用surprise库实现kaggle电影推荐(Baseline、SlopeOne、NormalPredictor)
使用python中的推荐系统库对kaggle中的电影数据集做打分,并根据评分做推荐
一、数据集
数据集:MovieLens
下载地址:https://www.kaggle.com/jneupane12/movielens/download
主要使用的文件:ratings.csv
格式:userId, movieId, rating, timestamp
记录了用户在某个时间对某个movieId的打分情况
我们需要补全评分矩阵,然后对指定用户,比如userID为1-5进行预测
二、surprise库简介
Surprise是python-scikit-learing中的一个推荐系统库
文档地址:https://surprise.readthedocs.io/en/stable/
Surprise中的常用算法:
- Baseline算法
- 基于邻域的协同过滤
- SlopeOne 协同过滤算法
- 矩阵分解算法:SVD,SVD++,PMF,NMF

三、用baseline算法实现电影推荐
概念
baseline算法是基于统计的基准预测线打分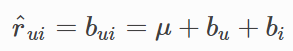
其中,
bui是预测值
bu是用户对整体的偏差
bi是上坪对整体的偏差
优化目标: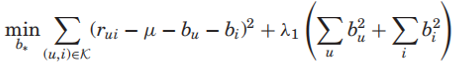
优化方法:
- SGD(梯度下降)
- ALS(交替最小二乘法)
实现代码
from surprise import Dataset
from surprise import Reader
from surprise import BaselineOnly
from surprise import accuracy
from surprise.model_selection import KFold
# 数据读取
reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1)
data = Dataset.load_from_file('./ratings.csv', reader=reader)
# ALS优化
bsl_options = {'method': 'als','n_epochs': 5,'reg_u': 12,'reg_i': 5}
# SGD优化
#bsl_options = {'method': 'sgd','n_epochs': 5}
algo = BaselineOnly(bsl_options=bsl_options)
#algo = BaselineOnly()
#algo = NormalPredictor()
# 定义K折交叉验证迭代器,K=3
kf = KFold(n_splits=3)
for trainset, testset in kf.split(data):
# 训练并预测
algo.fit(trainset)
predictions = algo.test(testset)
# 计算RMSE
accuracy.rmse(predictions, verbose=True)
uid = str(196)
iid = str(302)
# 输出uid对iid的预测结果
pred = algo.predict(uid, iid, r_ui=4, verbose=True)
四、用SlopeOne算法实现电影推荐
算法步骤:
- 计算Item之间的评分差的均值,记为评分偏差(两个item都评分过的用户)
- 根据Item间的评分偏差和用户的历史评分,预测用户对未评分的item的评分
- 将预测评分排序,取topN对应的item推荐给用户
例如: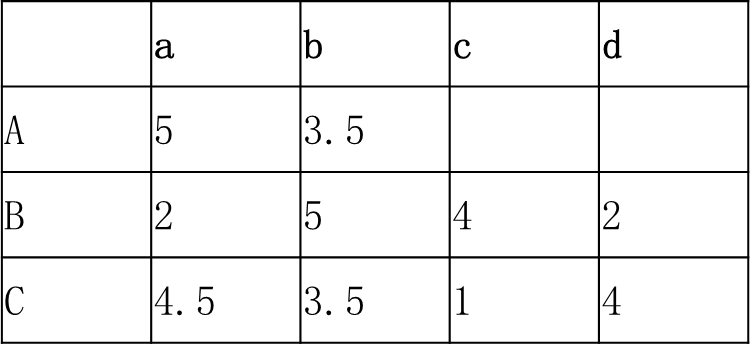
Step1,计算Item之间的评分差的均值:
b与a:((3.5-5)+(5-2)+(3.5-4.5))/3=0.5/3
c与a:((4-2)+(1-4.5))/2=-1.5/2
d与a:((2-2)+(4-4.5))/2=-0.5/2
c与b:((4-5)+(1-3.5))/2=-3.5/2
d与b:((2-5)+(4-3.5))/2=-2.5/2
d与c:((2-4)+(4-1))/2=1/2
Step2,预测用户A对商品c和d的评分
a对c评分=((-0.75+5)+(-1.75+3.5))/2=3
a对d评分=((-0.25+5)+(-1.25+3.5))/2=3.5
Step3,将预测评分排序,推荐给用户
推荐顺序为{d, c}
加权算法 Weighted Slope One
如果有100个用户对Item1和Item2都打过分, 有1000个用户对Item3和Item2也打过分,显然这两个rating差的权重是不一样的,因此计算方法为:
(100*(Rating 1 to 2) + 1000(Rating 3 to 2)) / (100 + 1000)
SlopeOne算法的特点:
- 适用于item更新不频繁,数量相对较稳定
- item数<<user数
- 算法简单,易于实现,执行效率高
- 依赖用户行为,存在冷启动问题和稀疏性问题
代码实现
from surprise import Dataset
from surprise import Reader
from surprise import SlopeOne
# 数据读取
reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1)
data = Dataset.load_from_file('./ratings.csv', reader=reader)
train_set = data.build_full_trainset()
# 使用SlopeOne算法
algo = SlopeOne()
algo.fit(train_set)
# 对指定用户和商品进行评分预测
uid = str(196)
iid = str(302)
pred = algo.predict(uid, iid, r_ui=4, verbose=True)
五、用NormalPredictor实现电影推荐
假设评分数据是来自一个正态分布的数据,根据训练集的分布特征随机给出一个预测值。
代码实现
from surprise import Dataset
from surprise import Reader
from surprise import NormalPredictor
from surprise import accuracy
from surprise.model_selection import KFold
# 数据读取
reader = Reader(line_format='user item rating timestamp', sep=',', skip_lines=1)
data = Dataset.load_from_file('./ratings.csv', reader=reader)
# NormalPredictor进行求解
algo = NormalPredictor()
# 定义K折交叉验证迭代器,K=3
kf = KFold(n_splits=3)
for trainset, testset in kf.split(data):
algo.fit(trainset)
predictions = algo.test(testset)
accuracy.rmse(predictions, verbose=True)
uid = str(196)
iid = str(302)
pred = algo.predict(uid, iid, r_ui=4, verbose=True)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)