xPatch:具有指数季节性趋势分解的双流时间序列预测
原文地址:https://dp-ai-application.oss-cn-zhangjiakou.aliyuncs.com/arxiv/pdf/2412.17323v1.pdf
发表会议:AAAI2025
作者:Artyom Stitsyuk、Jaesik Cho
团队:韩国科学技术高等研究院(KAIST)
摘要
研究动机:提出transformer由于其注意机制,在充分利用时间序列数据中的时间关系方面遇到了挑战。
贡献:设计了指数补丁(简称 xPatch),这是一种利用指数分解的新型双流架构。受经典指数平滑方法的启发,xPatch 引入了创新的季节趋势指数分解模块。此外,提出了一种由基于 MLP 的线性流和基于 CNN 的非线性流组成的双流架构。该模型研究了在非 Transformer 模型中使用补丁和通道独立性技术的好处。最后,开发了一个稳健的反正切损失函数和一个 S 型学习率调整方案,以防止过拟合并提高预测性能。
非transformer模型采用patch和通道独立有何优势?
局部特征捕捉:
- Patch技术允许模型将输入的时间序列数据分割成较小的片段(patches),从而更好地捕捉局部特征和短期依赖关系。这种方法可以提高模型对不同时间段内模式变化的敏感度。
减少计算复杂度:
- 通过将时间序列数据划分为多个patch,模型可以在每个patch上独立进行处理,减少了全局计算的复杂度。这对于长序列尤其重要,因为直接处理整个序列可能导致计算资源的过度消耗。
增强模型灵活性:
- 通道独立性意味着不同的特征通道可以被独立处理,这使得模型能够更灵活地应对多变量时间序列数据。例如,在处理具有多个传感器输入的时间序列时,每个传感器的数据可以通过独立的通道进行处理,从而更好地保留各自的信息。
避免注意力机制的局限性:
- Transformer模型依赖于自注意力机制,虽然在捕捉长距离依赖方面表现出色,但在处理局部特征和短距离依赖时可能不如CNN或MLP有效。通过引入patch技术和通道独立性,xPatch能够在不依赖自注意力机制的情况下更好地捕捉时间序列中的复杂模式。
防止过拟合:
- Patch技术和通道独立性有助于模型更好地泛化,尤其是在训练数据有限的情况下。通过减少模型参数之间的耦合,这些技术可以降低过拟合的风险,提高模型的鲁棒性和泛化能力。
结合线性和非线性流:
- xPatch采用了基于MLP的线性流和基于CNN的非线性流的双流架构。这种组合不仅能够捕捉时间序列中的线性关系,还能处理复杂的非线性模式。通过这种方式,模型可以在不同层次上提取特征,进一步提升预测性能。
综上所述,非Transformer模型采用patch和通道独立技术能够在保持计算效率的同时,增强模型的表达能力和泛化能力,从而在时间序列预测任务中取得更好的效果。
相关的工作
自注意力机制的排列不变性
排列不变性(Permutation-Invariance)是指模型的输出结果不因输入元素的顺序变化而改变的特性。例如,如果输入是一个集合(如一组数字或单词),无论这些元素的排列顺序如何,模型都会产生相同的输出结果。
Method
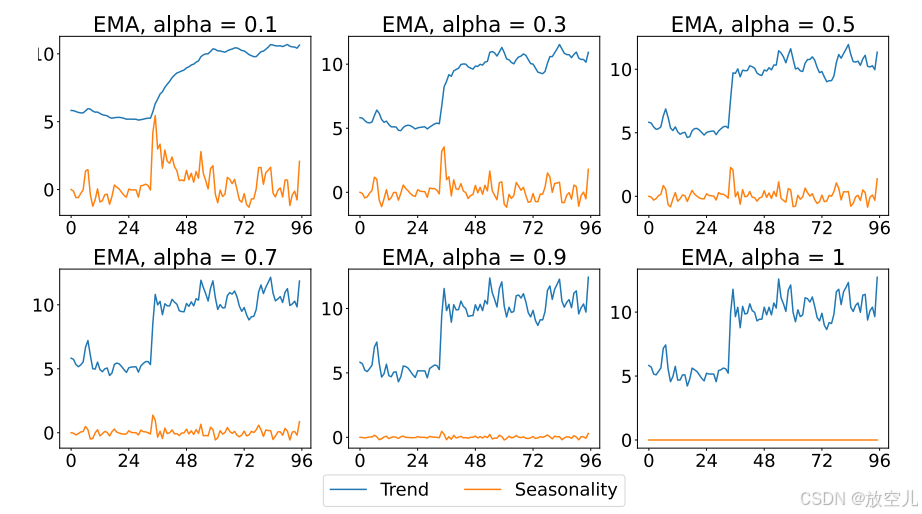
指数移动平均是(EMA):一种指数平滑方法,它对较新的数据点赋予更大的权重,同时平滑掉较旧的数据。这种指数加权方案使得EMA能够更迅速地响应时间序列潜在趋势的变化,而无需填充重复值。
从时间 t = 0 开始的数据 的EMA点
由以下公式表示:
其中, 是平滑因子,且
。EMA(·) 表示指数移动平均,而
和
分别对应趋势和季节性成分。下图展示了EMA分解的一个示例。
对比SMA
在ETTh1数据集的96长度样本上使用内核k = 25进行SMA分解的示例。
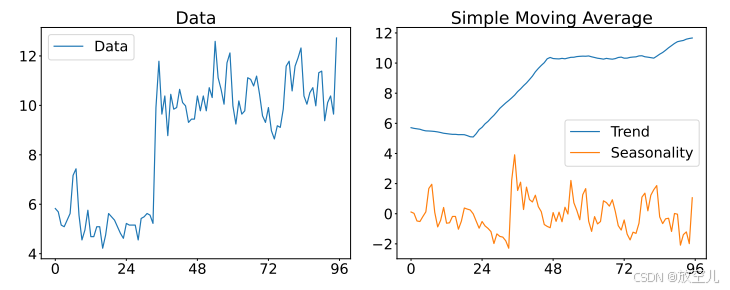
科普:这里SMA在趋势项采用了平均池化而作者的EMA没用平均池化,为什么?
- 灵活性:EMA可以根据数据的变化动态调整权重,而平均池化则依赖于预设的窗口大小,缺乏灵活性。
- 特征保留:EMA能够更好地保留时间序列中的局部特征和瞬时变化,而平均池化可能会因为信息压缩而导致特征丢失。
- 响应速度:EMA对新数据点的响应更快,能够及时捕捉到最新的变化趋势,而平均池化由于其聚合性质,响应速度相对较慢。
双流结构
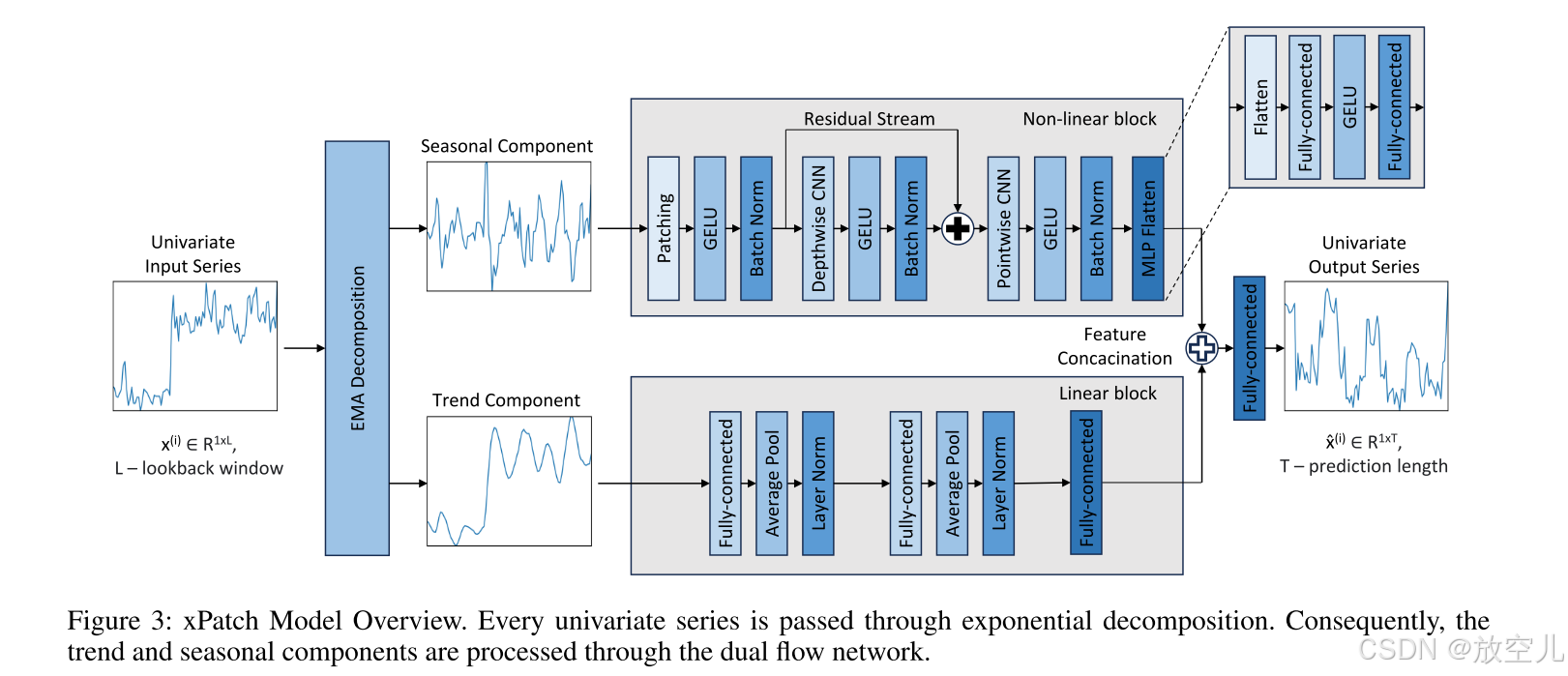
线性趋势流:基于MLP,适配趋势的非平稳性(长期变化、均值波动) 非线性季节流:基于CNN,捕捉季节性的平稳周期波动(均值/方差稳定) 架构优势:通过分离建模增强模型适应性,兼容非常规数据(如平稳趋势场景)
线性流
降维压缩:全连接层与池化逐步减少特征维度,通过瓶颈结构筛选关键信息
特征平滑:平均池化降低噪声,增强趋势稳定性
训练优化:层归一化加速收敛,避免梯度异常
非线性流
为什么采用 GELU 作为激活函数?
由于季节性变化有许多零值,采用 GELU 作为激活函数,可以实现围绕零的平滑过渡和非线性。
这里,N代表patch数量、P是patch长度、看代表卷积核、s代表步长
损失函数
反正切函数的特性
- 初始陡峭曲线:反正切函数在初始阶段表现出更陡峭的曲线,这意味着在预测的早期阶段,损失函数对误差的惩罚更严格。
- 整体较慢的衰减率:与指数函数相比,反正切函数的整体衰减率更慢,这意味着在远期预测点,损失函数仍然保持较高的权重,从而确保模型对远期预测的重视。
损失函数通过调整缩放系数 ρ(i) 来控制远期预测点的损失贡献,从而提高模型的性能。新的 arctangent 损失函数具有更慢的增长率,适用于需要更精细控制的任务。
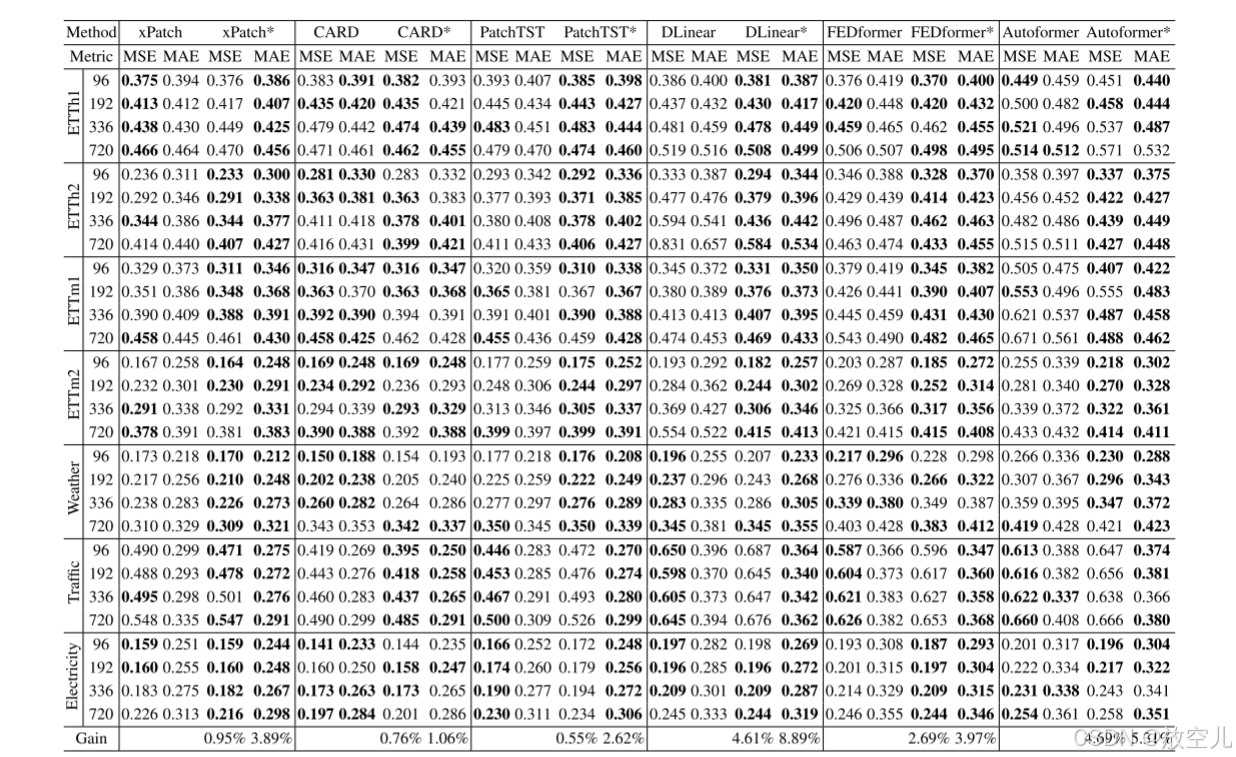
反正切损失训练的模型之间的预测误差比较。带 * 的模型名称表示使用反正切损失训练的模型。
学习率调整
新引入的S型学习率调整方案:引入了一种新的S型学习率调整方案。学习率 αt 在第 t 个周期的计算公式为:
其中,α0 是初始学习率,k 是逻辑增长率,s 是曲线平滑率,w 是热身系数。
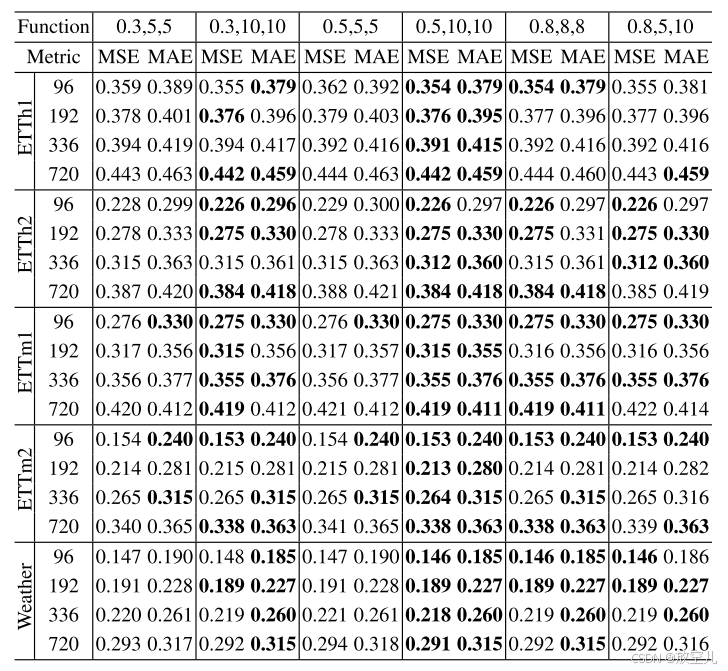
S型学习率调整方案通过逻辑函数实现非线性热身,并通过调整指数部分实现学习率的缓慢下降,从而优化模型的训练过程,提高长时间序列预测的性能。使用不同S形学习率超参数(k、s、w)训练的xPatch版本之间的预测误差比较。
总结
根本矛盾:传统Transformer因自注意力的计算缺陷与归纳偏置缺失,难以利用长历史窗口。
解决路径:分段机制通过“分治策略”显式引入局部性先验,使模型更高效捕捉长程依赖。
设计启示:时序模型需结合局部性约束与层级抽象,而非依赖纯全局注意力。
代码讲解
代码部分,为了大家更好的阅读和探讨我在飞书进行上传,有问题大家可以在疑问区域直接评论和且代码部分每个公式我也做了详细数学介绍,绝对通俗易懂!
代码位置:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 29
29 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)