物体检测--YOLOv5
文章详细介绍了YOLOv5的架构、训练过程及优化策略,并通过实验验证了其在不同场景下的检测性能。研究结果表明,YOLOv5在速度和准确性上具有显著优势,为实时物体检测提供了高效解决方案。
一、环境安装
1.1、anaconda安装 ,根据官方地址一步步安装,此略过。
https://www.anaconda.com/download
创建虚拟环境
conda create -n yolov5 python=3.8
配置国内源,加速下载 (可选)
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
1.2、pytorch安装
https://pytorch.org/index.html
https://pytorch.org/get-started/previous-versions/
# 选择V1.8.2版本下
# CUDA 10.2 (英伟达显卡1650/1600/..选择)
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu102
# CUDA 11.1 (英伟达显卡30以上选择)
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cu111
# CPU Only (电脑没有GPU选)
pip3 install torch==1.8.2 torchvision==0.9.2 torchaudio==0.8.2 --extra-index-url https://download.pytorch.org/whl/lts/1.8/cpu
1.3、yolov5下载
https://github.com/ultralytics/yolov5/tree/master
下载yolov5 v7.0版本
https://github.com/ultralytics/yolov5/releases/tag/v7.0 Assets下 Source code.zip压缩包
1.3.1 requirements.txt文件修改
修改yolov5模型内的requirements.txt文件,主要是
numpy==1.18.5修改 numpy==1.20.3
Pillow==7.1.2修改 Pillow==8.3.0
注释掉torch,torchvision,因为文件内的版本和实际pytorch下载对应的版本可能不同,且已经有下载
1.3.2 下载预训练模型
yolov5有yolov5n、yolov5s、yolov5m、yolov5l、yolov5x五种参数模型,模型对应的参数params依次增加。
在Assets下下载五种模型,放置到yolov5-7.0文件夹下。
1.3.3 模型测试
通过终端输入以下内容,检验模型检测效果。
python detect.py
二、模型检测
2.1、关键参数
weights:训练好的模型文件
yolov5n、yolov5s、yolov5m、yolov5l、yolov5x五种参数模型。
python detect.py --weights yolov5s.pt
python detect.py --weights yolov5x.pt
source:检测的目标,可以是单张图片、文件夹、屏幕或者摄像头等
python detect.py --weights yolov5s.pt --source 0 #摄像头
img.jpg #图片
vid.mp4 #视频
python detect.py --weights yolov5s.pt --source data/images/bus.jpg
python detect.py --weights yolov5s.pt --source screen #整个屏幕检测
conf :置信度阈值,表示预测框中包含物体的概率。越低框越多,越高框越少
python detect.py --weights yolov5s.pt --conf-thres 0.8
iou :iou阈值,越低框越少,越高框越多(1)评估预测框与真实框之间的匹配程度,越高预测越准确;(2)NMS执行非极大值抑制的关键参数,如果两个框的iou超过阈值,其中置信度较低的框就会被抑制。
三、数据集构建
3.1、标注工具
视频类数据集可以使用opencv进行视频抽帧
import cv2
import matplotlib.pyplot as plt
video = cv2.VideoCapture('./bat.mp4')
ret,frame=video.read()
plt.imshow(frame)
plt.imshow(cv2.cvtcolor(frame,cv2.COLOR_BGR2BGR)) #转换图片通道
num=0
save_step=30 #间隔帧
while True:
ret,frame=video.read()
if not ret:
break
num+=1
if num % save_step ==0:
cv2.imwrite('./images/'+str(num)+".jpg",frame)
labelimg
pip install labelimg
输入labelimg
(1) 打开文件夹Open Dir,确定文件存储位置Change Save Dir
(2) 点击PascalVOC使图片以YOLO格式存储
(3)点击图片目标,出现Create_RectBox进行标记
(4)图片标记label格式为txt,包括五条数据,第一个为类别,后四个为目标坐标
四、模型训练
4.1、数据处理
image:存放图片
train:训练集数据
val:验证集数据
label:存放标签
train:训练集标签,与训练集图片命名一一对应
val:验证集标签,与验证集图片命名一一对应
classes.txt不需要放文件内
4.2、关键参数
data:数据集描述文件
weights:预训练权重文件
data默认是选择coco128.yaml,此处复制coco128.yaml文件命名为bvn.yaml。主要根据自己路径修改里面path、train、val参数,其中classes根据实际目标检测对象类别进行修改
path: ../datasets/coco128 # dataset root dir
train: images/train2017 # train images (relative to 'path') 128 images
val: images/train2017 # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
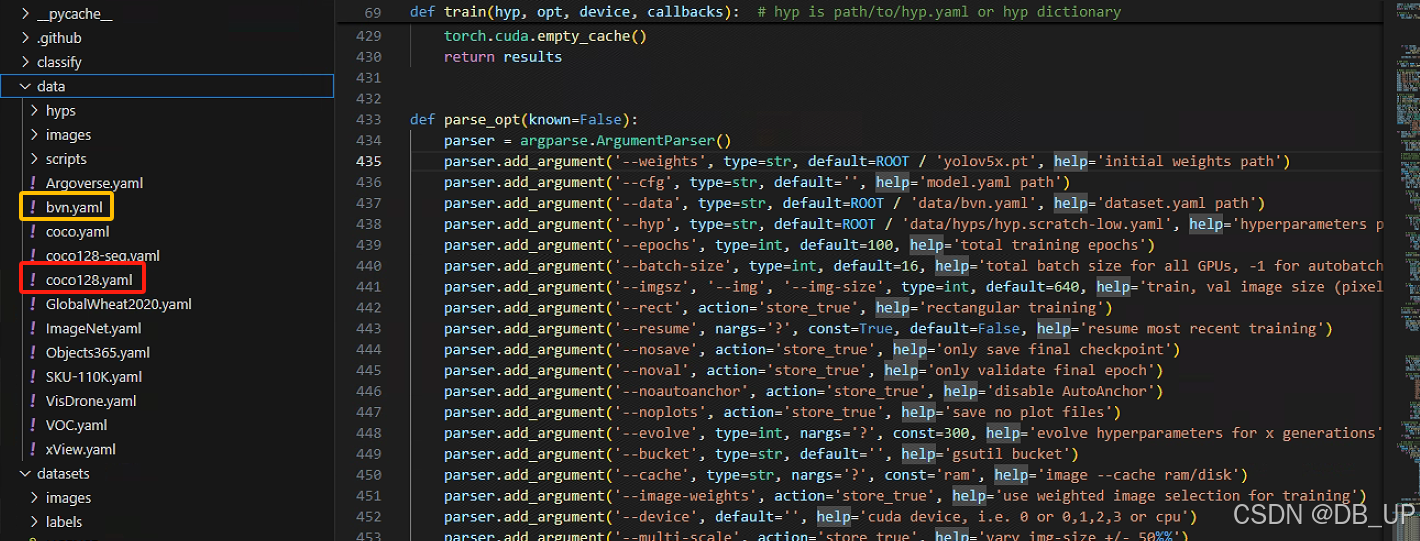
weights默认是选择yolov5s.pt模型,此处可以根据实际情况更改为yolov5n、yolov5m、yolov5l、yolov5x四种模型进行训练。
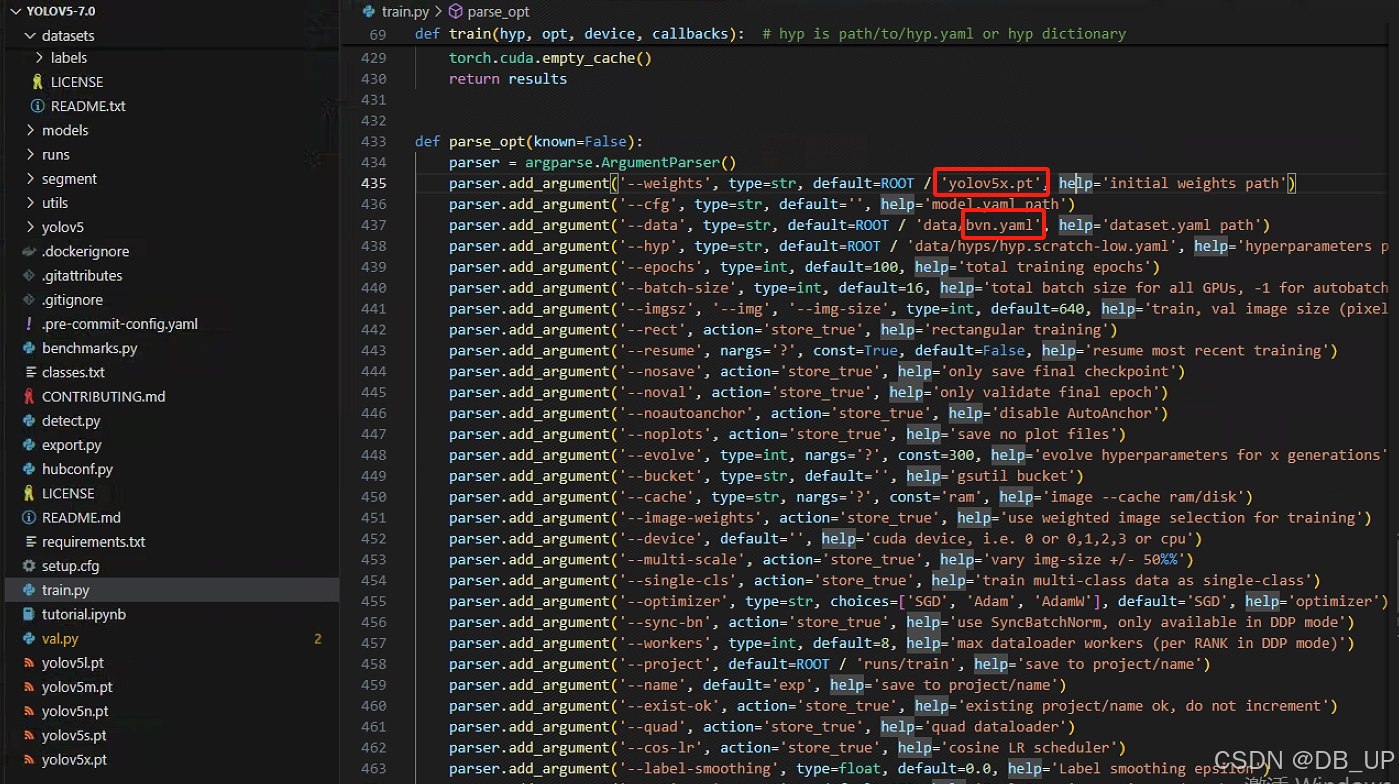
4.3、模型结果解读
模型训练结果会在run文件夹下的train文件的exp.中,文件内包含很多参数,其中weights中有训练最好的best.pt和最差的last.pt模型。
可以在终端通过tensorboard --logdir runs进行展示结果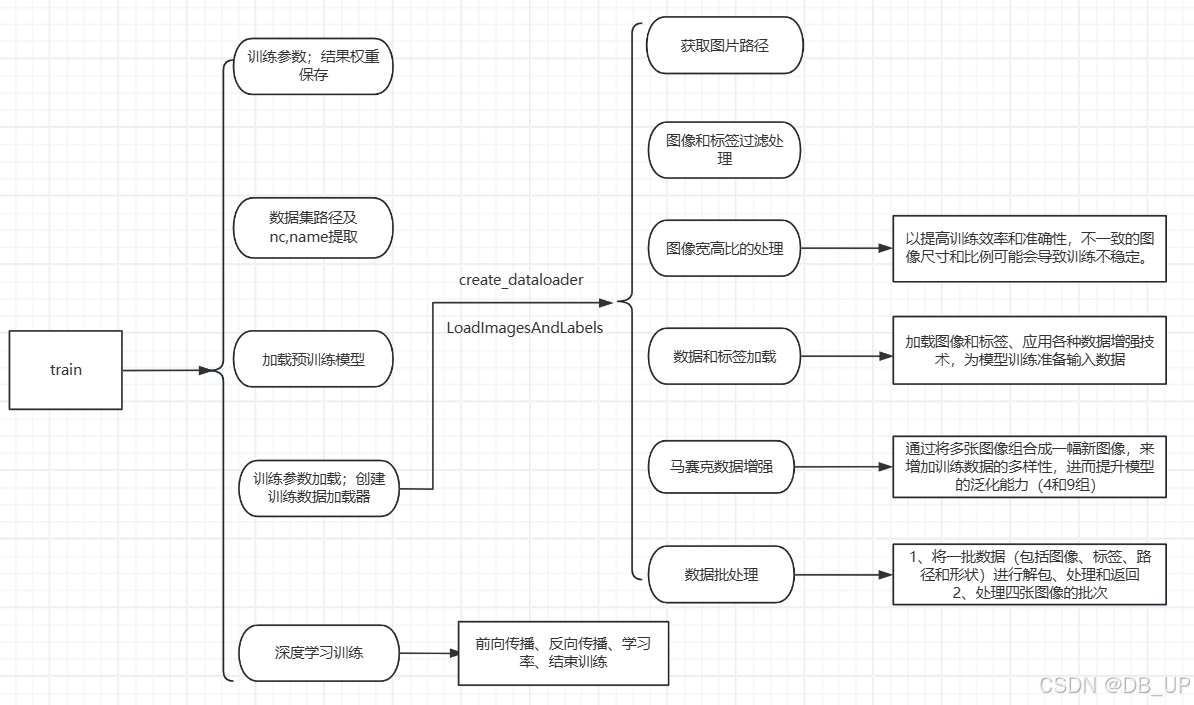
五、模型验证及新数据检测
根据预训练完的模型,得到weights中有训练最好的best.pt,通过终端输入以下参数进行模型验证
python val.py --weights runs/train/exp34/weights/best.pt
可以通过参数将图片/视频/…结果输出到桌面(–view-img)
python detect.py --weights runs/train/exp9/weights/best.pt --source datasets/images/test (--view-img可选参数)
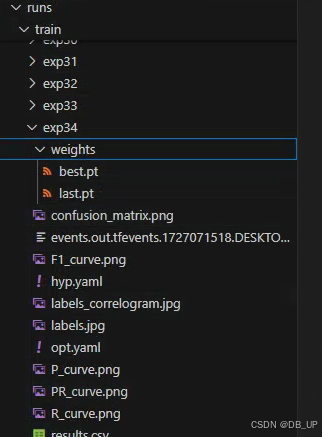
train中包含很多输出,其中包含训练的batch结果,验证集的val_batch0_pred.jpg结果。
六、模型的核心思路
6.1、输入图片处理
预处理:YOLOv5首先对输入图像进行预处理,调整图像大小到网络所需要的尺寸(比如 640x640),同时进行归一化等操作,使得输入图像格式统一、数据标准化。
数据增强:YOLOv5 支持多种数据增强方式,比如随机裁剪、翻转、色彩变换等,帮助模型增加泛化能力。
6.2、骨干网络提取特征
Backbone (骨干网络):YOLOv5 使用的骨干网络主要是 CSPNet(Cross Stage Partial Network),这个网络能够高效地提取图像的特征信息。骨干网络的作用是将原始图像转换为特征图,通过一系列卷积操作提取不同层次的特征。
多尺度特征提取:在物体检测中,不同的物体大小和尺度差异很大,因此 YOLOv5 通过多尺度特征融合(FPN + PAN 结构),在不同层次的特征图上同时进行物体检测,确保小物体和大物体都能够被识别。
6.3、特征图输出与检测头
检测头:YOLOv5 的检测头负责预测每个特征图上的物体类别、边界框(Bounding Box)的坐标以及置信度。检测头输出的是一个三维张量,张量的每一个位置都对应一个锚点(Anchor)。
Anchor机制:锚点是一个预定义的矩形框,表示物体可能出现的位置。YOLOv5 会根据图像中真实物体的形状和大小,调整这些锚点的尺寸和位置。
Bounding Box 预测:YOLOv5 使用的是相对中心点坐标(x, y),宽高(w, h)等参数来回归物体的位置。
类别预测:对于每个锚点,网络还会输出类别的预测分数,用于判断该锚点上检测到的物体属于哪个类别。
6.4、损失函数与目标
YOLOv5 的损失函数包括以下几个部分:
分类损失:用于计算检测到的物体分类结果和真实类别之间的误差。
定位损失(Bounding Box Loss):用于评估预测的边界框和真实物体位置的偏差。
置信度损失:用于评估检测到物体的置信度,与物体是否存在相关。
6.5、 非极大值抑制(NMS)
YOLOv5 会在预测结果中产生大量边界框,其中有很多是重复或非常相似的框。为了解决这个问题,YOLOv5 使用 非极大值抑制(NMS),去除那些重叠度高且置信度低的框,只保留最有可能的边界框。
6.6、输出结果
最终,经过多层次的特征提取和处理,YOLOv5 输出预测结果,其中包括:
物体类别:网络识别出的物体的类别。
边界框坐标:每个物体的边界框坐标。
置信度:检测结果的置信度分数。
YOLOv5 的物体检测思路是通过一个单阶段的网络,将图像通过一个卷积神经网络,在一个前向传递过程中同时预测物体的位置和类别。其特点是速度快、实时性高,适合处理大规模的图像数据检测任务。
七、常见问题
7.1、服务器GPU显存选择
公司碰到多人使用GPU,导致GPU显存不足现象,在train.py和val.py代码中添加检查可用GPU进行模型训练
# 检查所有可用的GPU显存
required_memory = 2e9
gpu_memory = [(i, torch.cuda.get_device_properties(i).total_memory - torch.cuda.memory_allocated(i)) for i in range(torch.cuda.device_count())]
gpu_memory = sorted(gpu_memory, key=lambda x: x[1], reverse=True) # 按可用显存排序
# 选择显存足够的GPU (例如选择可用显存最大的一个)
for gpu_id, available_memory in gpu_memory:
if available_memory > required_memory: # 设定所需的显存
print(f"Using GPU {gpu_id} with {available_memory / 1e9:.2f} GB available memory")
torch.cuda.set_device(gpu_id)
break
如果知道某个卡显存够使用,也可以通过–device 1(1表示卡1,可通过nvidia-smi查看卡显存情况) 使用
python val.py --weights runs/train/exp/weights/best.pt --data path/to/my_dataset.yaml --iou 0.65 --device 1
7.2、同时检测自己训练的数据集中的物体和预训练模型中的物体
合并数据集
自定义数据集:将你的数据集(包括标注信息)整理成YOLOv5支持的格式。
预训练数据集:确保你所使用的YOLOv5预训练模型所能检测的对象的标签在你的数据集中也有对应的标签。
创建一个新的标签文件,包含你自己数据集的类别以及YOLOv5预训练模型支持的类别。确保类别编号不重复。
python train.py --img 640 --batch-size 16 --epochs 50 --data custom_data.yaml --weights yolov5s.pt #参数可选及根据自己实际更换
python detect.py --weights runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source path/to/your/test/images
八、Gradio 创建本地查看链接
Gradio是一个开源的Python库,用于构建机器学习演示和web应用,其内置丰富的组件,并且实现了前后端的交互逻辑,无需额外编写代码。
步骤:打开终端—》激活环境—》pip install gradio
import torch
import gradio as gr
model=torch.hub.load('./','custom',path='runs/train/exp19/weights/best.pt',source='local') #custom自定义模型
title = '基于Gradio的物体检测'
desc = '可以检测图片内的目标对象'
def det_image(img,conf,iou):
model.conf=conf
model.iou=iou
return model(img).render()[0]
base_conf,base_iou=0.25,0.45
gr.Interface(inputs=['image',gr.Slider(minimum=0,maximum=1,value=base_conf),gr.Slider(minimum=0,maximum=1,value=base_iou)],
outputs=['image'],
fn=det_image,
title=title,
description=desc,
live=True,
examples=[['./datasets/images/train2017/1.jpg',0.4,base_iou],['./datasets/images/train2017/2.jpg',0.4,base_iou]]).launch(share=True)
九、目标检测常见6大类算法对比:
9.1、two_stage两阶段
简单理解算法分为两步:首先提取候选区域,然后对每个区域使用深度网络提取特征。
1、R-CNN
算法原理:使用Selective Search算法提取候选区域,然后对每个区域使用深度网络提取特征,最后用SVM分类器分类,训练一个线性回归模型来预测边缘框偏移。
缺点:训练和测试速度慢;需要大量存储空间用于保存中间特征图,不能满足实时检测的需求。
2、Fast R-CNN
算法原理:使用Selective Search算法提取候选区域,然后用深度网络提取特征,通过RoI Pooling层统一特征图大小,最后进行分类和边界框回归。相比R-CNN,速度有提升。
3、Faster R-CNN
算法原理:引入Region Proposal Network (RPN)代替Selective Search,实现端到端训练。特征提取、分类和边界框回归同时进行。速度和精度都有提升。
缺点:结构复杂度增加;相对于YOLO系列等单阶段检测器来说,速度稍慢。
4、Mask R-CNN
在Faster R-CNN的基础上增加了一个分支,用于生成目标的像素级掩码。可以进行实例分割,精度较高。
9.2、one_stage单阶段
简单理解:算法将目标检测视为一个回归问题,直接预测目标物体的位置和类别,从而实现了端到端的训练。这种方法的优点是速度快,可以满足实时检测的需求,同时准确率也较高。
1、单发多框检测(SSD)
SSD通过单神经网络来检测模型,以每个像素为中心的产生多个锚框,在多个段的输出上进行多尺度的检测。
2、Yolo系列
SSD中锚框大量重叠,因此浪费了很多计算,YOLO 将图片均匀分成 SxS个锚框,每个锚框预测 B个边缘框。
优点:极高的检测速度;良好的通用性;易于调整以适应不同的硬件平台。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)