基于注意力机制的CNN - LSTM高频多元加密货币趋势预测
随着加密货币市场的快速发展,高频交易成为主流,但面临预测不稳定和交易次数过多的问题。本文提出了一种基于局部极小值序列的三分类趋势标注方法,有效减少随机波动带来的无效交易。同时,我们开发了一种新型ACLMC模型,结合CNN、LSTM和注意力机制,支持多币种同步预测,优化了模型性能并降低了投资风险。实验结果表明,与现有方法相比,我们的方法在财务指标上表现更优,且交易次数显著减少,为加密货币市场的高频交
Abstract
随着比特币、以太坊等多种加密货币价格攀升,近年来加密货币市场已成为最受欢迎的投资领域。与其他相对更稳定的金融衍生品不同,加密货币市场波动性极高,这就要求在量化交易中使用高频率的预测模型。然而,由于预测结果不稳定且误差率高,过多的交易次数成为一大难题。为缓解这一问题,我们基于对高频数据的观察,用局部极小值序列替换原始序列,并提出了一种更为稳健的三分类趋势标注方法,通过影响模型训练来减少交易次数。此外,我们还提出了一种面向多种加密货币的注意力机制 CNN–LSTM 新模型(ACLMC),通过挖掘不同频率和不同币种之间的关联来优化模型性能,并通过支持多币种同步预测来平滑预测误差带来的投资风险。实验表明,我们的标注方法与 ACLMC 相结合,相比传统基线在财务指标上更具优势且交易次数更少。
Introduce
背景与问题自2008年比特币诞生以来,加密货币市场价格大幅波动,交易全天候进行,吸引了大量投资者。与传统金融衍生品相比,加密货币波动更剧烈,低频策略难以应对,需要高频预测与交易。高频交易中,价格的随机小幅振荡会导致预测序列不稳定,从而带来过多的买卖次数及手续费成本。文章中给出了金融序列的随机性质具体例子,如图所示在22:20-01:40时间段出现了随机的波动。
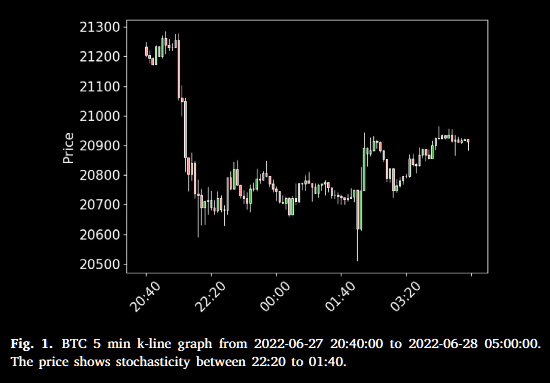
现有方法的不足:传统的趋势标注多基于相邻时点价格差,难以过滤高频噪声,预测目标易被随机波动干扰。虽有部分工作关注高频价格或趋势预测,但很少在回测中考虑交易次数,对高频环境下的手续费影响重视不足。
文章中提出了两方法,三分类趋势标注方法、ACLMC 模型。
三分类趋势标注方法:以局部极小值序列替代原始序列,剔除随机噪声;将趋势划分为“上涨/下跌/平稳”三类,并允许在一定阈值内的小幅波动,提高标签稳定性,减少候选交易点数。
ACLMC 模型(Attention-based CNN–LSTM for Multiple Cryptocurrencies):结合 CNN和LSTM,利用注意力机制分别融合多频率和多币种特征;通过多预测器并行输出,支持多币种同步交易,平滑单一币种预测误差带来的风险。实验验证:所提标注方法与模型在多项财务指标(超额收益、夏普比率等)和交易次数上均优于多种基线策略。
Related work
Trend labeling method
趋势预测可以分为两大方向:回归和分类。回归方法是对价格变化建模,预测未来的实际价格或当前与未来价格的差值,通常将下一时刻的收盘价直接作为当前的预测标签。但是回归不符投资者需求,分类方法更切合“涨跌”预期。分类方法的目标是基于两点之间的价格差来预测未来趋势,传统二元/三元分类易受高频随机波动干扰,标签不稳定,而新兴二元方法通过阈值合并小波动,提升收益率。
Price series prediction
叙述了几种价格序列预测模型,传统 ML 算法已应用于金融预测,但 RNN/LSTM 成为主流以捕捉时序特征。NLP 情绪分析、CNN 局部特征提取及 CNN–LSTM 结构、注意力机制等多种技术被广泛采用,均显著优于单一模型。去噪和异常点处理(如去噪自编码器、DTW+聚类)可进一步提高模型鲁棒性,但对市场新风格的适应性仍待增强。
基于这个相关工作的总结,引出下文三分类趋势标注方法和ACLMC模型。
Methodologies
Price trend labeling method
传统的标注方法难以直接用于高频加密货币预测。高频交易相较于低频交易虽能提供更多获利机会,但也会产生过多的交易次数及手续费开销。大多数现有模型难以将预测精度提升到足以覆盖这些成本,因此,提升预测序列的稳定性并合理合并高频交易时点,成为缓解该问题的关键。文章中给出的是局部极小值序列替代和三分类自动标注。
局部极小值序列替代:
对原始收盘价序列 ,提取所有满足
的点,构建局部极小值序列
。在高频环境中,随机波动会产生更多极小值,使两者差距在可接受范围内,从而有效削弱噪声。下面给出了一个例子,使用随机选择的 BNB 的5分钟频率数据段,将原始收盘价序列绘制成红色,并将局部最小值序列绘制成蓝色进行比较。
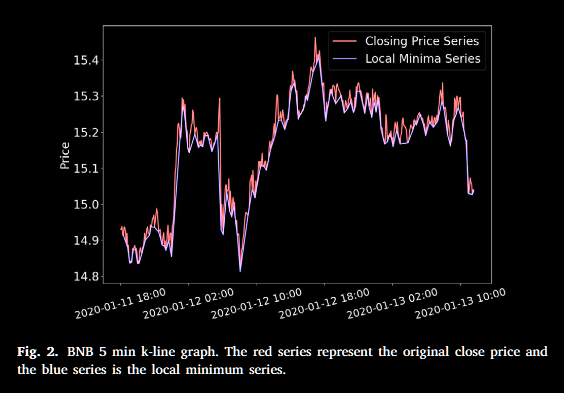
三分类自动标注:
在极小值序列上引入两个超参数:趋势反转阈值 和平稳区间阈值
,以及当前趋势标记
,初始设为
。遍历极小值序列的每个点,当
时,视为未突破当前趋势,仅更新区间极值;否则视为趋势反转,回退到上一个极值点,将区间内所有点标为:
-
若区间波动
,则标记为“平稳”(0);
- 否则标记为当前趋势d(+1 或 –1)。然后翻转 d,重新设置区间起点,继续遍历。此方法可减少因随机小振荡导致的无效交易时点。
ACLMC model
ACLMC(Attention-based CNN–LSTM for Multiple Cryptocurrencies)结合卷积神经网(CNN)、长短期记忆网络(LSTM)与注意力机制,针对多币种、多频率的高频预测任务设计,整体的ACLMC模型的整体结构如下所示:
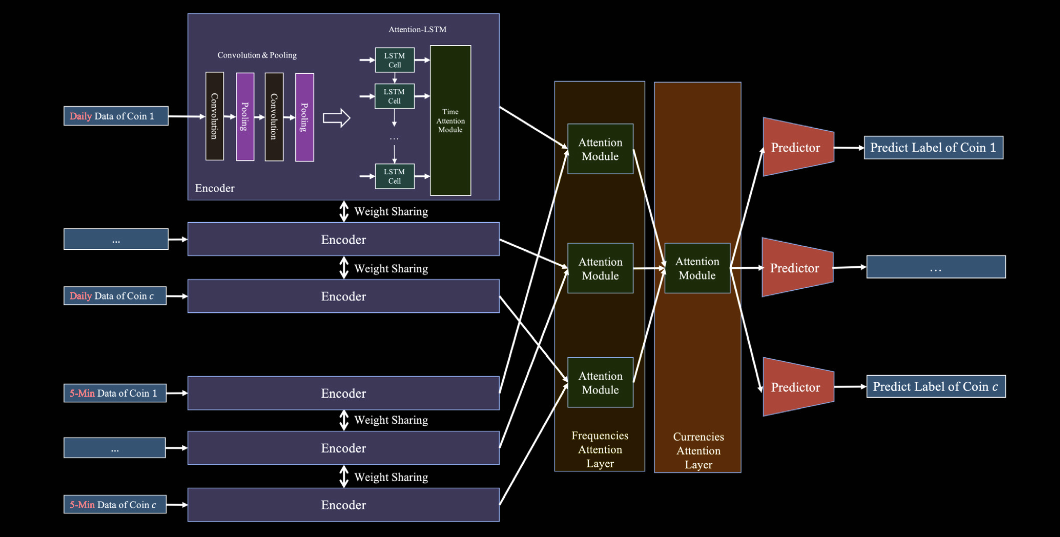
整个结构从左至右可以分成功四个部分,对于每个币种收集当前时刻下的两种频率的数据,从过权重共享编码器,保证不同币种的同频数据能学到同一套特征抽取规则,之后将数据放在注意力融合层,通过频率注意力和币种注意力得到多预测输出。
CNN–LSTM 编码器
针对“5 分钟”和“1日”两种频率的数据,各自使用一个 CNN–LSTM 模块提取局部特征与时序信息;同频不同币种间共享编码器权重,以学习通用模式。编码器输出隐藏表示:
频率注意力层
对同一币种在不同频率下的隐藏表示 与
应用注意力融合,得到融合特征:
币种注意力层
将每个币种的融合特征 与所有其他币种特征集合进行注意力融合,挖掘跨币种信息:
多预测器输出
为每个币种设计多层感知机预测器
,将融合后特征映射为三分类概率
(上涨/下跌/平稳):
以所有币种的累积交叉熵损失联合训练,优化模型参数。
这种结构能选择性地融合多频与跨币种信息,支持多币种同步预测,从而提升整体预测准确性,并通过减少预测波动和冲击交易次数来降低交易成本。
Experiment
Datasets
实验中,从币安(Binance)采集 2020-01-01 至 2022-06-01 的历史交易数据。剔除与美元 1∶1 挂钩的 USDT、USDC,最终选取市值前五:比特币(BTC)、以太坊(ETH)、币安币(BNB)、瑞波(XRP)和艾达币(ADA)。将原始交易数据分别按 5 分钟和日频统计,计算出下表中列举的 42 项财务因子;对每种币用 Min–Max 归一化。训练集为 2020-01-01 至 2021-11-01,测试集为 2021-11-10 至 2022-06-01。

Experimental settings
硬件与框架:CentOS + NVIDIA 1080Ti,PyTorch 1.11.0。
标注方法超参:
模型超参:学习率 0.001(cosine 调度),Adam 优化器(默认);批量大小 128,最多 20 个 epoch(早停);输入序列长度 30,隐藏层维度 128。
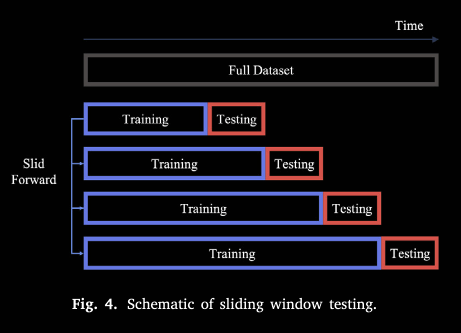
滑动窗口测试:窗口长度 2880 个 5 min 点(10 天),每次仅预测窗口内数据,然后将该段并入训练集,窗口前移重复,最终对整个测试集模拟交易并计算指标。
Evaluation metrics
现有的大多数工作从分类指标和财务指标两个角度评估比较效应。然而,训练过程中发现,分类指标和财务指标之间的相关性很弱。这是因为财务指标不仅受准确分类数量的影响,还受准确位置的影响。在高波动性头寸中进行正确预测与在低波动性头寸中进行正确预测带来的回报截然不同。因此,倾向于正确判断动率头寸的模型可能具有相似的分类指标和明显不同的财务指标,而倾向于正确判断小波动率头寸的模型则明显不同。我们采用两种常用的交易策略,买入持有和多空进行模拟。
多空策略和买入持有策略的区别在于,多空策略不仅允许低价买入货币,高价卖出,即多头头寸,还允许以高价借入和卖出货币,并以低价买回,即空头头寸。
交易时点:仅在标注用的局部极小值处进行,预测在 t 时标签,在 t+1 做单,避免未来数据泄露。
评估指标中采用了四种评估指标来估计模型的效果:
超额收益ER(策略回报减去基准,越大越好)、
交易次数NT(越少手续费越低)、
Sharpe比率SR ( 其中
为策略平均回报,
为无风险利率,
为策略回报标准差,
越高,表示每单位风险收益越高)、
最大回撤MDD(投资从峰值到谷底的最大跌幅 )
Labeling method analysis
对标记方法和传统方法进行改造。
传统二元标注:
以不同 生成标签。
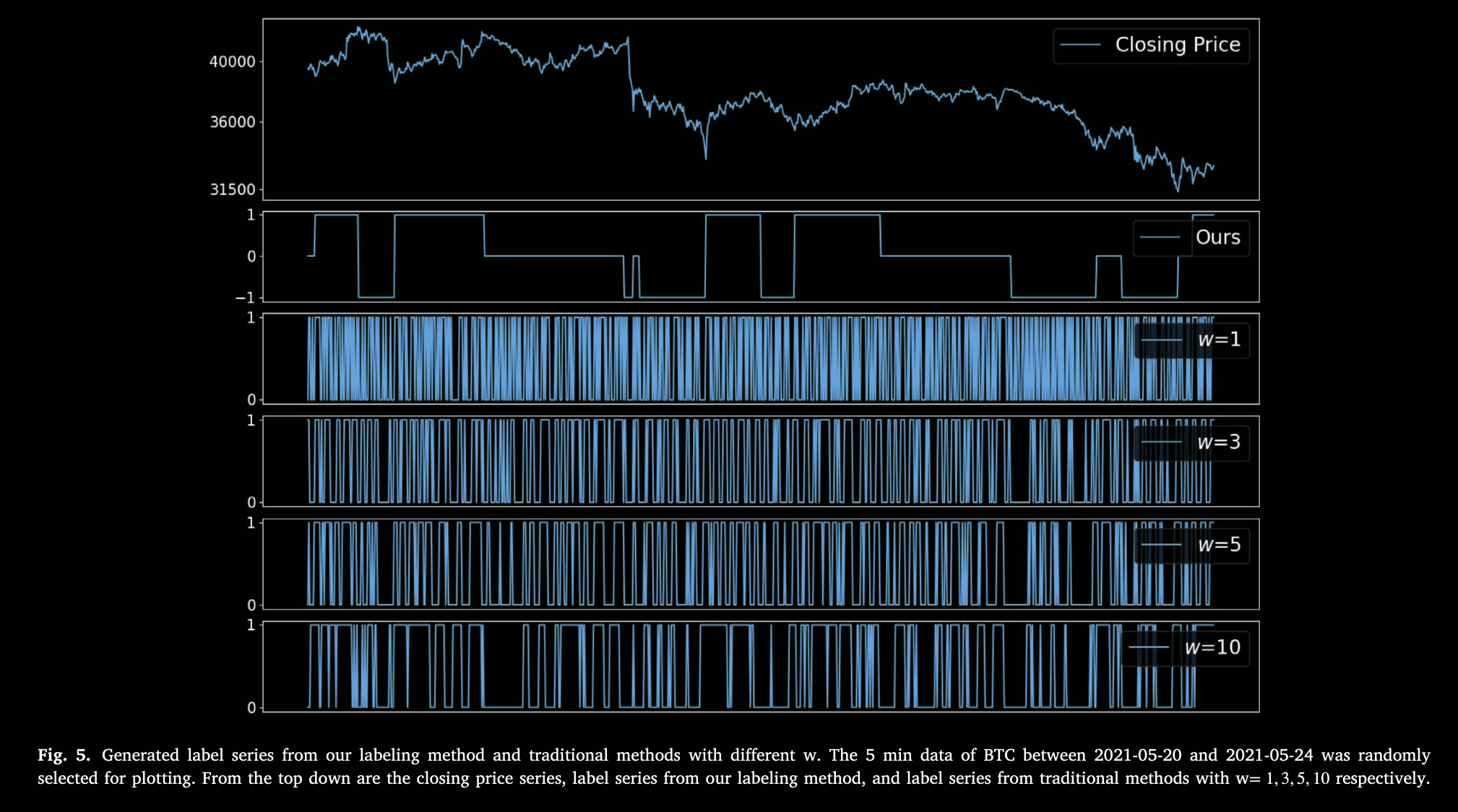
将传统的二元标注改造成三元标注,下图展示了不同 下的标签序列,比较三元和二元标注。三元的优势是增加平稳的标注,避免了横盘无效交易,更加平滑,剔除高频随机抖动。
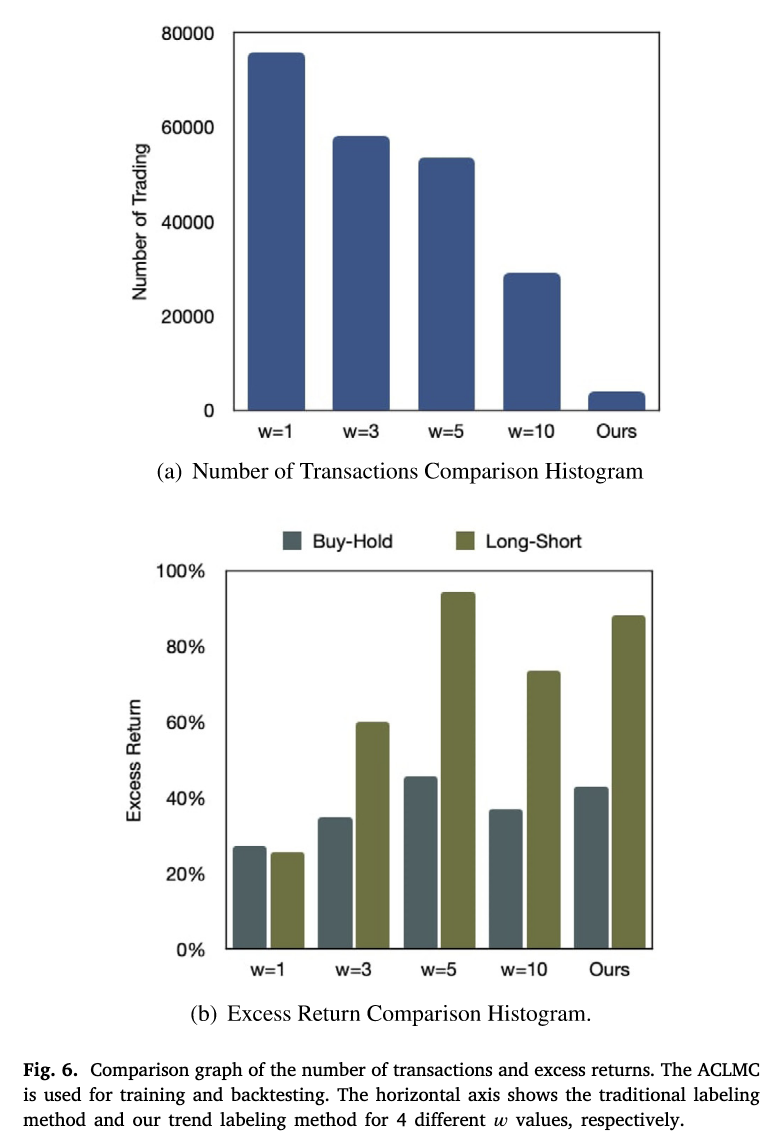
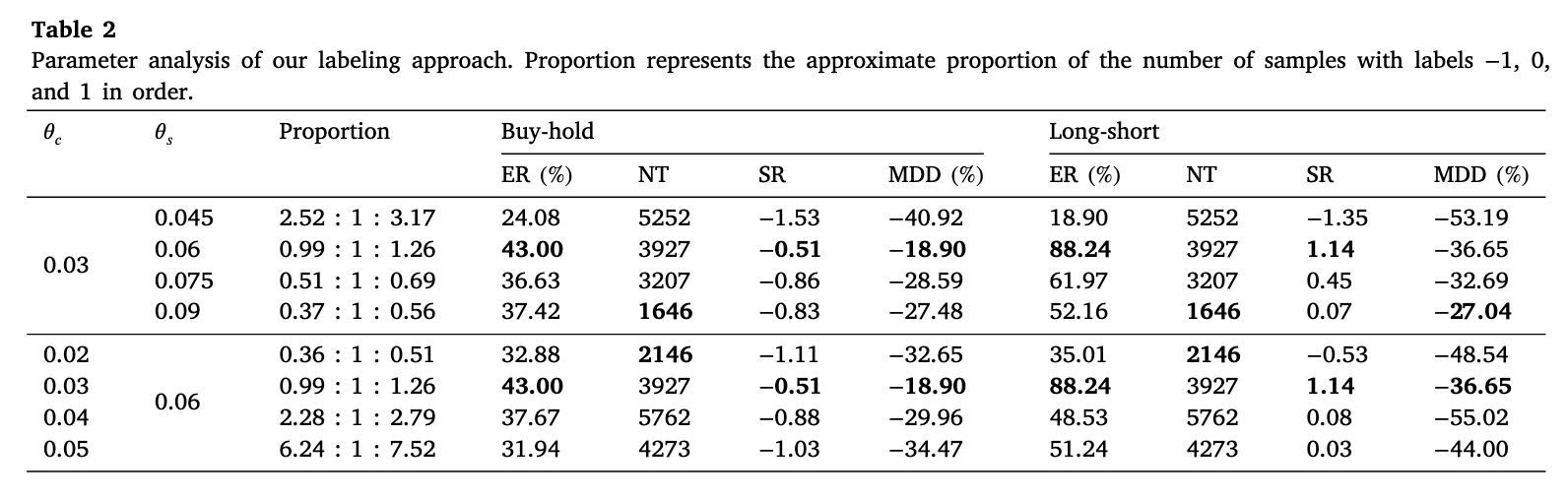
调整会显著改变 (−1:0:+1)三类样本比例,进而影响交易次数与超额收益。建议统一统计标签比例,搜索较平衡的参数(本文取
)。
章节总结:传统二元标注缺“平稳”类别,易引入噪声交易。三分类标注更平滑、可控交易点 决定标签分布,需调参平衡三类样本。
Model analysis
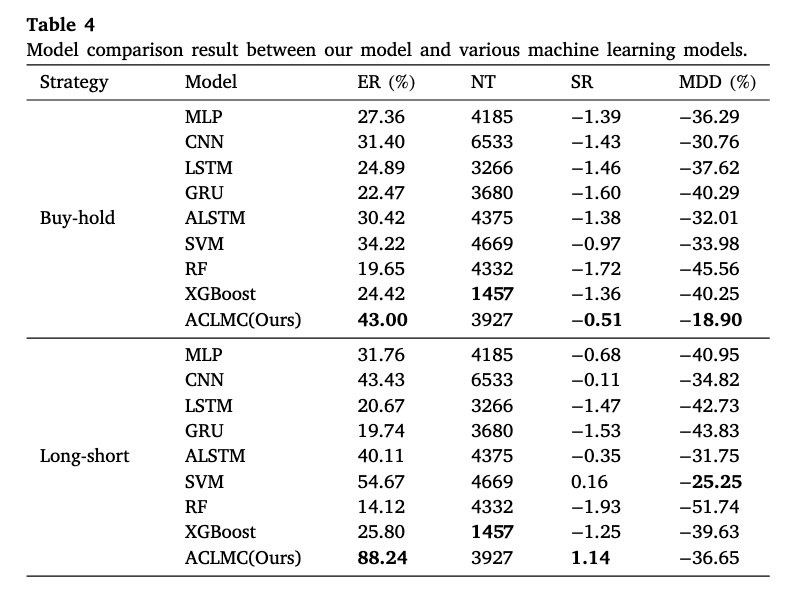
在模型性能对比中,ACLMC 在“买入持有”和“多空”两种模拟策略下均表现最佳,其超额收益和夏普比率显著超越了传统机器学习(如 SVM、随机森林、XGBoost)及常见神经网络模型(包括多层感知机、卷积网络、LSTM、GRU 和带注意力的 LSTM),而且交易次数也维持在合理水平(见下表,下图)。
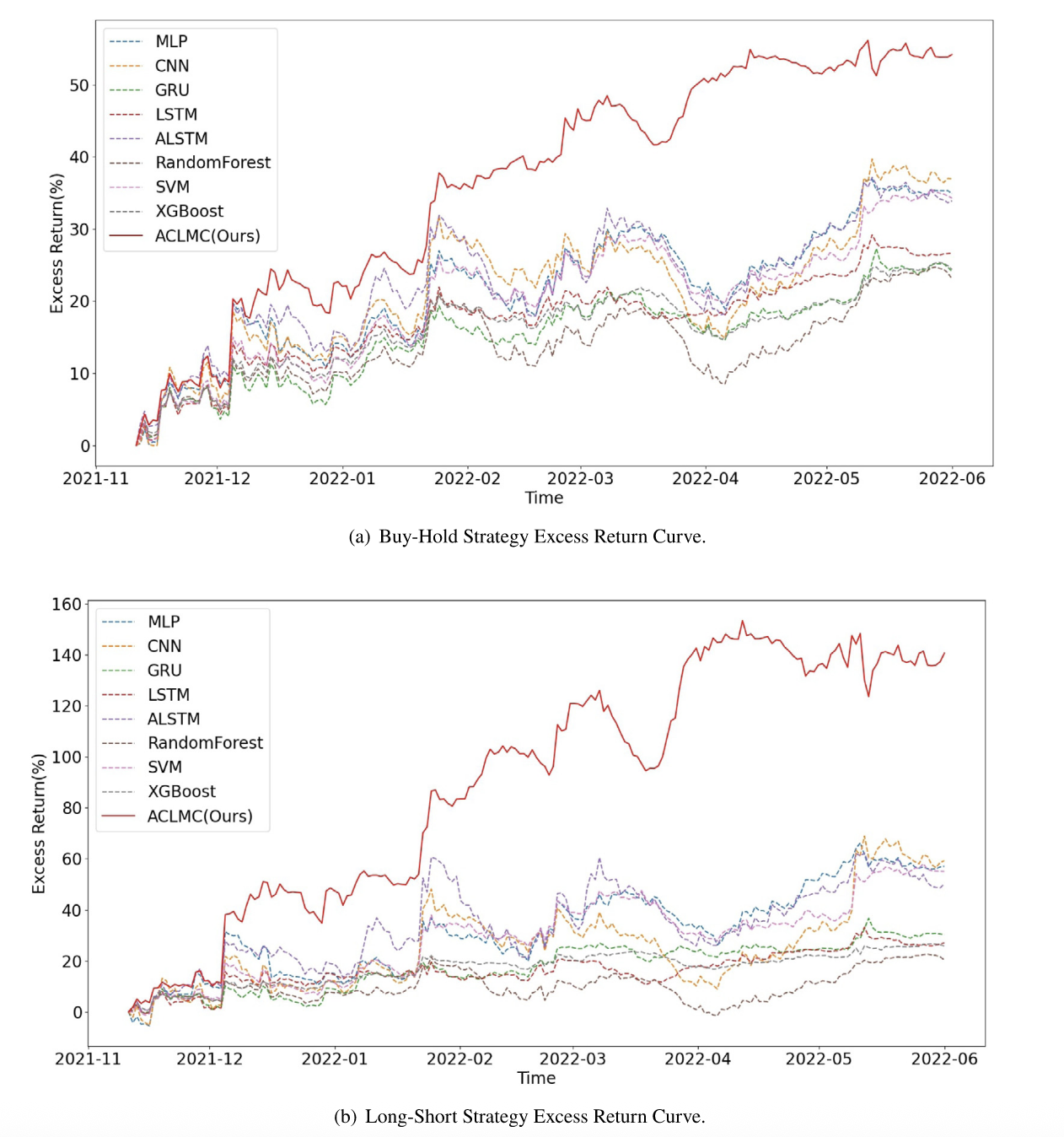
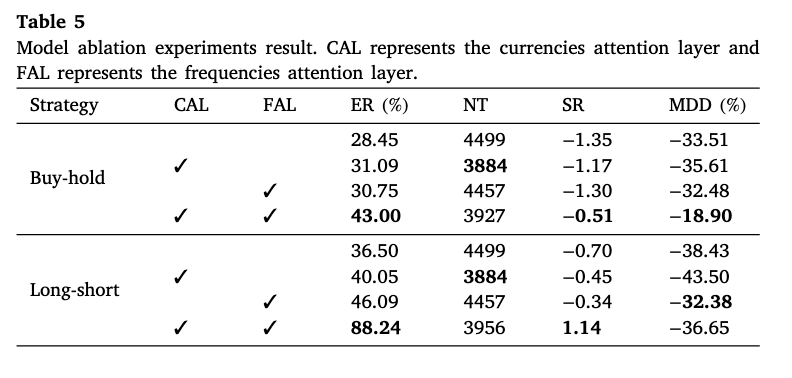
进一步的消融实验表明,引入频率注意力层或币种注意力层均能在不同程度上提升超额收益、优化风险回报比并降低最大回撤;当两种注意力模块同时启用时,模型的超额收益几乎翻倍,风险控制也明显改善(参见下表,下图)。
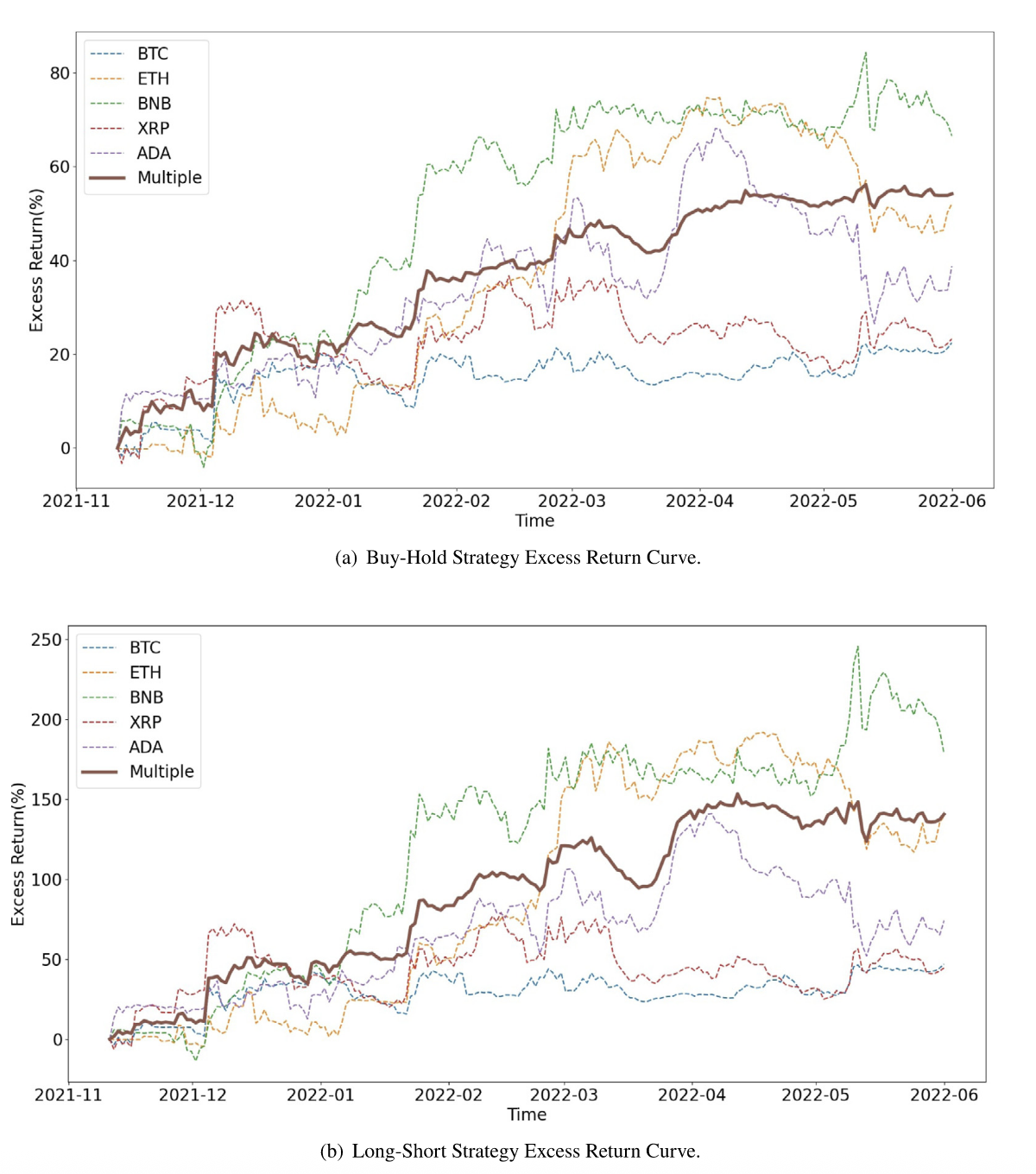
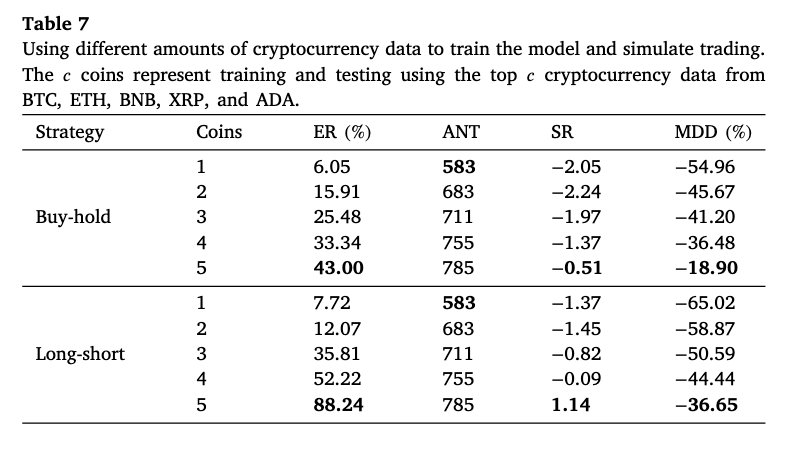
此外,通过逐步增加训练中所用币种数量以及同步对多个币种进行预测,ACLMC 能利用更多市场信息提高预测精度,并借助多币种组合分散单币种预测误差带来的风险,从而获得更平滑且更稳健的回报曲线(详见下表,下图)。
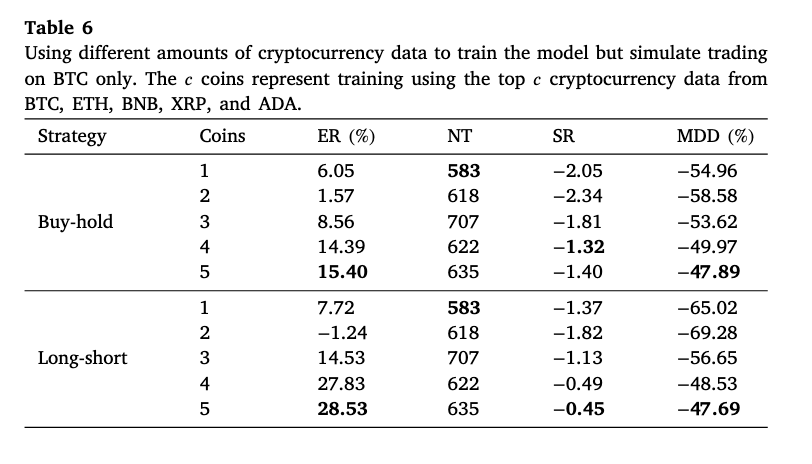
多币种并行预测
Conclusion
本文主要贡献包括两点:
首先,提出了一种针对高频交易的三分类趋势标注方法。该方法利用局部极小值序列剔除高频随机噪声,并在涨、跌之外增加“平稳”类别,从而生成更平滑、稳定的标签序列,显著减少了因传统二元标注带来的高频过度交易次数,同时只带来极小的超额收益损失。
其次,设计了 ACLMC 模型,该模型通过双层注意力机制分别在统计频率(如5分钟和日线)和币种维度上选择性融合特征,实现了多频、多币信息的协同利用。ACLMC 支持多币种同步预测,从而分散单一币种预测误差带来的风险,显著提升了超额收益、Sharpe 比率等多项财务指标,并将交易次数控制在合理范围内。
作者也指出了当前工作的两大局限:一是标注方法对阈值超参数较敏感,需进一步研究自动调参或鲁棒训练策略以应对类别失衡;二是在极端“黑天鹅”事件下,5 分钟频率可能仍不足以及时捕捉市场剧变,后续可考虑更高频率或引入意外事件检测与建模机制。
By Superx,written in chengdu

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)