Transformer之编码器encoding详解
1.输入部分2.注意力机制3.前馈神经网络编码器分解图。
在transformer中,一个单独的编码器由三大部分组成:
1.输入部分
2.注意力机制
3.前馈神经网络
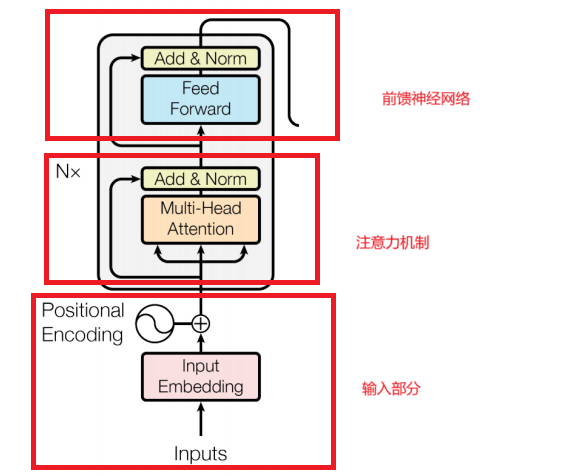
编码器分解图
第一部分-输入部分
Transformer 编码器的输入部分主要包括以下几个关键组成部分:
1.词嵌入(Word Embedding):
将输入的单词或者符号转换成向量空间中的向量表示。例如,对于一个包含"苹果""香蕉""橘子"等词汇的文本,词嵌入曾会将每个词汇映射为一个固定长度的向量,使得语义相近的词汇在向量空间中的距离也较近。
2.位置编码(Position Embedding):
由于Transformer模型基于自注意力机制,它在处理输入序列时,对每个位置的处理是并行的,不像循环神经网络(RNN)能够捕捉序列中的时序信息,Transformer的并行化在处理时提高了速度,但忽略了单词之间的先后顺序关系,位置编码就是告诉模型,哪些单词在前,哪些单词在后。
位置编码公式如下:
对于偶数位置(i=2k):
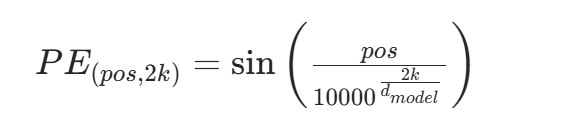
对于奇数位置(i=2k+1):
其中 :
- pos代表词在序列中的位置,取值范围是 0到L-1,L是序列的长度。
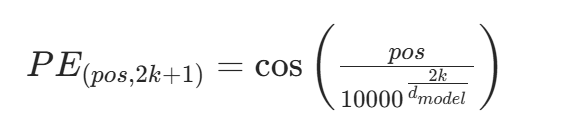
- i 是位置编码向量中的维度索引
- k是辅助变量,
(当i为偶数)或
(当i为奇数)。
公式解释
1.周期性特征:
正弦和余弦函数具有周期性,这意味着位置编码在不同的维度上会呈现出不同的周期变化。不同的周期可以帮助模型捕捉到序列中不同尺度的位置关系。例如,在某些维度上,周期可能较长,适合捕捉长距离的位置依赖;而在另一些维度上,周期可能较短,用于捕捉短距离的位置关系。
2.相对位置关系:
位置编码的设计使得两个位置之间的相对位置关系可以通过位置编码向量的线性组合来表示,也就是说,对于任意两个位置,它们的位置编码向量之间的关系可以反映出它们在序列中的相对距离。对于模型理解序列中元素之间的相对顺序非常重要。
3.尺度变化:
分母中的起到了尺度变化的作用。随着维度i的增加,这个值会逐渐变大,导致正弦和余弦的周期变长。这样可以确保在不同的维度上,位置编码能够覆盖不同的尺度范围,从而为模型提供丰富的位置信息。
公式原理推导
这组公式是基于三角函数的和角公式推导而来的。已知三角函数的和角公式:
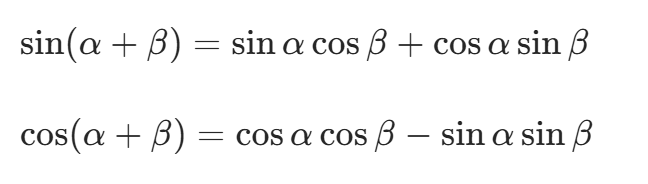
令![]() ,
,![]() ,这里的k表示位置偏移量。
,这里的k表示位置偏移量。
代入可得:

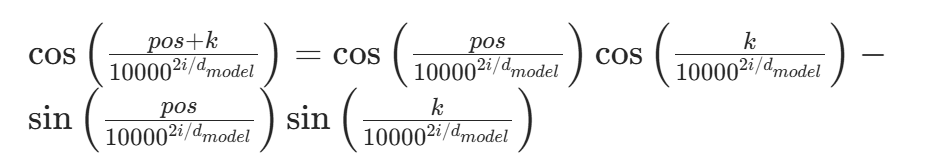
以下是一个简单的 Python 代码示例,用于计算正弦位置编码:
import torch
import numpy as np
def get_sinusoidal_positional_encoding(max_len, d_model):
position = np.arange(max_len)[:, np.newaxis]
div_term = np.exp(np.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
pe = np.zeros((max_len, d_model))
pe[:, 0::2] = np.sin(position * div_term)
pe[:, 1::2] = np.cos(position * div_term)
return torch.tensor(pe, dtype=torch.float32)
# 示例使用
max_len = 10 # 序列的最大长度
d_model = 512 # 模型的维度
positional_encoding = get_sinusoidal_positional_encoding(max_len, d_model)
print(positional_encoding.shape)3.输入拼接:
将词嵌入和位置编码的结果相加,得到最终的输入表示。这样,输入到编码器中的向量即包含了词汇的语义信息,又包含了其在序列中的位置信息,为后续的自注意力机制丰富的信息基础。
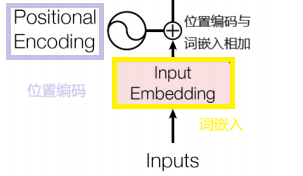
输入部分的图例解剖
插入 -RNN梯度消失:
总梯度被近距离梯度主导,被远距离梯度忽略不计。
第二部分-自注意力机制(Self-Attention Mechanism)
自注意力机制流程:
1.输入表示:
将输入序列的每个元素,通过嵌入层,得到输入向量。
2.生成Query,Key和Value向量:
1.Query(Q)查询向量:
主动发起查询:每个位置的Q向量主动与其他位置的K向量匹配,寻找需要关注的目标。例如:在句子中“猫追老鼠,因为老鼠它饿了”中,当处理“它”时,Q向量会尝试匹配“猫”和“老鼠”的K向量,确定指代的对象。
生成查询向量Q:![]()
2.Key(K)键向量:
被动响应查询:K向量作为被检查的“索引”,用于计算与Q的相似度。决定注意力的权重:Q和K的点积(相似度)经过softmax归一化后,形成注意力权重,表明哪些位置需要被关注。
生成键向量K:![]()
3.Value(V)值向量:
信息载体:V向量携带实际的注意力权重决定了如何从不同位置的V聚合信息。加权聚合:最终的输出是V的加权和,权重由Q和K的相似度决定。
生成值向量V:![]()
3.计算注意力分数:
计算查询向量Q与所有所有键向量K之间的相似度,常用点积衡量。为避免数值过大导致梯度问题,将点积结果除以缩放因子![]() (
(![]() 是键向量维度):
是键向量维度):
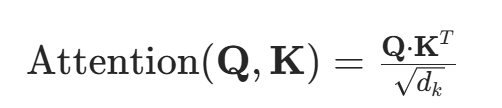
4.应用Softmax函数:
将注意力分数矩阵通过Softmax函数进行归一化,把相似度转化概率分布(权重),使权重和为1,这些权重表示序列中每个元素在当前计算中的相对重要性:
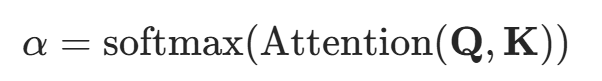
5.加权求和:
使用Softmax得到的权重α对值向量V进行加权求和,得到每个元素的最终输出:
![]()
最终输出是输入序列的加权和,综合考虑了序列中所有元素的相关性,捕捉到全局信息和长距离依赖关系,为了方便阅读,附上一张注意力机制输出output计算的详细公式:
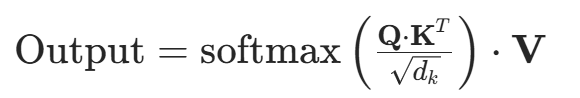
扩展:多头注意力机制 (Multi-Head Attention):
这是Transformer架构中核心组件,是自注意力机制的扩展,能够让模型在不同的表示子空间中并行地关注输入序列的不同部分,从而捕捉到更加丰富的特征信息。
自注意力机制虽然能够捕捉序列中的元素之间的全局依赖关系,但实际应用中,单一的注意力头可能只能关注到输入序列的某些特定方面的信息。多头注意力机制通过并行使用多个注意力头,每个头可以学习到不同的注意力模式,从不同的表示子空间中提取信息,使得模型能够更全面,更加丰富地表示输入。
生成多个查询,键和值向量,计算每个头的注意力输出,对于每个头i,使用与自注意力机制相同的方式计算注意力分数,应用Softmax函数进行加权求和,得到每个头的注意力输出head:
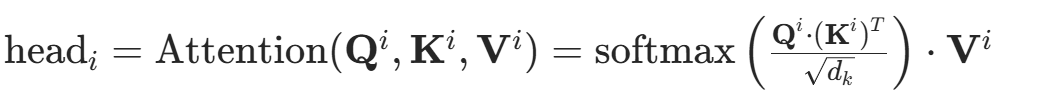 拼接多头输出:
拼接多头输出:
将所有头的注意力输出head1,head2,...,headh按列拼接起来,得到大矩阵: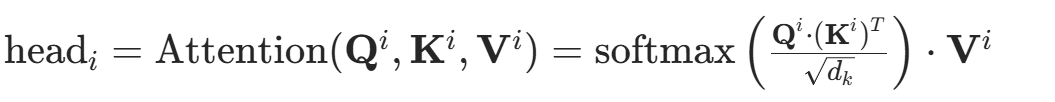
线性变换:
最后,使用一个可学习的权重矩阵对拼接后的矩阵进行线性变换,得到多头注意力机制的最终输出:
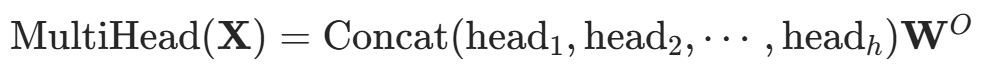
注意力机制的优势:
1.自注意力机制核心原理:
全局视野,自注意力机制允许每个词与其他词交互,无需依赖递归或卷积的逐步传播,动态计算权重,通过词与词之间的注意力权重,模型自主决定哪些位置需要重点关注,无论距离远近。
2.捕捉局部依赖机制:
相邻词的强关联:在自然语言中,相邻词(如形容词-名词,动词-宾语)往往具有高相关性,自注意力通过点积计算,自动赋予相邻词较高的权重。
3.捕捉长距离依赖的机制:
直接关联任意位置,无论间距多远,自注意力均能计算它们的关联性,避免RNN的梯度消失(RNN梯度消失插入:总梯度被近距离梯度主导,被远距离梯度忽略不计)
4.多头注意力增强多样性:
不同注意力头可关注不同类型的依赖关系(如 语法,语义,指代等),多头注意力机制的作用:并行多视角学习:每个注意力头通过独立投影,学习不同的交互模式:
头1可能关注局部语法(如主谓一致)
头2可能捕捉长距离语义(如如果关系)
头3可能聚焦代指关系(如名词和代词)
以下是基于pytorch实现的多头注意力机制代码:
import torch
import torch.nn as nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model must be divisible by num_heads"
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性变换
Q = self.W_q(Q)
K = self.W_k(K)
V = self.W_v(V)
# 分割多头
Q = Q.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = K.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = V.view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
if mask is not None:
mask = mask.unsqueeze(1)
# 计算注意力分数
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 应用Softmax函数
attn_probs = torch.softmax(attn_scores, dim=-1)
# 加权求和
output = torch.matmul(attn_probs, V)
# 拼接多头
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
# 线性变换
output = self.W_o(output)
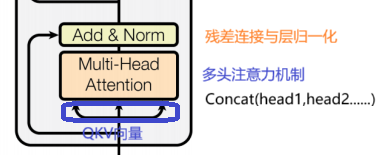
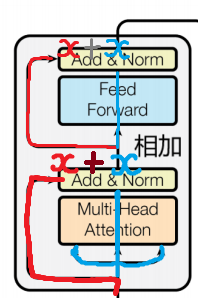
return output第二部分与第三部分的输出-残差连接与层归一化
残差连接是指:
把一个模块(比如自注意力机制或前馈神经网络)的输入逐渐绕过这个模块,与输出相加,再一起传给下一层。
结构表达:
详细公式如下:
1.注意力机制的残差连接公式:
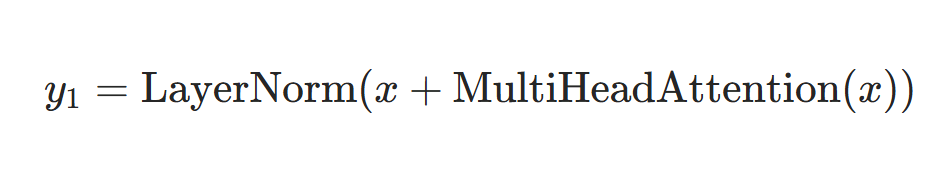
2.前馈神经网络的残差连接公式:
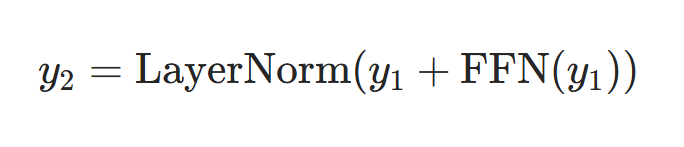
什么叫“残差”?
这个词原本来自于统计学,指的是预测值和真实值之间差距,比如你预测明天的温度是25度,实际是27度,那么残差是2。
在神经网络中,残差并不是单纯的预测误差,而是当前输出值和目标输出之间的差异。
残差的直观理解:你在写文章的时候,第一稿已经写好了,然后你的编辑提一个意见,他不让你重新写文章,而是在原稿上进行修改,也就是提出一个“残差”修改建议。
残差的优势:只学差异,网络学习的只是调整,比从头学习容易;信息保留,原始输入不会丢失,可以直接传入下一层;稳定训练模型,降低梯度消失风险,能训练更深的模型,总结:“残差”就是输入和目标之间的“微调”量,让模型不必重头学,只需要在已有的基础上进行改进。
为什么残差连接重要?
1.缓解梯度消失:
在深层网络中,梯度反向传播时会逐渐变小
残差连接提供了“捷径”,允许梯度直接流向浅层
2.保留原始信息:
即使网络层学习效果不佳,原始信息仍能通过
使网络可以专注于学习残差(变化部分)而非完整的映射
3.促进更深的网络结构:
使Transformer可以堆叠更多层(如BERT有12-24层,GPT-3有96层)
插入-什么叫梯度消失:
链式求导法则导致梯度衰减,在神经网络中梯度通过链式求导法则在各层之间反向传播。当网格层数很多时,每一层的梯度计算都涉及到多个因子的乘积。如果这些因子中大部分都小于1,那么随着层数的增加,梯度全呈指数级衰减,最终趋于0
例如:在使用sigmoid函数作为激活函数时,其导数的取值范围在0到0.25之间,当多个这样的导数相乘时,梯度很容易消失。
第三部分-前馈神经网络(Feed Forward Network, FFN)
FFN的核心作用:
(1)引入非线性变换:
自注意力机制本质上是线性加权求和(经管有Softmax,但整体任是线性运算),而FFN通过Relu等激活函数引入非线性,增强模型的表达能力。
(2) 逐位置独立计算:
自注意力是全局计算:每个token的输出依赖于所有其他token的加权组合。
FFN是逐位置计算:每个token独立通过FFN,不依赖其他位置的信息。这使得FFN可以专注于局部特征变换。
(3)特征升维&降维:
FFN采用先升维后降维的结构
先在高维空间进行复杂特征变换
再降维回原始维度,避免信息损失
代码pytorch实现
import torch
import torch.nn as nn
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff) # 升维
self.linear2 = nn.Linear(d_ff, d_model) # 降维
self.dropout = nn.Dropout(dropout)
self.activation = nn.GELU() # 也可以用 nn.ReLU()
def forward(self, x):
# x shape: (batch_size, seq_len, d_model)
x = self.linear1(x) # (batch_size, seq_len, d_ff)
x = self.activation(x)
x = self.dropout(x)
x = self.linear2(x) # (batch_size, seq_len, d_model)
return x
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)