DETR模型解读(附源码+论文)
DETR(DEtection TRansformer)是一种基于Transformer的目标检测模型,它抛弃了传统目标检测中的手工设计流程(如候选框生成和NMS),实现了端到端的检测框架。
代码链接:DETR-small-demo(建议看我的,模型框架部分代码注释的很详细,源码可以移步官网)
论文链接:https://ai.meta.com/research/publications/end-to-end-object-detection-with-transformers/
官方链接:detr
DETR给我的感觉是总体的模型结构比YOLO简单很多,代码量精简,逻辑清晰,但是训练它比YOLO难的不是一点半点。对了,学习DETR前最好先学一下VIT,这样理解起来会简单一点。
代码学习就行,跑的话真没必要了。官方给的数据8个V100要跑6天才跑完300epoch,就算是缩减版的也要跑3天。我自己没当真,想着跑个差不多的就行了,不追求精度,然后跑了4epoch花了12个小时。早上过来看训练效果,AP的所有指标全是0,分类错误率100%,两眼一黑。还有,官方给的加载数据的方法是强适配COCO的,用自己的数据集的话必须有和COCO一样的annotations。
官方给出的效果图,简直震惊。两只象的腿重叠这么厉害的情况下,注意力还能分清哪只是大象的腿(蓝色),哪只是小象的腿(黄色)。这模型未来可期

DETR的模型框架
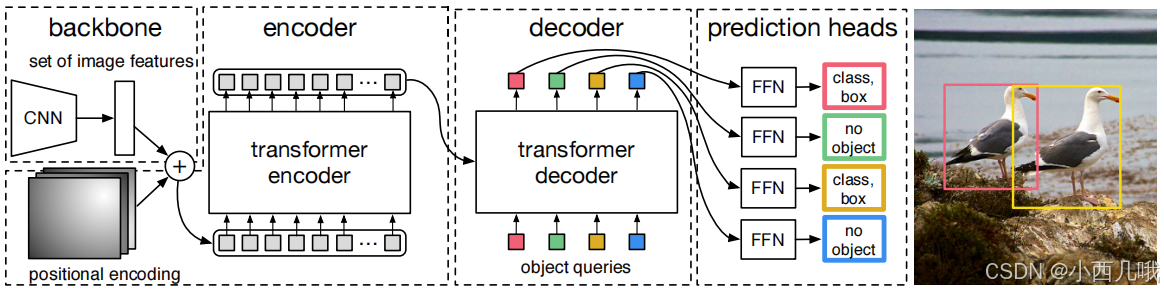
从下面这张图可以清晰的看到一张图片的颠沛流离。首先backbone使用ResNet进行特征提取;Encoder输入的是positional encoding(位置编码)和backbone提取的特征图。Decoder输入固定的query(例如一张特征图只生成100个锚框,即100个query。不同于YOLO,每个像素点生成3个锚框,还分大中小三种特征图,那生成的特征图多的简直…所以DETR追求的就是一个简化简化!),key和value的输入是Encoder提供的。
这里还有一点不同,在自然语言中应用tranformer的时候,如GPT是把句子后面的内容遮挡住,确保当前词只能看到它前面的词,模型以串行方式逐步生成后续内容。这种 顺序处理 的需求是因为文本的上下文是 时间相关的,词的顺序决定了语义。而这里的tranformer没有对输入图像的特征进行遮挡,而是直接将整个特征图输入进去。因为图像的像素或特征是 空间相关的,而非时间相关。
最后再接FFN(简单的说就是全连接层)进行预测。预测有两条支线,一条是预测分类,一条是是预测锚框xywh。这里就有人问了,你预测了100个锚框,但是你图片上只有两个目标,你剩余的98个锚框呢?这里用了匈牙利算法。简单的说就是,如果你图片上只有两个目标,那么我就找两个loss最小的锚框作为预测值(loss怎么算的下面细说),剩下的98个都是背景。这也是为什么COCO有80个分类,但是为什么代码里设置的是81,因为还有一个是背景。
demo
官方提供了一个小demo,可以看到短短50行就把模型框架写完了。
class DETRdemo(nn.Module):
"""
Demo DETR implementation.
Demo implementation of DETR in minimal number of lines, with the
following differences wrt DETR in the paper:
* learned positional encoding (instead of sine)
* positional encoding is passed at input (instead of attention)
* fc bbox predictor (instead of MLP)
The model achieves ~40 AP on COCO val5k and runs at ~28 FPS on Tesla V100.
Only batch size 1 supported.
"""
def __init__(self, num_classes, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# create ResNet-50 backbone
self.backbone = resnet50()
del self.backbone.fc # 删除了 ResNet 的全连接层 (fc),保留用于提取特征的卷积部分
# create conversion layer 将 ResNet 输出的 2048 维特征降维到 Transformer 使用的 256 维
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# create a default PyTorch transformer
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
# prediction heads, one extra class for predicting non-empty slots
# note that in baseline DETR linear_bbox layer is 3-layer MLP
self.linear_class = nn.Linear(hidden_dim, num_classes + 1) # 预测目标的类别(包括一个额外的“背景”类)
self.linear_bbox = nn.Linear(hidden_dim, 4) # 预测边界框的xywh(归一化到 [0, 1])
# output positional encodings (object queries)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # 预测100个框
# spatial positional encodings
# note that in baseline DETR we use sine positional encodings
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2)) # 行列位置编码
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
# propagate inputs through ResNet-50 up to avg-pool layer
x = self.backbone.conv1(inputs) # 将输入图像通过 ResNet-50 提取特征,逐层提取多尺度特征
x = self.backbone.bn1(x)
x = self.backbone.relu(x)
x = self.backbone.maxpool(x)
x = self.backbone.layer1(x)
x = self.backbone.layer2(x)
x = self.backbone.layer3(x)
x = self.backbone.layer4(x)
# convert from 2048 to 256 feature planes for the transformer
h = self.conv(x) # [B, 2048, H, W] -> [B, 256, H, W]
# construct positional encodings
H, W = h.shape[-2:]
pos = torch.cat([ # 位置编码 [H*W, 1, 256]
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# propagate through the transformer
h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1), # 加了位置编码的特征图
self.query_pos.unsqueeze(1)).transpose(0, 1) # [100, B, 256]
# finally project transformer outputs to class labels and bounding boxes
return {'pred_logits': self.linear_class(h), # 类别预测
'pred_boxes': self.linear_bbox(h).sigmoid()} # 边界框预测,通过 Sigmoid 归一化到 [0, 1]
得益于 Transformer 的表示能力,DETR 架构非常简单,比YOLO简单太多了。主要由两个组件:
- ResNet:使用
ResNet提取图片特征。 - Transformer:通过全局关系增强特征。
看看我用这个demo实现的一个效果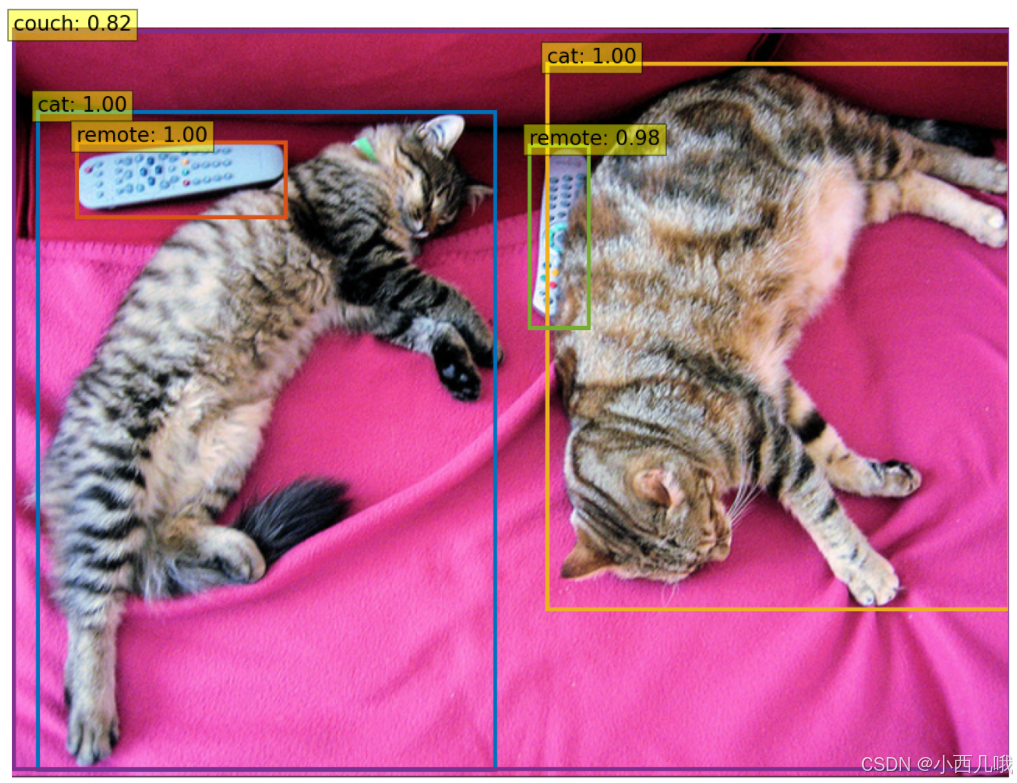
模型解读
好,现在开始深入解读,折磨开始!
backbone
前面什么RestNet部分就不说了,直接调用模型就行
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
xs = self[0](tensor_list) # 这里就是个ResNet self[0]: backbone self[1]: position_embedding
out: List[NestedTensor] = []
pos = []
for name, x in xs.items(): # 先通过ResNet提取特征图,再为特征图添加位置编码
out.append(x)
# position encoding
pos.append(self[1](x).to(x.tensors.dtype)) # 位置编码
return out, pos # 特征图 与特征图对应的位置编码
bockbone的输出就是先通过ResNet提取特征图,再为特征图添加位置编码
positional encoding (位置编码)
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors # (bs, n_c, w, h) (批次, 特征通道数, 宽, 高)
mask = tensor_list.mask # (bs, w, h) True表示padding的部分
assert mask is not None
not_mask = ~mask # 取反 True表示有效区域
y_embed = not_mask.cumsum(1, dtype=torch.float32) # 按行累加 每个特征获得列坐标位置编码
x_embed = not_mask.cumsum(2, dtype=torch.float32) # 按列累加 每个特征获得行坐标位置编码
if self.normalize: # 归一化
eps = 1e-6 # eg: not_mask = [[True, True, False],[True, False, False]] -> y_embed = [[1, 2, 0],[1, 0, 0]]
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale # 取最后一个值肯定就是最大值
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale # 2π 方便后面位置编码的正余弦操作
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats) # 分别对奇偶位置编码
pos_x = x_embed[:, :, :, None] / dim_t # (b, w, h, num_pos_feats)
pos_y = y_embed[:, :, :, None] / dim_t
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
return pos
mask补充说明一下,就是一张图输入的时候会reszie为统一大小,如果图片不够大的地方会用padding填充,所以mask就是将输入图片中,本来就是图片的地方为Flase,而填充的地方为True,即区分图片的有效部分和无效部分,无效部分不参与计算。
代码逻辑
- 从
mask生成有效区域的行列位置累积值,累积的最大值用于归一化。 - 归一化这些位置值,用于位置编码。
- 计算特征图每个像素点的正弦和余弦编码。
- 将 x 和 y 的编码拼接成最终的二维位置编码。
至于位置编码为什么这样,详细要看论文,这个一言两语解释不清,我只从代码的角度解释
Transformer Encoder(编码器)
def forward_post(self, src, src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos) # q, k = 特征图 + 位置信息 v不需要位置信息
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, # 不需要遮盖后面的数据
key_padding_mask=src_key_padding_mask)[0] # 不计算padding的数据 True值的就是需要mask的数据
src = src + self.dropout1(src2) # 原始输入 残差连接 注意力
src = self.norm1(src) # 归一化
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
q = k = self.with_pos_embed(src, pos):将特征图 src 和位置编码 pos 合并,得到位置编码后的查询(q)和键(k)。在 Transformer 中,查询和键通常是相同的,因为它们是从同一源特征图中计算得到的。
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask, key_padding_mask=src_key_padding_mask)[0]:使用查询(q)、键(k)和值(value)来计算注意力得分并生成输出。这里的查询和键都是来自位置编码过的特征图 src。attn_mask 是告诉Encoder不要遮掩图片。key_padding_mask 是指示哪些位置是 padding 数据的遮蔽。
后面不说了,就是一些残差连接、规范化(与处理图片常用的BN不一样哦)、全连接、激活、Dropout,都是些常规的网络。
Transformer Decoder (解码器)
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos) # q, k的初始化时仅有100个预测框的位置编码
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), # q是Decoder提供的
key=self.with_pos_embed(memory, pos), # k, v是Encoder提供的
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
和编码器中很多相似的地方我就不解释了。这里解码器中主要用了自注意力和交叉注意力,其中自注意力里的q、k、v是自身的,而交叉注意力里的k、v是编码器中的。
- 自注意力机制:通过目标序列自身的自注意力计算更新目标表示。
- 交叉注意力机制:通过编码器的输出更新目标表示,使解码器能够利用编码器的上下文信息。
loss计算
这里的loss计算了三类损失,分别是labels、boxes、cardinality,然后以加权的方式计算总loss。还有,DETR在计算loss时,不仅计算了最后一层的,前面几层的输出也会计算损失。
在计算loss前得找到预测的100锚框里,哪个拿来跟我的真实框进行计算呢?
def forward(self, outputs, targets):
"""
目标匹配 根据 分类结果 和 框位置 的相似度来匹配预测框和真实框
:param outputs: This is a dict that contains at least these entries:
"pred_logits": 预测分类结果 [batch_size, num_queries, num_classes]
"pred_boxes": 预测框坐标的 [batch_size, num_queries, 4]
:param targets: This is a list of targets (len(targets) = batch_size), where each target is a dict containing:\
"labels": 目标类别标签 [num_target_boxes] num_target_boxes 图中真实目标数量
"boxes": 目标框坐标 [num_target_boxes, 4]
:return: A list of size batch_size, containing tuples of (index_i, index_j) where:
- index_i 预测的索引
- index_j 真实的索引
len(index_i) = len(index_j) = min(num_queries, num_target_boxes) 不会超过 100个
"""
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes 将每个目标的类别标签和框坐标拼接在一起,形成整体的标签和框
tgt_ids = torch.cat([v["labels"] for v in targets]) # 标签里的类别
tgt_bbox = torch.cat([v["boxes"] for v in targets]) # 标签里的锚框
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1) # 计算预测框和真实框之间的 L1距离(曼哈顿距离)
# Compute the giou cost betwen boxes 计算框的重叠程度 GIOU
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
# Final cost matrix 分类损失、L1损失、GIoU损失按权重合并
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets] # 每个图片中的目标框的数量
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))] # 匈牙利算法
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
最后输出的indices包含了预测框和真实框索引。
假设的场景
- 真实框(targets)有 4 个目标:
[目标A, 目标B, 目标C, 目标D],它们的索引分别为[0, 1, 2, 3]。 - 模型预测了 100 个框(
queries),其中只有一部分是有效预测框,其余是无关框(背景)。 - 我们希望找到 与真实框匹配的预测框,从而为每个真实目标分配一个最佳预测框。
于是我们计算代价矩阵C
- 分类代价(预测框的类别分布与真实类别之间的差异)。
L1框位置代价(预测框和真实框的坐标差异)。GIoU框位置代价(两者的重叠程度)。
然后使用匈牙利算法找到最优匹配
- 预测框索引:
[5, 12, 47, 88](代表 100 个预测框中,与真实框最匹配的框索引)。 - 真实框索引:
[0, 1, 2, 3](代表 4 个真实目标的索引)。
那么最终indices的值为
indices = [(torch.tensor([5, 12, 47, 88]), torch.tensor([0, 1, 2, 3]))]
分类损失
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (NLL)
targets dicts must contain the key "labels" containing a tensor of dim [nb_target_boxes]
"""
assert 'pred_logits' in outputs
src_logits = outputs['pred_logits']
idx = self._get_src_permutation_idx(indices)
target_classes_o = torch.cat([t["labels"][J] for t, (_, J) in zip(targets, indices)]) # 从 targets 中提取匹配的真实类别
target_classes = torch.full(src_logits.shape[:2], self.num_classes,
dtype=torch.int64, device=src_logits.device)
target_classes[idx] = target_classes_o # 将匹配的预测框的类别设置为对应的真实类别
# 对每个有效的预测框位置(对应真实目标框的预测框)计算交叉熵损失,然后取平均
loss_ce = F.cross_entropy(src_logits.transpose(1, 2), target_classes, self.empty_weight)
losses = {'loss_ce': loss_ce}
if log:
# TODO this should probably be a separate loss, not hacked in this one here
losses['class_error'] = 100 - accuracy(src_logits[idx], target_classes_o)[0]
return losses
假设场景
indices = [
(tensor([46, 97]), tensor([0, 1])), # 第一张图片的匹配
(tensor([25, 28, 39, 80]), tensor([1, 0, 3, 2])) # 第二张图片的匹配
]
那么idx=(tensor([0, 0, 1, 1, 1, 1]), tensor([46, 97, 25, 28, 39, 80]))
- 批次号 0 的预测框索引是
[46, 97]。 - 批次号 1 的预测框索引是
[25, 28, 39, 80]。
然后我们得到真实的图像类别为target_classes_o=tensor([82, 79, 1, 1, 1, 34])
构造一个 target_classes,并将预测框位置填充对应的目标类别。
- 第一张图片:
46位置设为82,97位置设为79。
- 第二张图片:
25位置设为1,28位置设为1,39位置设为1,80位置设为34。
tensor([[91, 91, ..., 82, ..., 79, ..., 91], # 第一张图片
[91, 91, ..., 1, ..., 1, ..., 1, ..., 34, ..., 91]]) # 第二张图片
计算交叉熵损失
loss_ce = F.cross_entropy(
src_logits.transpose(1, 2), # 模型的输出概率分布
target_classes, # 目标类别,形状 [batch_size, num_queries]
weight=self.empty_weight # 类别权重(可选)
)
- 第一张图片:
46的预测概率为[..., 0.1, 0.8, 0.1, ...],真实类别为82。97的预测概率为[..., 0.2, 0.7, 0.1, ...],真实类别为79。
- 第二张图片:
25的预测概率为[..., 0.05, 0.9, 0.05, ...],真实类别为1。28的预测概率为[..., 0.2, 0.75, 0.05, ...],真实类别为1。39的预测概率为[..., 0.15, 0.7, 0.15, ...],真实类别为1。80的预测概率为[..., 0.1, 0.5, 0.4, ...],真实类别为34。
L o s s = − 1 / 6 ∗ ( l o g ( 0.8 ) + l o g ( 0.7 ) + l o g ( 0.9 ) + l o g ( 0.75 ) + l o g ( 0.7 ) + l o g ( 0.4 ) ) Loss=-1/6*(log(0.8)+log(0.7)+log(0.9)+log(0.75)+log(0.7)+log(0.4)) Loss=−1/6∗(log(0.8)+log(0.7)+log(0.9)+log(0.75)+log(0.7)+log(0.4))
这段代码,交叉熵损失在每张图片的有效预测框位置(idx)上计算模型的预测概率与目标类别之间的差异。填充类别(91)的损失被自动忽略
锚框损失
def loss_boxes(self, outputs, targets, indices, num_boxes):
"""Compute the losses related to the bounding boxes, the L1 regression loss and the GIoU loss
targets dicts must contain the key "boxes" containing a tensor of dim [nb_target_boxes, 4]
The target boxes are expected in format (center_x, center_y, w, h), normalized by the image size.
"""
assert 'pred_boxes' in outputs
idx = self._get_src_permutation_idx(indices)
src_boxes = outputs['pred_boxes'][idx] # 预测的锚框xywh
target_boxes = torch.cat([t['boxes'][i] for t, (_, i) in zip(targets, indices)], dim=0) # 真实锚框的xywh
loss_bbox = F.l1_loss(src_boxes, target_boxes, reduction='none') # 预测框和目标框在 xywh 坐标上的绝对误差
losses = {}
losses['loss_bbox'] = loss_bbox.sum() / num_boxes # 对误差求和,并除以目标框数量
loss_giou = 1 - torch.diag(box_ops.generalized_box_iou( # GIoU损失
box_ops.box_cxcywh_to_xyxy(src_boxes), # GIoU 值范围为 [−1,1],值越大表示预测框越接近目标框
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses
假设场景
- 预测框
src_boxes=[[0.5,0.5,0.2,0.2],[0.7,0.7,0.3,0.3]] - 目标框
target_boxes=[[0.5,0.5,0.2,0.2],[0.8,0.8,0.2,0.2]] - 预测框与目标框的
GIoU = [1, 0.7]
L o s s L 1 = ( 0 + 0.1 + 0.1 + 0.1 + 0.1 ) / 2 = 0.2 LossL1=(0+0.1+0.1+0.1+0.1)/2=0.2 LossL1=(0+0.1+0.1+0.1+0.1)/2=0.2 L o s s G I o U = ( ( 1 − 1 ) + ( 1 − 0.7 ) ) / 2 = 0.5 LossGIoU=((1-1)+(1-0.7))/2=0.5 LossGIoU=((1−1)+(1−0.7))/2=0.5
这段代码计算了 L1回归损失 和 GIoU损失,分别从 位置偏差 和 重叠程度 两方面衡量预测框的质量。
预测框数量损失
def loss_cardinality(self, outputs, targets, indices, num_boxes):
""" Compute the cardinality error, ie the absolute error in the number of predicted non-empty boxes
This is not really a loss, it is intended for logging purposes only. It doesn't propagate gradients
"""
pred_logits = outputs['pred_logits']
device = pred_logits.device
tgt_lengths = torch.as_tensor([len(v["labels"]) for v in targets], device=device) # 真实目标框数量
# Count the number of predictions that are NOT "no-object" (which is the last class)
card_pred = (pred_logits.argmax(-1) != pred_logits.shape[-1] - 1).sum(1) # 得到每张图像的预测非空框数量
card_err = F.l1_loss(card_pred.float(), tgt_lengths.float()) # 预测数量和真实数量之间的误差
losses = {'cardinality_error': card_err}
return losses
这段代码的作用是计算预测框数量和真实框数量的平均绝对误差,帮助分析模型是否正确预测了非空目标框的数量。
写的我好累啊,差不多就这些了,具体代码看我的链接
代码链接:DETR-small-demo

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 38
38 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)