视频流手语识别:运行HWGAT代码(小白保姆级)
简简单单运行一个手语识别模型,持续剖析模型,目的不仅仅是跑通还有理解,学习大佬的代码。
前言
HWGAT网络大家或许并不熟悉,24年发布的模型,用于手语识别,这篇博客的目的是记录我对于源码的理解和整理,如果有误欢迎大家留言。
模型源代码仓库
github
论文我也放在文章资源里面了
环境安装
源代码提供了requirements.txt文件,如下: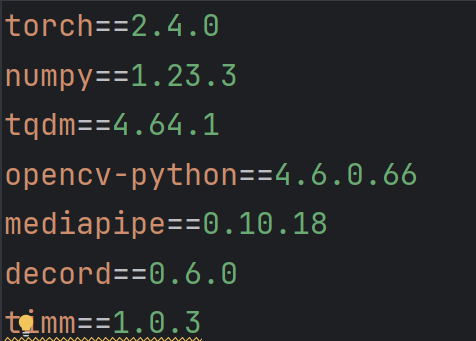
我这里采用conda环境,这里python环境不建议3.10以上,差不多3.9,3.10版本
方法1
不是很建议这么安装,因为我尝试了几次都报错失败了
conda create -n myenv python=3.9
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
方法2
conda create -n myenv python=3.9
pip install torch==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install numpy==1.23.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tqdm==4.64.1 -i
https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-python==4.6.0.66 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mediapipe==0.10.18 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install decord==0.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install timm==1.0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple
文件结构
大家如果下载了源码,会看见以下文件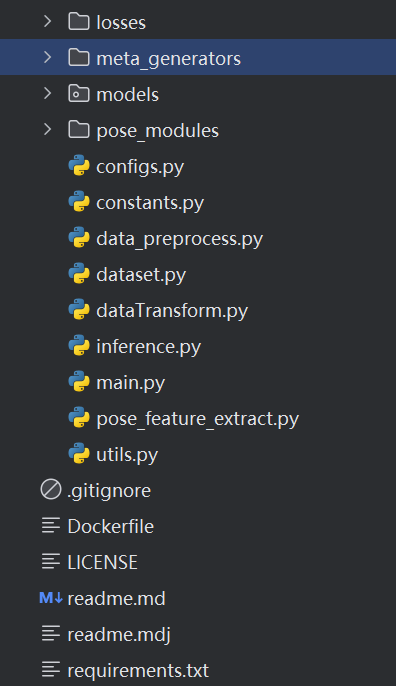
losses

里面只有一个py文件,是这个模型的损失函数,看名字就可以发现是一种改进版交叉熵损失函数,具体后面介绍。
meta_generators
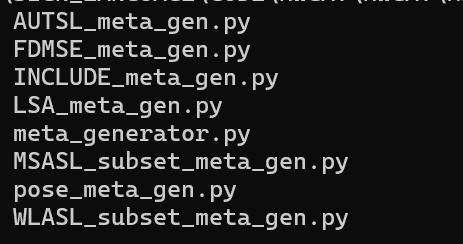
元数据生成器,用于生成描述数据集的文件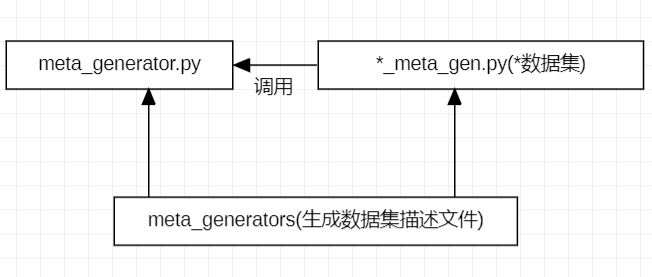
models
模型文件夹,用于搭建模型,这里不仅仅写了我们最终版HWGAT,还有作者消融实验用到的模型,以及作者对于其他模型的尝试。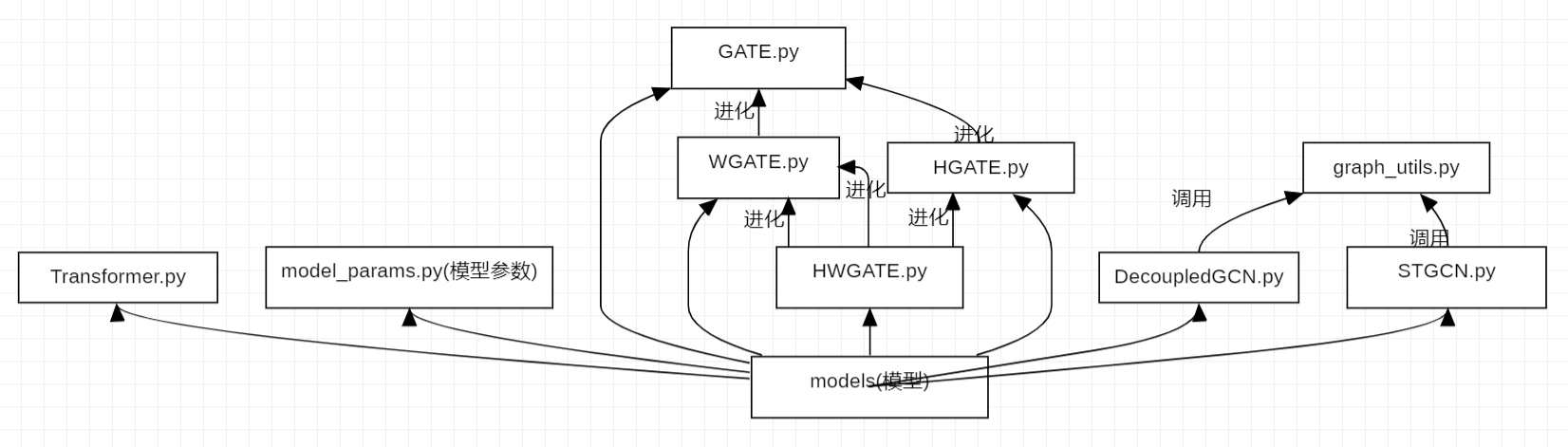
pose_modules
关键点检测模型,作者并没有选择自己搭建关键点模型,而是选择调用开源模型进行处理,这里有三个关键点模型,但是我主要采用的是mediapipe,所以另外两个模型就不再过多介绍,mediapipe后面介绍。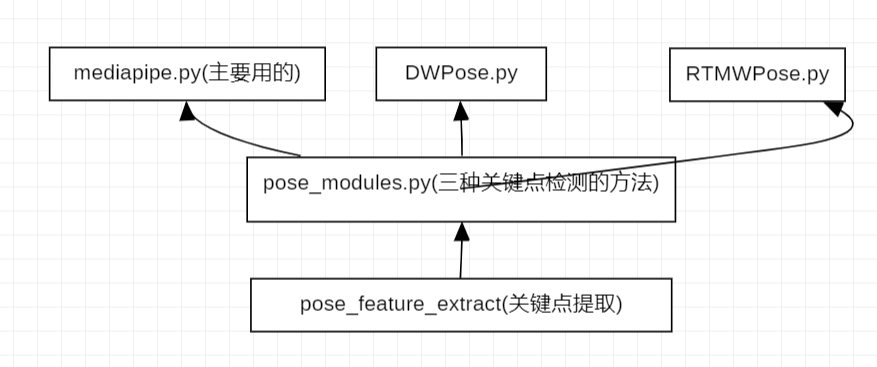
其他py文件
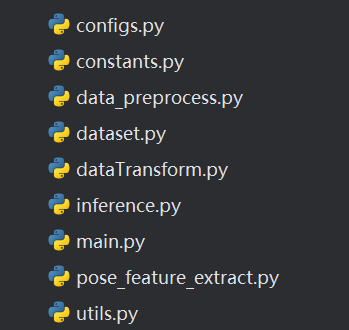
重点是pose_feature_extract.py用于调用pose_modules对视频进行关键点标注,data_preprocess.py用于对数据集进行预处理,main.py用于对模型进行训练,测试等。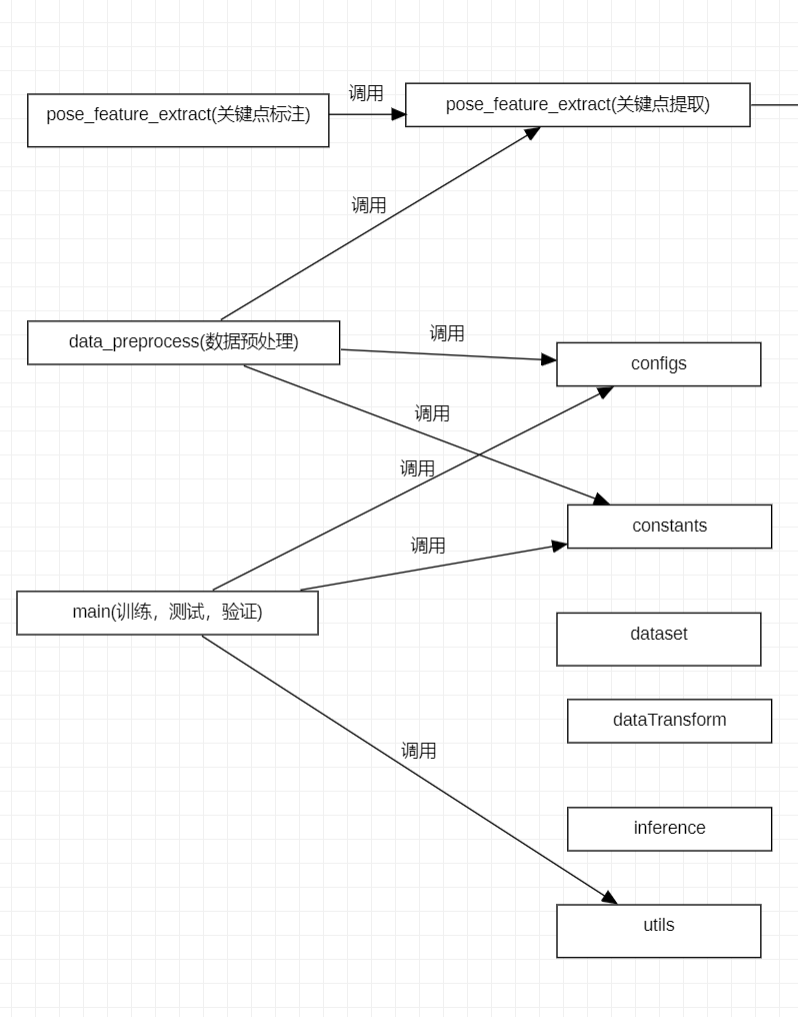
运行
准备自己的数据集
将自己的数据集放置在hwgat目录下,如图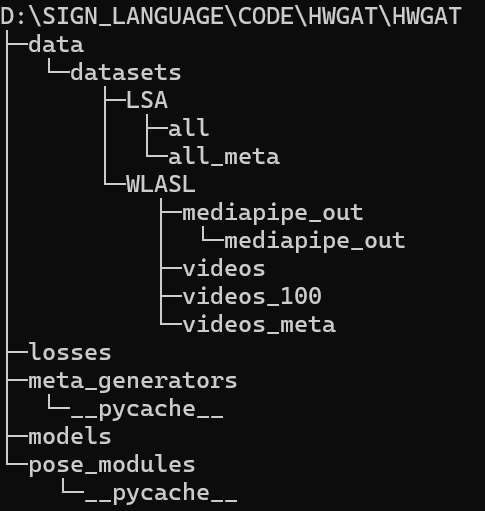
创建一个data文件夹,在下面再创建一个datasets文件夹,下面创建自己数据集名称的文件夹,如这里的LSA。
一个数据集通常需要有视频存放的文件夹,如这里的all是我数据集视频存放的位置,还需要记录对应数据集的标签名的文件。
生成元数据
python meta_generators/*_meta_gen.py
*改成你数据集的名称,如果是源代码使用过的数据集可以直接运行对应的py文件,如果是源代码没有的数据集需要自己写对应的代码。
已有代码
拿LSA数据集举例,作者提供了LSA_meta_gen文件,这里只需要修改下面这几行。
root = 'D:\\sign_language\\code\\hwgat\\hwgat\\data\\datasets\\LSA'#填数据集的根目录
data_path = os.path.join(root, "all")#数据集中存视频的文件名
class_path = os.path.join(root, "lsa64_sign.md")#数据集的标签文件
meta_path = os.path.join(root, 'LSA64_meta/')#输出文件名(自定义)
自己写代码
这里就需要搞清楚我们的目的是什么,输入输出是什么。
输入就是我们上面提的四个变量。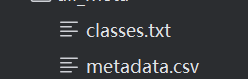
输出是这样的一个classes.txt文件和csv文件,txt里面按顺序每一行记录对应的标签名,csv文件里面每一个列分别记录id,数据集视频路径,数据集视频名称,标签,以及用于train还是val,test。
作者在meta_generator文件里面提供了generate_meta函数可以实现后续功能,所以我们自己的代码只需要提供这个函数的三个参数,分别是data_path,rows,vocab,data_path是我们最开始就提供了的数据集视频文件夹名,用os连成路径就可以输入,rows是一个二维列表,每个视频的id,路径,文件名,标签,用途为一个列表,vocab是存标签的列表。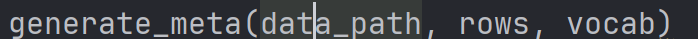
关键点标注
输出为一个mediapipe_out文件夹,里面存有很多.pkl文件
python pose_feature_extract.py --root './data/datasets/*' --meta './data/datasets/*/*_meta/metadata.csv' -m mediapipe --out_path 'mediapipe_out/'
*里面填数据集的名称,root是数据集的路径,meta是上一部生成的元数据文件的路径,m是使用什么方法,这里建议使用mediapie,out_path是输出文件的名称是什么(自定义)。
注意
1.这一步比较消耗内存,如果出现跑一半程序输出不动的情况,直接暂停之后再次运行,下一次不会运行上一次已经运行的部分。(如果本地跑不动可以考虑使用飞浆云计算跑,我不是推销,只是真的觉得好用,关键是免费)
2.这一步比较容易出现问题,注意观察输出了什么,如果输出出现Error -->(上面的rows的内容),就要知道自己这里路径写的有问题,可能出问题的地方有三个,一第一步元数据路径问题,二第二步填写的路径问题,三代码中的问题(不知道是我的系统是windows还是什么原因,生成的路径确实不太对,自己修改了源代码的路径才成功的)。
数据预处理
输出为一个input文件夹和output文件夹
python data_preprocess.py --root /data/datasets/*/ --ds * --meta /data/datasets/*/*_meta/metadata.csv --dr mediapipe_out/ -kpm mediapipe -ft keypoints
*填入数据集的名称,root是数据集路径,ds是你希望在生成input里面这个数据集的名称,meta是第一步生成的元数据路径,dr是第二步生成的文件夹名称,kpm是指定之前用的关键点模型名,ft是说什么类型的模型。
input生成以下内容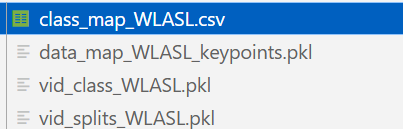
运行模型进行训练
python main.py -m train -d * --model HWGATE
*是数据集名称,model是指定要使用的模型,m是指定运行的模式,d是数据集名称
将在output下生成结果,如下:
不同时间生成的对应后缀不一样。
测试模型
python main.py -m test -d * --model HWGAT -t 240227_1807 -px best_loss
m是模式,d是数据集,model是模型,t是你需要测试的模型在output里生成的对应时间,px是你要选择pt文件类型。
总结
后面再出代码解读的博客。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)