性以及长距离依赖等问题。
并行性虽然解决了,可又萌生了新的问题:Transformer是全部token一起输入,它无法“感知顺序”!
于是,我们必须手动添加位置信息,告诉模型:
"第一个词是句首,第二个词是句中,第三个是结尾"....
这就靠Positional Encoding。
1.2 深层分析
接下来,让我们更深层次的分析为什么需要Positional Encoding?
在分析之前,我想我们先来看看Attention的基本工作原理:
在Transformer中,自注意力机制通过计算输入的Query和Key之间的相似度(通常是点积),然后使用这个相似度作为权重,对输入的Value进行加权求和。
公式如下:
计算过程是基于Query和Key的相似度,而不是词语的顺序。怎么理解这句话?
在 Self-Attention 中,词嵌入通过与权重矩阵 和
计算生成 Query (Q) 和 Key (K) 向量,并通过计算它们在高维空间中的相似度来决定它们之间的关系。Attention 机制关心的是 Q 和 K 的相似度(点积),而不是它们在输入序列中的位置或顺序。
(我不希望这句话的解释给读者造成一种误解:认为Attentino机制完全不关心顺序。只是说,在没有Positional Encoding的情况下,Attention的确无法感知顺序信息)
举个例子:
下图有一个三维空间,里面有一个study向量和一个tower向量,Attention关心的是这两个向量之间的距离:
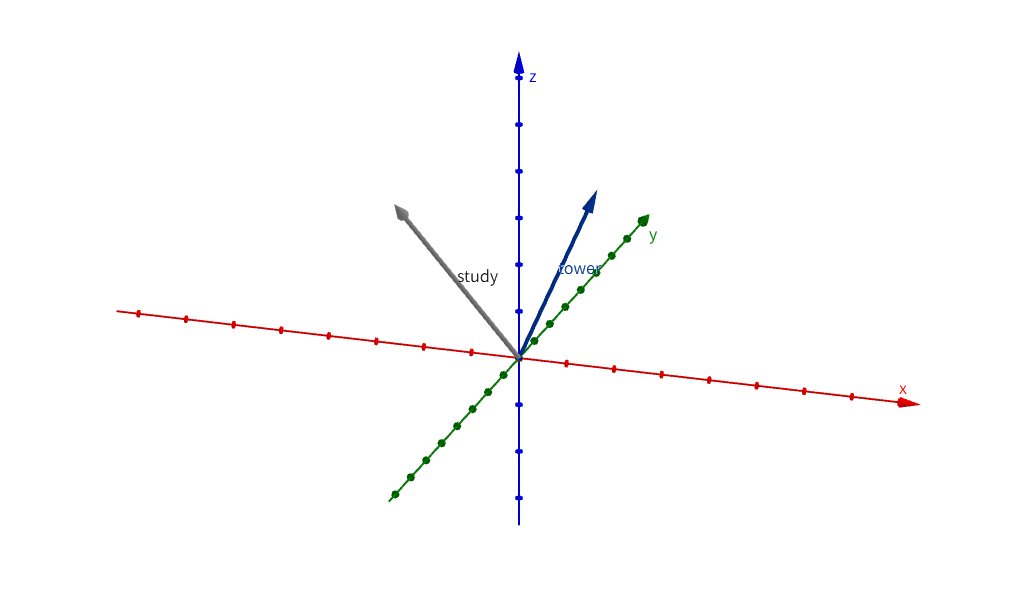
了解完Attention机制的基本原理之后,问题就显而易见了。由于Attention机制是基于词和词之间的相似度来计算的,它并不关心词语在序列中的顺序。这也就意味着,如果我们打乱输入词的顺序,Attention输出的加权和是一致的,也就是说,顺序的变化并不会直接影响Attention的计算结果。
举个例子:
- 输入句子: "我 喜欢 学习 机器学习"
- 如果将词序打乱成“喜欢 机器学习 我 学习”,注意力机制仍然会计算出相同的加权和,因为它没有受到顺序打乱的影响。
继续分析:Attention的输出的加权和若一致会造成什么后果?
1.2.1 丧失顺序信息
我们知道,在NLP和其它时序任务中,顺序信息非常关键。就比方说,词语在句子中的位置决定了它们之间的关系,改变顺序通常会改变句子的语义。而此时若Attention输出的加权和没有变化,模型就无法感知词语在序列中的顺序。
最终就会导致模型对语法结构的理解能力将变得非常弱,无法捕捉到像主语、谓语、宾语等总要信息。
我们举个例子来直观的说明:
句子A:“我 爱 编程”
句子B:“编程 爱 我”
这两个句子的语义完全不同。此时,如果Attention输出加权和相同,模型将无法区分句子A和句子B。
1.2.2 语义信息的丢失
在开始之前,我们先来了解一下语义信息,它是通过词语在上下文中的相对位置来建立的。而如果位置不被考虑,模型将无法捕捉到这些信息之间的细微差异。就比如说:“狗咬人”和“人咬狗”虽然包含相同的词,但它们在语义上却有着根本的区别。
也就是说,语义信息的丢失会导致模型在处理复杂的任务时,特别是需要考虑上下文的任务(如机器翻译,语音识别等)时,表现不佳。
1.2.3 无法区分长短依赖
在文本中,词与词之间有不同长度的依赖关系。Attention机制本身应该能够根据Query和Key的相似度来捕捉长短依赖。
如下图所示:
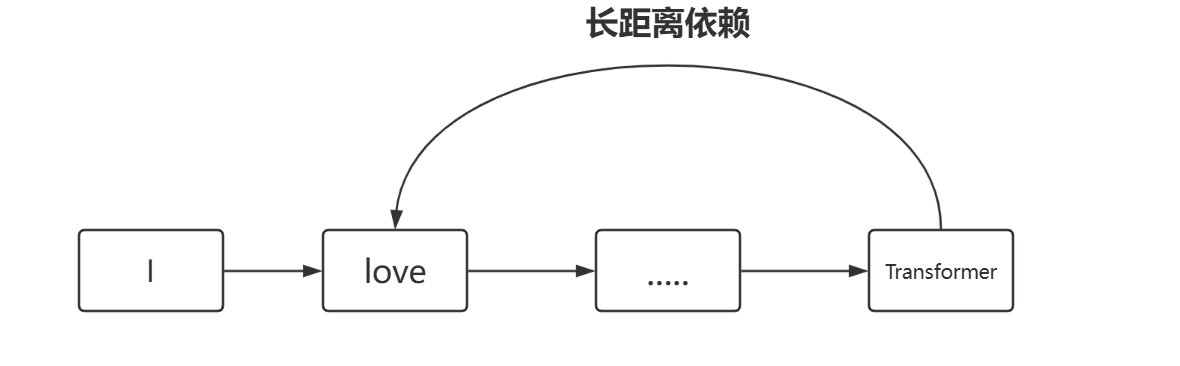
可如果输出的加权和不变,模型将无法区分短期和长期依赖关系,这会导致模型对长句子或长距离依赖的处理非常差,进而影响翻译、生成任务等应用。
1.2.4 模型的性能下降
这是为什么呢?
实际上,Attention机制的强大之处就在于它能够根据Query和Key之间的关系动态调整加权和,从而灵活地关注句子中重要的部分。可如果加权和总是一样,模型的学习能力和表达能力将受到限制,表现会下降。
特别是在多层Transformer结构中,每一层的Self-Attention都依赖于前一层的计算结果。如果加权和始终不变,整个网络变得非常有限,无法有效学习复杂的模式。
1.3 Solution
为了解决上述问题,Transformer引入了位置编码(Positional Encoding)。通过对输入的词嵌入添加一个额外的位置编码,使得Transformer不仅能够理解词的语义,还能理解这些词在句子中的相对位置,从而恢复词序对语义的影响,同时提升了模型对时序数据的处理能力。
二、位置编码长什么样
Transformer论文中使用的一种正余弦函数编码方式(Sinusoidal Positional Encoding):
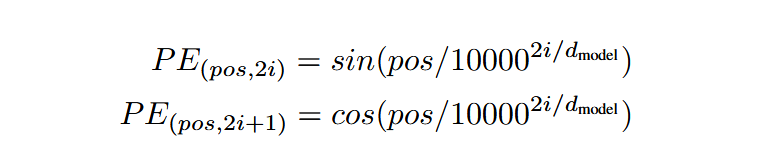
对于序列中第pos个位置,生成一个长度为d的向量,每个维度如下定义:
i是序列中的位置索引,即输入序列中第i个词的位置(例如:i从0开始计数,i am studying Transformer, studying_i = 2)
j表示维度索引的一半,用于控制不同频率的正弦和余弦函数。具体来说,若位置编码的维度为d,则j的取值范围是[0, (d/2) - 1]。每个j对应位置编码向量的两个维度:2j (偶数维度), 2j + 1(奇数维度),分别由正弦和余弦函数生成。频率由分母项决定,随着j增大,频率逐渐降低。
三、具体数值例子
方便起见,我们只取pos=0,1,2三个位置,假设embedding维度d=4,来看看生成的PE:
| pos | 维度0(sin) | 维度1(cos) | 维度2(sin) | 维度3(cos) |
| 0 | 0.0000 | 1.0000 | 0.0000 | 1.0000 |
| 1 | 0.8415 | 0.5403 | 0.0100 | 1.0000 |
| 2 | 0.9093 | -0.4161 | 0.0200 | 1.0000 |
(数值近似,真实值会更复杂)
这个正余弦的频率是随维度变化的,低纬度代表粗略信息,高纬度代表细节差别。
四、这样做的好处是什么?
我们先来看看原论文中是怎么解释的:
”We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.“
意思是说使用正余弦位置编码(sinusosoidal position encoding)可能让模型在遇到比训练时更长的序列时,依然能有效地进行推理和处理。
4.1 Why?
回答这个问题之前,我们先来看看正余弦位置编码的核心特点是什么:
它是基于周期性函数(正弦和余弦)。这种编码方式具有周期性,因此对于较大的位置,编码并不会变得“完全不同”,它可以通过重复的模型来表示新的位置。即使训练时没有见过某个位置,模型也能理解并“推断”它的关系。
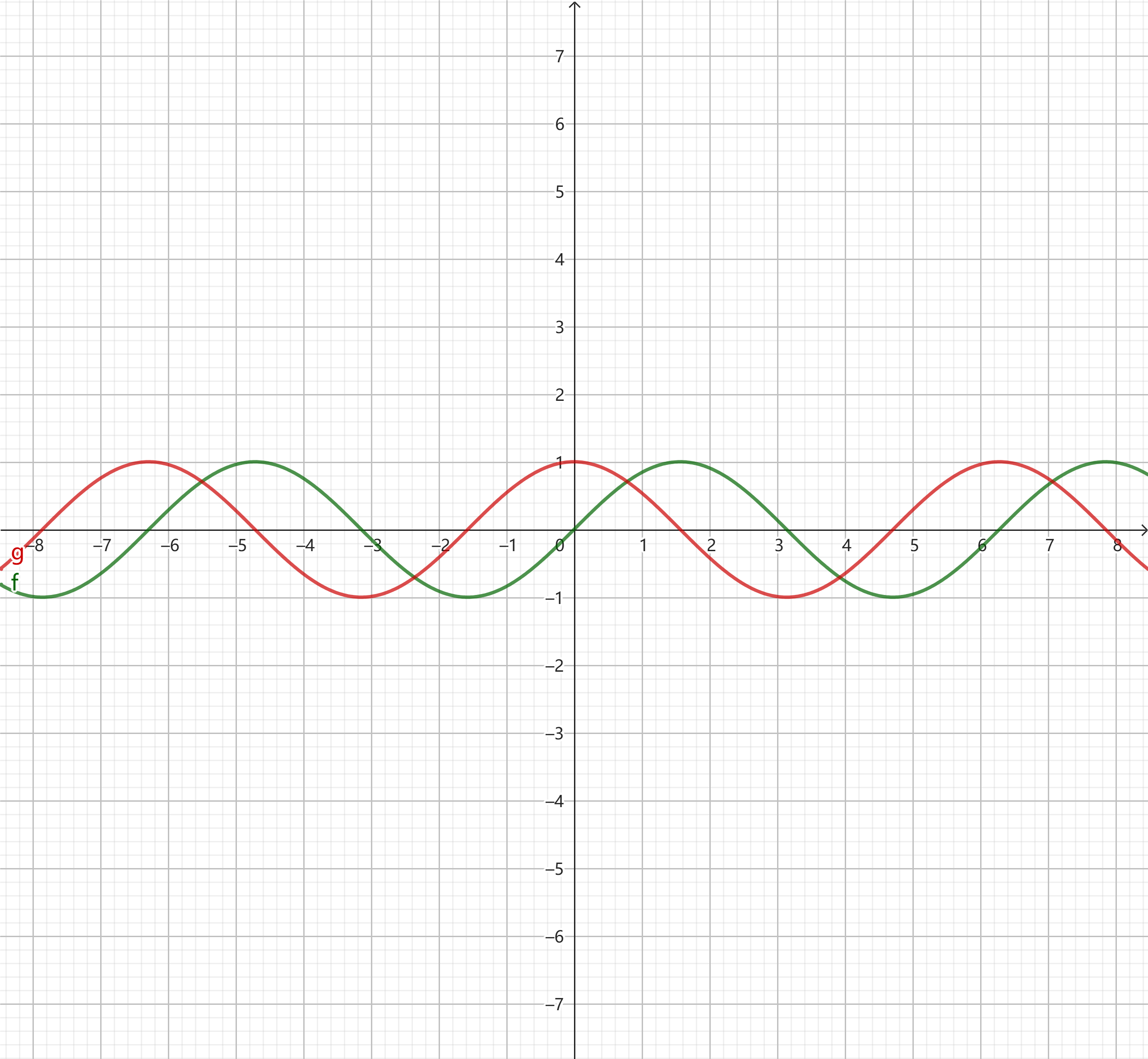
4.2 如何实现推断更长序列的能力?
我们从两个维度来进行分析:
1、正余弦函数中的指数部分保证了低频(小位置值)和高频(大位置值)之间的映射。由于这些频率的变化,模型能通过已见过的模式推测出新位置的模式。
这里提到的低频和高频就是指:
- 低频:表示位置值较小的部分(比如序列中的前几个位置),它的变化较慢;
- 高频:表示位置值较大的部分(比如序列中的后面位置),它的变化较快
看到这里,读者可能还有些疑惑?频率的变化和位置有什么关系呢?
我们知道,在位置编码中,正余弦函数是通过指数部分来调节频率的。具体来说:
对于每个维度i,频率会随着维度的增加而变得更高。低维度会用低频来编码位置,高纬度则会用高频来编码位置。这样做的好处是什么?不同的维度会捕捉序列中不同层次的位置信息!
2、我们知道,位置编码是通过固定的数学公式生成的,而不是学习到的(learned),它能够对比训练时看到的长度外的序列进行推理,尤其是对于更长的序列,模型仍然可以通过继续沿着相同的频率模式进行外推
4.3 举个例子
假设训练时模型只看到了最大长度为 512 的序列,然而使用正余弦编码时,模型会看到位置编码随着位置增加而不断变化的规律。当你给它一个更长的序列,比如长度 600 的序列时,模型会利用已经学习到的周期性规律来理解位置 513 到 600 对应的编码,并不会出现“跳跃”或“不连续”的现象。
这也就是为什么正余弦编码被认为能处理比训练时更长的序列。它为位置提供了一个固有的、持续可扩展的规律,而不是局限于训练时的长度。
稍微总结一下:它是通过一个有周期性的函数生成的编码,可以自然地适应比训练时序列更长的情况,而无需重新训练模型!
五、位置编码是怎么加进去的?
(这一章节优点水,见谅)
位置编码和词嵌入的维度是一样的,所以直接把它们相加即可:
input_embedding = word_embedding[pos] + positional_embedding[pos]最后模型的输入就是:
词语本身语义 + 它在句子中的位置
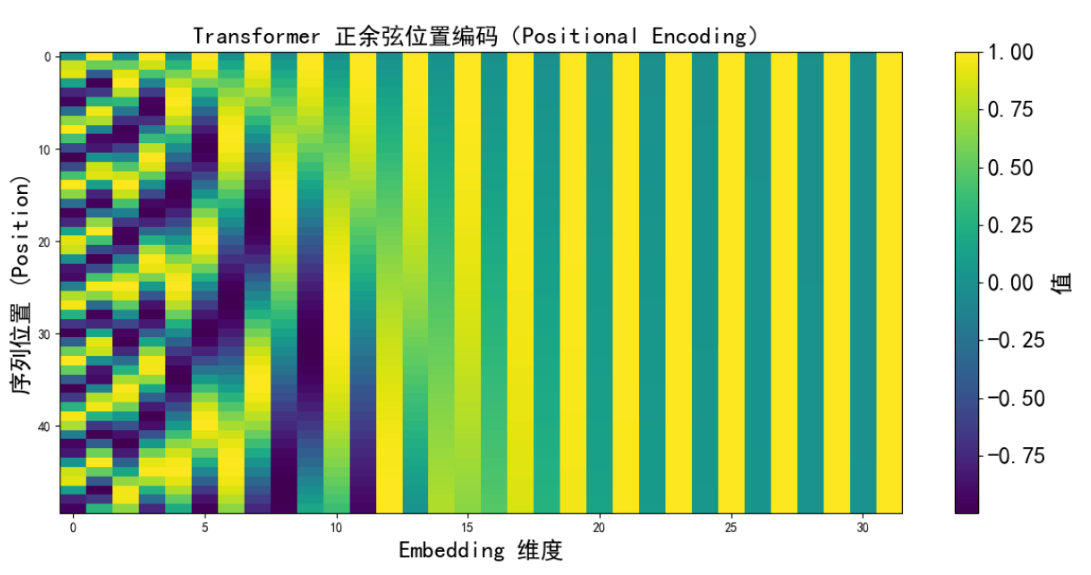 上面这张图展示的就是Transformer正余弦位置编码的热力图,横轴是Embedding维度,纵轴是序列中的位置,我们可以看到:
上面这张图展示的就是Transformer正余弦位置编码的热力图,横轴是Embedding维度,纵轴是序列中的位置,我们可以看到:
类似波浪的纹理它所表示的就是不同频率的正弦/余弦交替,左边的维度变化比较慢(低频)也就是说它表示的是宏观位置,而右边的维度波动比较块(高频)它是在捕捉局部细节。
这就让模型可以通过组合不同频率的模式,来学习出词与词之间的相对位置关系,而不是死记某个“绝对位置”。
六、相对 vs 绝对位置编码
6.1 绝对位置编码(Absolute Positional Encoding)
(图片取自:QIN)
我们先来看看原理,绝对位置编码会为每个词语分配一个唯一的编码,该编码完全依赖于位置本身。基于以下公式生成:
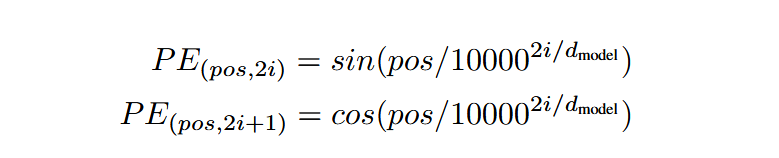
绝对位置编码对于一些任务,比如说模型需要考虑两个词之间的相对位置(如语法结构或翻译中的对齐关系),它并未直接提供这种信息。
6.2 相对位置编码
相对位置编码对比绝对位置而言,它不关注词在序列中的绝对位置,而是关注词之间的相对距离。这张方法能够很好的捕捉词语之间的依赖关系,尤其是在长序列中。
在Transformer中引入了相对位置编码后,每个词对其它词的关注不再依赖于其在序列中的绝对位置,而是依赖于它与其它词的距离。最著名的相对位置编码方法来自Transformer-XL,它通过以下公式来计算位置偏移:
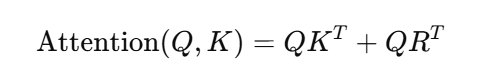
其中,是一个相对位置偏置矩阵,表示了Query和Key之间的相对距离。
6.3 对比
| 编码方式 | 解释 | 举例 |
|---|---|---|
| 绝对位置编码 | 你在第几个位置? | “我在第4个单词” |
| 相对位置编码 | 我和你之间的距离是多少? | “我离你差2个单词” |
为什么相对位置更有优势?
举个例子:
句子A:他[看着]我
句子B:他[盯着]我
虽然"看着"和“盯着”在相同位置,但它们与“我”和“他”的相对距离一致。语言的依赖性很多时候是“我和谁的距离”,而不是“我处在第几位”
七、相对位置的实现
7.1 Transformer-XL (相对位置偏置)
Transformer-XL 是引入相对位置编码的开创性工作之一。该模型通过在 Attention 机制中引入一个相对位置偏置来替代绝对位置编码,特别适用于处理长文本和记忆机制。
在Transformer-XL中,作者通过在Query和Key之间计算相对位置的偏置,来调整计算出的Attention分数。也就是说,偏置项是一个依赖于Query和Key之间距离的矩阵:
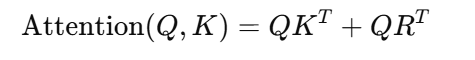
(这个偏置矩阵R可以通过学习得到,或者通过固定的公式生成)
代码实现:
import torch
import torch.nn as nn
class TransformerXLRelativePositionBias(nn.Module):
def __init__(self, max_len, d_model):
super(TransformerXLRelativePositionBias, self).__init__()
# 创建相对位置偏置的参数
self.position_bias = nn.Parameter(torch.randn(max_len, max_len))
self.d_model = d_model
def forward(self, q_len, k_len):
# 通过切片获取相对位置偏置
bias = self.position_bias[:q_len, :k_len]
return bias
# 假设 max_len=512, d_model=256
max_len = 512
d_model = 256
rel_pos_bias = TransformerXLRelativePositionBias(max_len, d_model)
# 计算前 50 个位置的相对位置偏置
q_len = 50
k_len = 50
bias = rel_pos_bias(q_len, k_len)
print("相对位置偏置的 shape:", bias.shape)
输出:相对位置偏置的 shape: torch.Size([50, 50])
7.2 T5
T5模型在处理相对位置编码时,采用了一种更简洁的方式来调整Attention机制。它通过给每个位置之间的相对位置加上一个偏置项(一个学习的参数),它与输入的每个token的相对位置相关,而不是依赖于绝对位置:
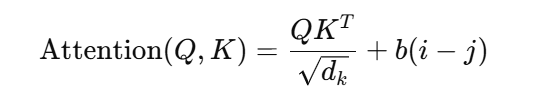
b(i - j) 是一个可学习的偏置项,表示词i和词j之间的相对位置。相比于Transformer-XL,T5的相对位置更加简洁,且能够直接学习相对位置的偏置。
代码实现:
class T5RelativePositionBias(nn.Module):
def __init__(self, max_len, num_heads):
super(T5RelativePositionBias, self).__init__()
# 位置偏置是一个可学习的张量
self.relative_position_bias = nn.Embedding(2 * max_len - 1, num_heads)
self.max_len = max_len
def forward(self, q_len, k_len):
# 计算每对 query 和 key 之间的相对偏置
positions = torch.arange(q_len).unsqueeze(1) - torch.arange(k_len).unsqueeze(0)
positions = positions + (self.max_len - 1) # 避免负索引
bias = self.relative_position_bias(positions)
return bias
# 假设 max_len=512, num_heads=8
max_len = 512
num_heads = 8
rel_pos_bias_t5 = T5RelativePositionBias(max_len, num_heads)
# 计算前 50 个位置的相对位置偏置
q_len = 50
k_len = 50
bias_t5 = rel_pos_bias_t5(q_len, k_len)
print("T5 相对位置偏置的 shape:", bias_t5.shape)
输出:T5 相对位置偏置的 shape: torch.Size([50, 50, 8])
7.3 DeBERTa(解耦的相对位置编码)
DeBERTa(Decoding-enhanced BERT with disentangled attention)模型提出了解耦位置和内容的相对位置编码方式,进一步提升了性能。
它将位置编码和内容编码分开计算。通过这种方式,模型能够分别学习每个token的内容信息以及它与其它token的相对位置关系。在DeBERTa中,相对位置偏置不仅仅与Query和Key之间的相对距离相关,还引入了内容解耦,也就是说,在Attention计算中,位置和内容分别通过不同的权重进行编码:
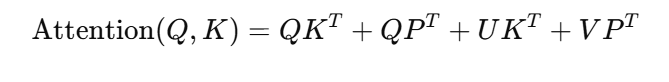
(是内容编码,表示Query和Key之间的相对位置)
代码实现:
class DeBERTaRelativePositionBias(nn.Module):
def __init__(self, max_len, d_model):
super(DeBERTaRelativePositionBias, self).__init__()
# 创建位置偏置矩阵
self.relative_position_embedding = nn.Embedding(2 * max_len - 1, d_model)
self.max_len = max_len
def forward(self, q_len, k_len):
# 计算 Query 和 Key 之间的相对位置
positions = torch.arange(q_len).unsqueeze(1) - torch.arange(k_len).unsqueeze(0)
positions = positions + (self.max_len - 1) # 避免负索引
bias = self.relative_position_embedding(positions)
return bias
# 假设 max_len=512, d_model=256
max_len = 512
d_model = 256
rel_pos_bias_deberta = DeBERTaRelativePositionBias(max_len, d_model)
# 计算前 50 个位置的相对位置偏置
q_len = 50
k_len = 50
bias_deberta = rel_pos_bias_deberta(q_len, k_len)
print("DeBERTa 相对位置偏置的 shape:", bias_deberta.shape)
输出:DeBERTa 相对位置偏置的 shape: torch.Size([50, 50, 256])
(还有别的实现方式,这里就不做过多介绍了,有兴趣的可以自行了解,比如Performer)
八、变种:Learnable Positional Encoding
Transformer也可以使用“可训练的”位置编码,它的每个位置都有一个可以学的向量,相比上面的方式,它更加的灵活,但缺点是不能推广到没出现过的长句子。
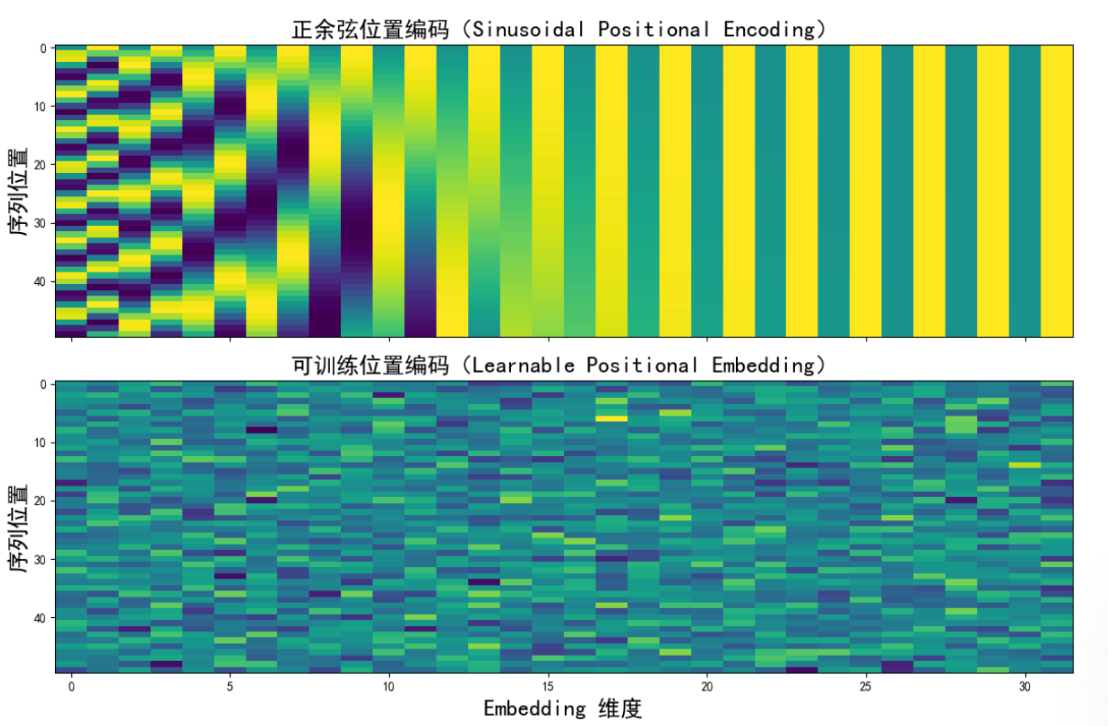
上面这张图展示了两种编码方式的对比,我们来逐一分析:
| PE | Learnable |
|---|---|
| 有明显的"波浪感"和周期性 | 随机初始化的颜色快,无明显规律 |
| 编码是固定的,不参与训练 | 编码是可学习的,随着训练不断调整 |
| 可以自然的推广到更长的序列 | 在训练长度范围内表达力强,但不容易泛化到没见过的长序列 |
| 高维部分频率更高,用于捕捉局部位置信息 | 更依赖训练数据的分布 |
还没结束,我们再来摘出某个位置的变量向量波形图:
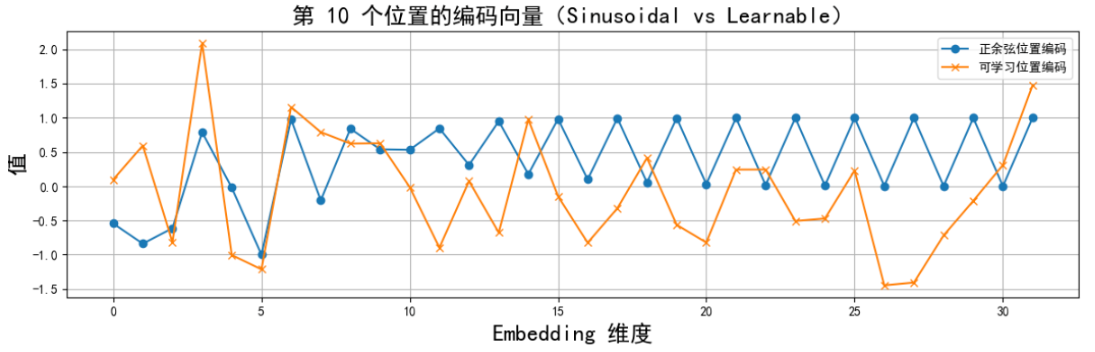
可以很直观的看到,正余弦编码的具有波浪感且比较平滑,反观Learnable编码,它的值更随机,有跳变,而且没有什么周期性。
九、结语
有关位置编码的内容到这里就结束了,希望这篇文章能够在您前进的道路上尽一份微薄之力,感谢!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 38
38 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)