YOLOv8训练过程与结果评价指标分析
训练完成后产生的文件如下首先我们需要明确精确率与召回率,即分别反映预测准确性和正类覆盖能力。精确率关注预测结果中正确识别的比例,召回率侧重真实正类中被正确找出的比例。两者常需权衡,具体应用场景决定侧重方向。**精确率(Precision)**衡量模型预测为正类的样本中真实正类的比例。其计算公式为:精确率=TP/(TP+FP),其中TP为真正例(预测正确且实际为正类的样本),FP为假正例(预测错误但
前言
训练完成后产生的文件如下
首先我们需要明确精确率与召回率,即分别反映预测准确性和正类覆盖能力。
精确率关注预测结果中正确识别的比例,召回率侧重真实正类中被正确找出的比例。
两者常需权衡,具体应用场景决定侧重方向。
**精确率(Precision)**衡量模型预测为正类的样本中真实正类的比例。其计算公式为:精确率=TP/(TP+FP),其中TP为真正例(预测正确且实际为正类的样本),FP为假正例(预测错误但实际为负类的样本)。例如,在垃圾邮件检测中,若模型将100封邮件标记为垃圾邮件,其中90封确实是垃圾邮件,则精确率为90%。高精确率意味着模型预测为正类的可信度较高,避免误判带来的负面影响。
召回率(Recall)表示实际为正类的样本中被模型正确识别的比例,计算公式为:召回率=TP/(TP+FN),FN为假负例(预测错误但实际为正类的样本)。例如,在疾病筛查中,若实际患病的100人中模型检测出80人,则召回率为80%。高召回率说明模型能有效减少漏检,适用于对遗漏正类敏感的场景(如癌症诊断)。
精确率和召回率通常呈此消彼长的关系。提高分类阈值可能提升精确率但降低召回率,降低阈值则可能反之。实际应用中需根据需求选择侧重方向:金融风控强调精确率(避免误封正常账户),而灾害预警更重视召回率(减少漏报风险)。调和两者的常用指标是F1分数,通过调和平均平衡两者的重要性。
接下来分析每个文件中数据指标的含义
1. 混淆矩阵与其归一化
混淆矩阵通常是一个二维矩阵,其行表示实际类别,列表示预测类别。对于一个二分类问题,混淆矩阵的构成元素如下:
- 真正例(TP, True Positive):模型正确预测为正类的样本数量。
- 假正例(FP, False Positive):模型错误地将负类预测为正类的样本数量。
- 真负例(TN, True Negative):模型正确预测为负类的样本数量。
- 假负例(FN, False Negative):模型错误地将正类预测为负类的样本数量。
如下图所示: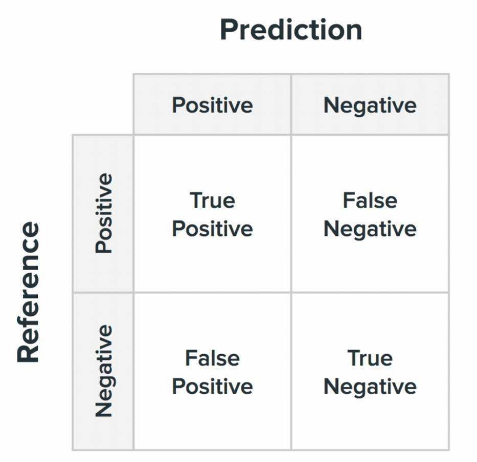

横轴处为样本类型,纵轴处为预测结果
对于多分类问题,混淆矩阵的规模会相应扩大,但基本原理相同。每个元素表示模型在特定类别上的预测与实际标签的匹配情况。
通过混淆矩阵,可以直观地了解模型在各个类别上的表现:
- 对角线元素:表示模型正确分类的样本数量,对角线上的值越大,说明模型在对应类别上的分类效果越好。
- 非对角线元素:表示模型错误分类的样本数量,非对角线上的值越小,说明模型的误分类情况越少。
- 每一行的和:表示实际属于该类别的样本总数。
- 每一列的和:表示模型预测为该类别的样本总数。
通过分析混淆矩阵,可以计算出一些重要的评估指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数等,这些指标能够更全面地反映模型的性能。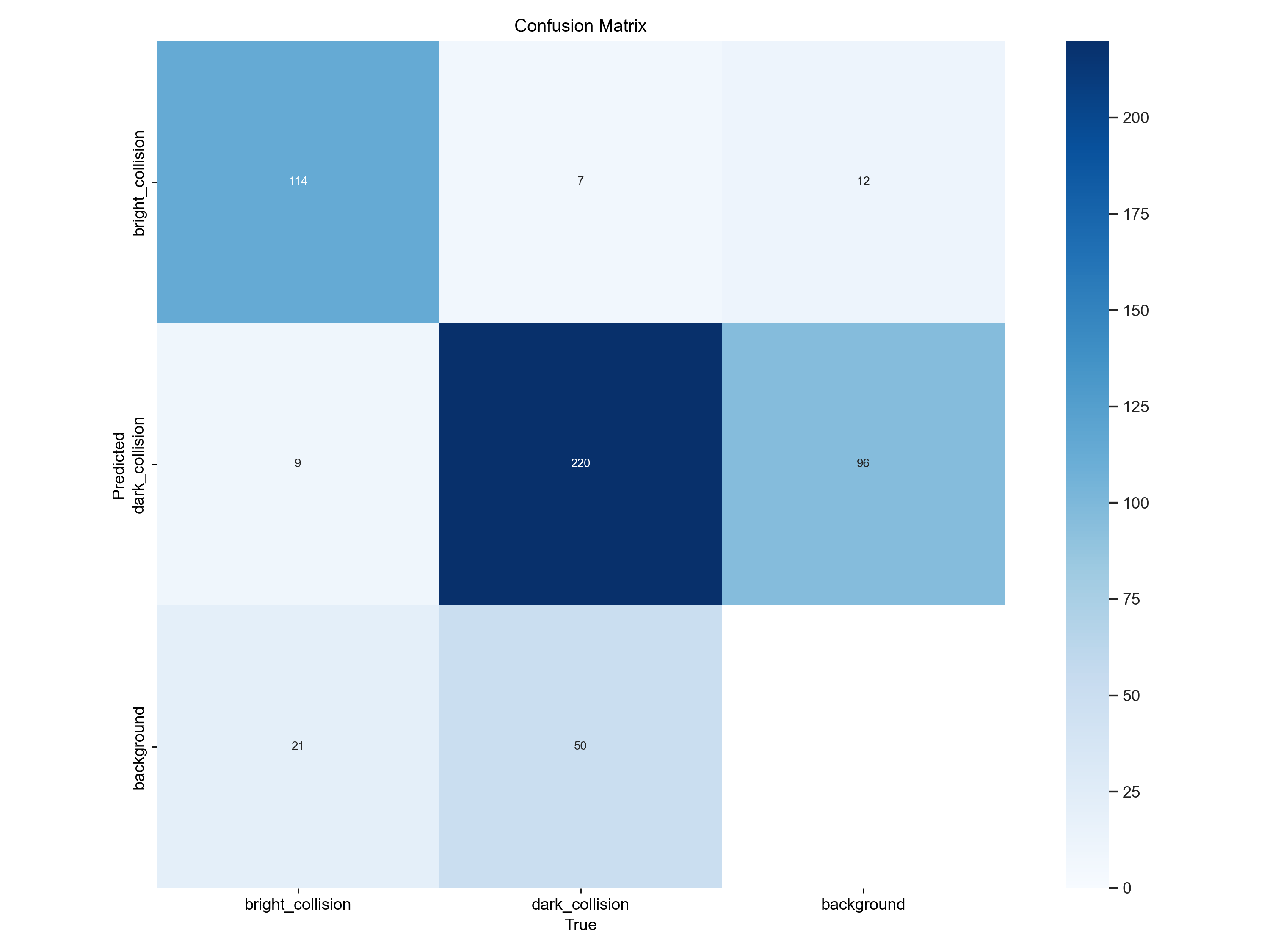
通过如上混淆矩阵即可判断验证情况
bright_collision的例子被预测为bright_collision的个数为114个
bright_collision的例子被误判为dark_collision的个数为9个
bright_collision的例子被误判为背景的个数为21个
归一化混淆矩阵的目的是为了更好地比较不同类别之间的分类性能,尤其是在类别不平衡的情况下。在实际应用中,数据集中的各类别样本数量可能差异较大,例如某些类别可能只有少数样本,而其他类别则有大量样本。这种情况下,直接使用普通混淆矩阵可能会导致对模型性能的误判。通过归一化,可以将混淆矩阵中的每个元素转换为相对比例,从而更公平地评估模型在各个类别上的表现。
实际如下: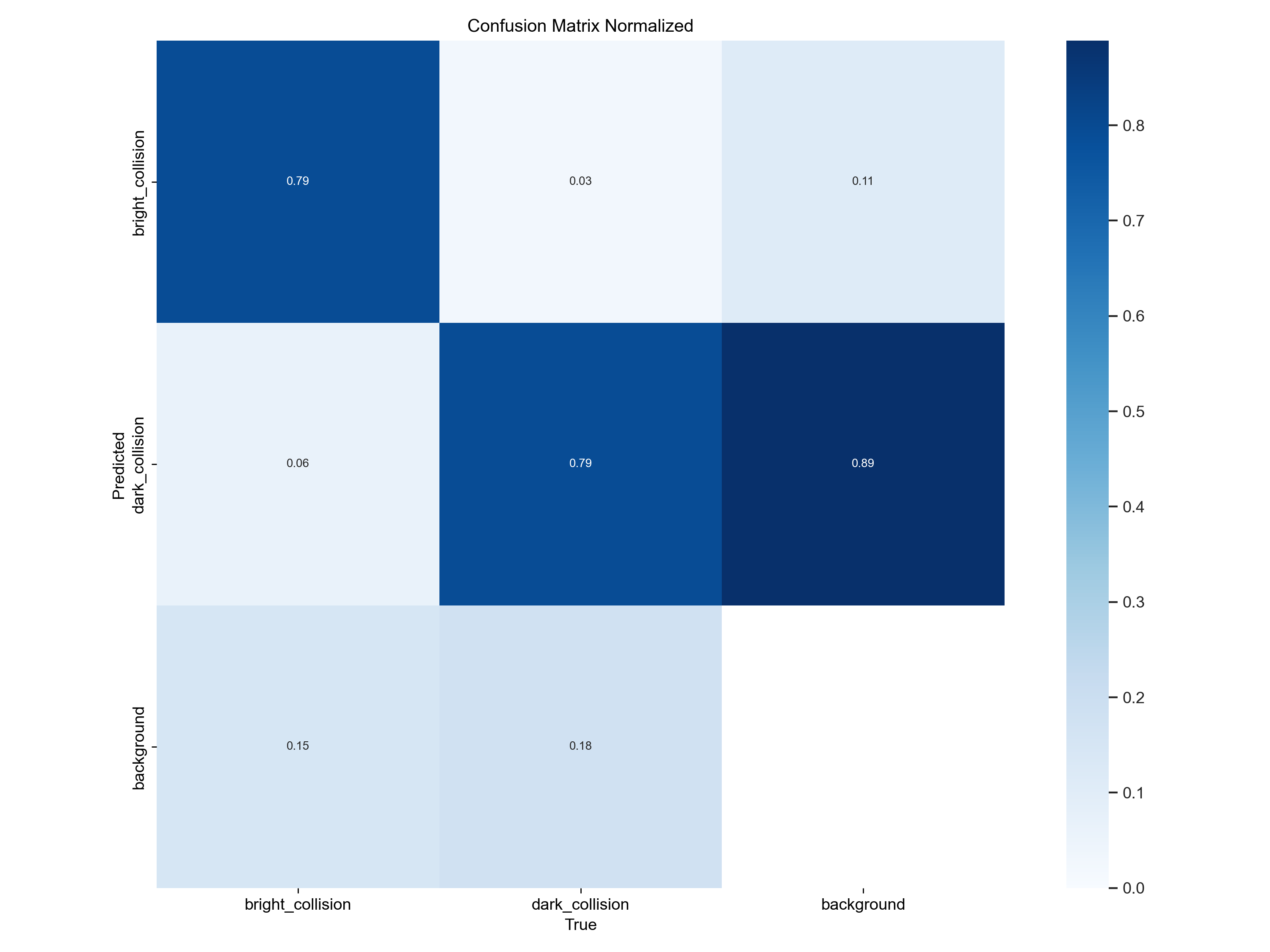
2. 四种分数曲线
2.1 F1分数
F1分数是机器学习中用于评估分类模型性能的一个重要指标,它是精确率(Precision)和召回率(Recall)的调和平均数。F1分数的取值范围在0到1之间,值越接近1,表示模型的性能越好。具体来说,F1分数综合考虑了模型在预测正样本时的准确性和完整性,能够平衡精确率和召回率之间的关系,避免因过度关注某一指标而导致模型性能评估的片面性。
F1分数的计算公式如下:
其中,精确率(Precision)表示模型预测为正类的样本中实际为正类的比例,计算公式为:
召回率(Recall)表示实际为正类的样本中被模型正确预测为正类的比例,计算公式为: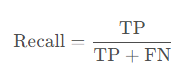
在这里,TP表示真正例(True Positive),即模型正确预测为正类的样本数量;FP表示假正例(False Positive),即模型错误地将负类预测为正类的样本数量;FN表示假负例(False Negative),即模型错误地将正类预测为负类的样本数量。
F1曲线是一种用于展示F1分数随置信度阈值变化的图表。在目标检测或分类任务中,模型会为每个预测结果分配一个置信度值,表示模型对该预测结果的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响精确率和召回率。F1曲线的意义在于:
- 平衡精确率和召回率:F1曲线能够直观地展示在不同置信度阈值下,模型的F1分数变化情况。通过观察F1曲线,可以找到一个合适的置信度阈值,使得模型在精确率和召回率之间达到较好的平衡。
- 评估模型性能:F1曲线的形状和位置可以反映模型的整体性能。一般来说,F1曲线越靠近右上角,表示模型在不同置信度阈值下都能保持较高的F1分数,即模型的性能越好。如果F1曲线在较低置信度阈值下就达到了较高的F1分数,并且在较高置信度阈值下仍能保持相对稳定的F1分数,这说明模型在预测时能够较好地平衡精确率和召回率,具有较高的准确性和鲁棒性。
- 比较不同模型:F1曲线还可以用于比较不同模型之间的性能。当多个模型的F1曲线在同一图表中展示时,可以通过比较曲线的位置和形状来判断哪个模型在不同置信度阈值下表现更好。如果一个模型的F1曲线始终高于另一个模型的F1曲线,那么可以认为该模型在整体性能上优于另一个模型。
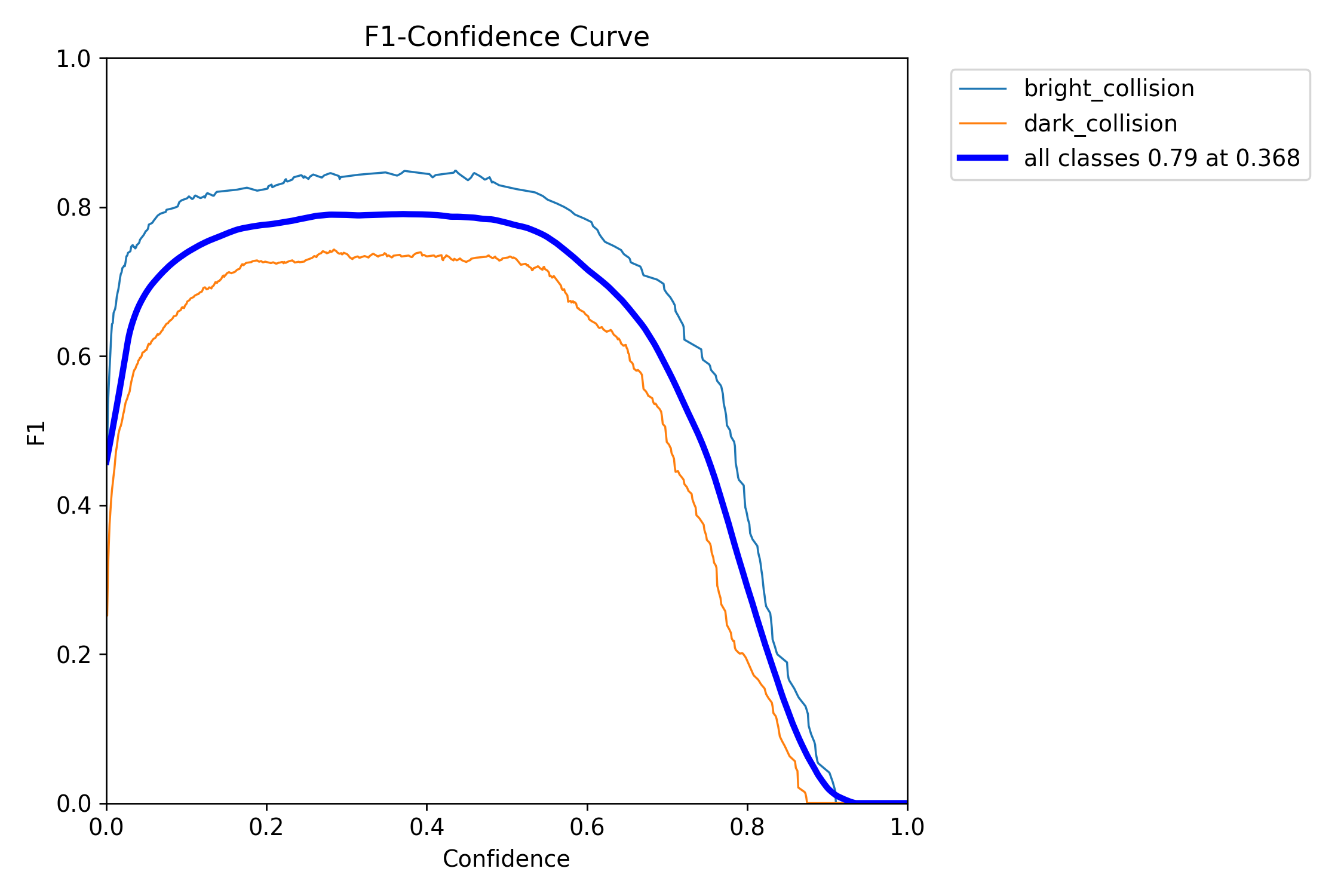
由图可知:置信度阈值在0.3-0.5之间时效果最好。
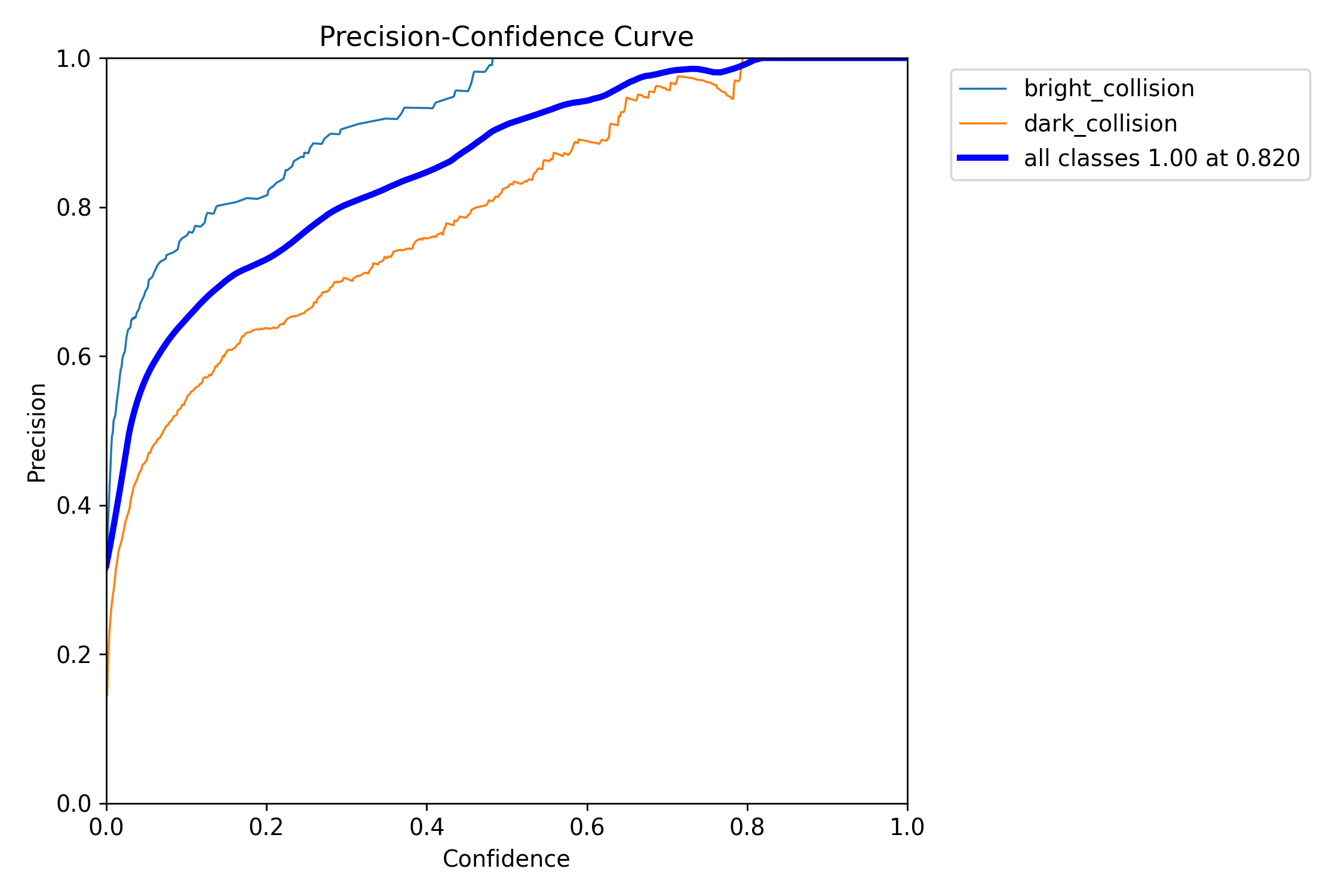
2.2 精度置信曲线
精度(Precision)是评估分类模型性能的重要指标之一,它反映了模型预测为正类的样本中实际为正类的比例。对于目标检测任务,精度的计算公式为: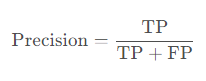
其中,TP(True Positive)表示模型正确预测为正类的样本数量,FP(False Positive)表示模型错误地将负类预测为正类的样本数量。
在目标检测中,精度的计算通常基于置信度阈值。模型会对每个预测框分配一个置信度值,表示模型对该预测框的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响精度的计
精度曲线展示了精度随置信度阈值变化的趋势,精度曲线特点如下:
- 高置信度阈值:当置信度阈值较高时,模型只保留置信度较高的预测框,此时FP数量较少,精度通常较高。但随着置信度阈值的进一步提高,TP数量也会减少,导致精度曲线趋于平稳或略有下降。
- 低置信度阈值:当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时精度通常较低。
- 最优置信度阈值:通过观察精度曲线,可以找到一个合适的置信度阈值,使得模型在精度和召回率之间达到较好的平衡。例如,在某些应用中,可能需要较高的精度来确保预测结果的可靠性,此时可以选择较高的置信度阈值;而在其他应用中,可能更关注召回率,此时可以选择较低的置信度阈值。
精度曲线在模型评估中的作用主要体现在以下几个方面:
- 评估模型性能:精度曲线能够直观地展示模型在不同置信度阈值下的性能变化。通过观察曲线的走势,可以判断模型在高置信度和低置信度情况下的表现。一般来说,精度曲线越靠近右上角,表示模型在高置信度下能够保持较高的精度,说明模型的性能较好。
- 选择合适的置信度阈值:精度曲线可以帮助研究人员和开发者选择合适的置信度阈值。在实际应用中,不同的应用场景对精度和召回率的要求不同。通过分析精度曲线,可以找到一个合适的置信度阈值,使得模型在满足特定需求的情况下达到最佳性能。
- 指导模型优化:通过分析精度曲线,可以发现模型在某些置信度阈值下的性能瓶颈。例如,如果精度曲线在低置信度阈值下下降较快,可能说明模型在处理低置信度预测时存在较多的误分类。此时,可以通过调整模型的训练策略、优化损失函数或改进数据预处理方法来提高模型在低置信度阈值下的性能。
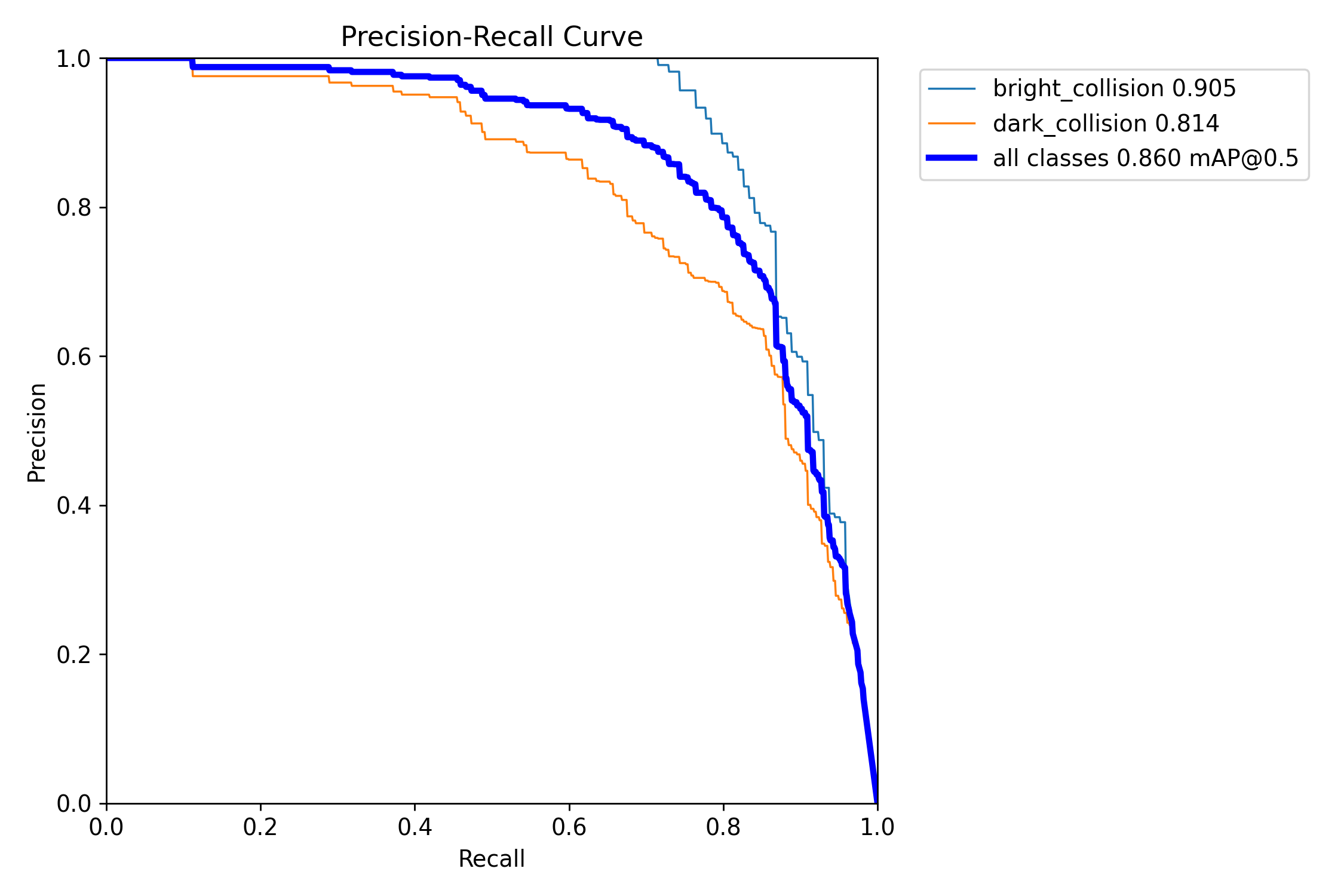
2.3 精确召回度曲线
召回率(Recall)是评估分类模型性能的重要指标之一,它反映了模型能够正确识别出的正样本占所有实际正样本的比例。对于目标检测任务,召回率的计算公式为: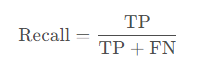
其中,TP(True Positive)表示模型正确预测为正类的样本数量,FN(False Negative)表示模型错误地将正类预测为负类的样本数量。
在目标检测中,召回率的计算通常基于置信度阈值。模型会对每个预测框分配一个置信度值,表示模型对该预测框的自信程度。通过调整置信度阈值,可以改变模型的预测结果,从而影响召回率的计算。
精度(Precision)和召回率(Recall)是评估分类模型性能的两个重要指标,它们之间存在一定的关系:
- 平衡关系:精度和召回率通常是一对矛盾的指标。提高精度可能会降低召回率,反之亦然。例如,当置信度阈值较高时,模型只保留置信度较高的预测框,此时FP数量较少,精度较高,但FN数量可能增加,导致召回率较低;而当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时召回率较高,但精度可能较低。
- 综合评估:在实际应用中,需要根据具体需求平衡精度和召回率。例如,在某些应用中,可能需要较高的精度来确保预测结果的可靠性,此时可以选择较高的置信度阈值;而在其他应用中,可能更关注召回率,此时可以选择较低的置信度阈值。
2.4 召回置信度曲线
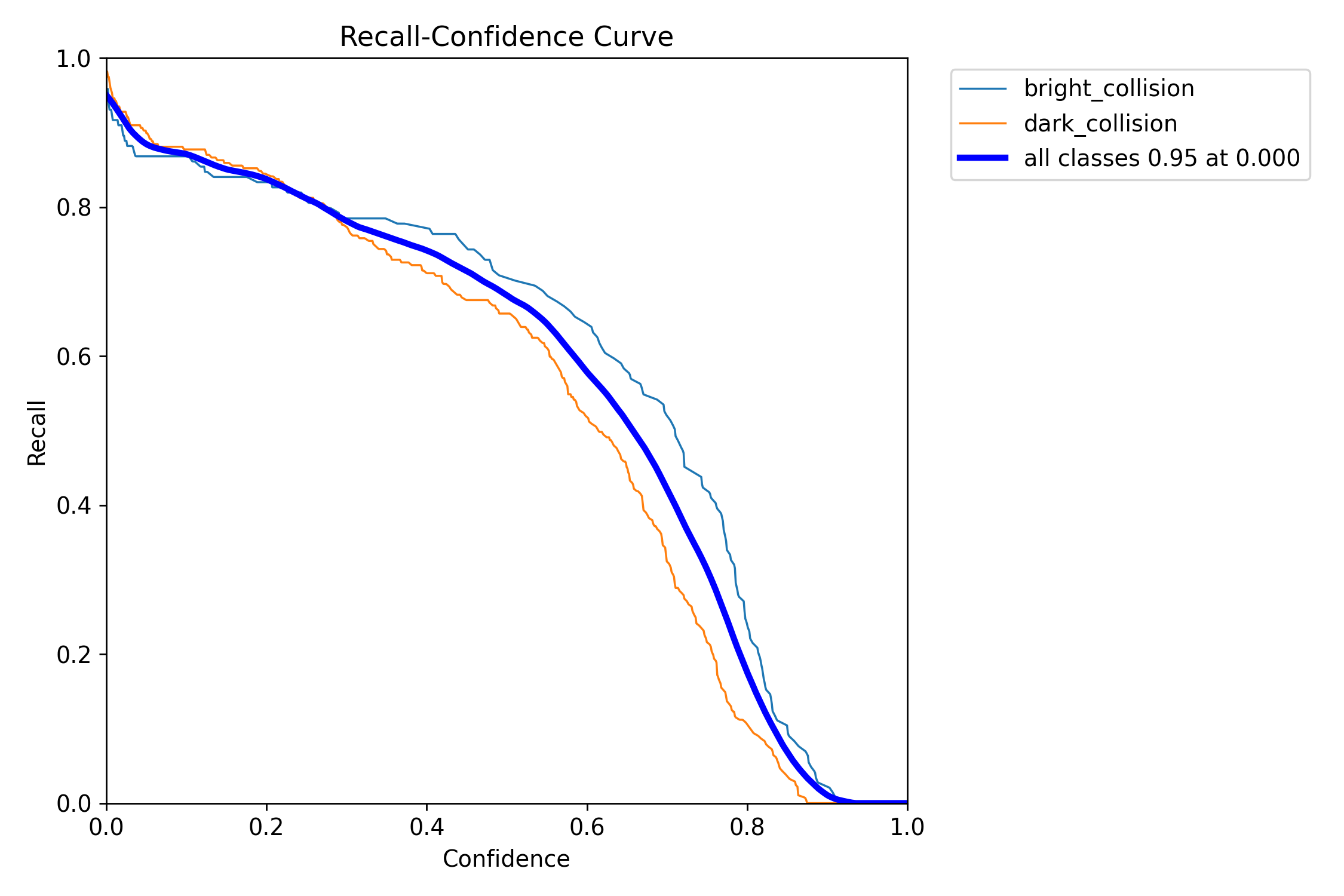
该曲线的导数即下降趋势可以作为漏报增加快慢的衡量值,如上图在置信度0.6后召回率快速下降,即漏报可能性快速增加。
召回率曲线展示了召回率随置信度阈值变化的趋势。通常,召回率曲线具有以下特点:
- 高置信度阈值:当置信度阈值较高时,模型只保留置信度较高的预测框,此时FN数量较多,召回率通常较低。例如,在目标检测中,如果模型只保留置信度高于0.9的预测框,可能会漏掉很多实际为正类但置信度稍低的样本,导致召回率下降。
- 低置信度阈值:当置信度阈值较低时,模型会保留更多的预测框,包括大量可能错误的预测框(FP),此时FN数量减少,召回率通常较高。例如,当置信度阈值为0.1时,模型可能会将更多的样本预测为正类,从而提高召回率,但可能会引入更多的误分类。
- 最优置信度阈值:通过观察召回率曲线,可以找到一个合适的置信度阈值,使得模型在召回率和精度之间达到较好的平衡。例如,在某些应用中,可能需要较高的召回率来确保不漏掉重要样本,此时可以选择较低的置信度阈值;而在其他应用中,可能更关注精度,此时可以选择较高的置信度阈值。
3. 训练过程曲线
第一排为训练过程中的三个损失、精确度与召回率。
第二排为验证过程中的三个损失、精确度与召回率。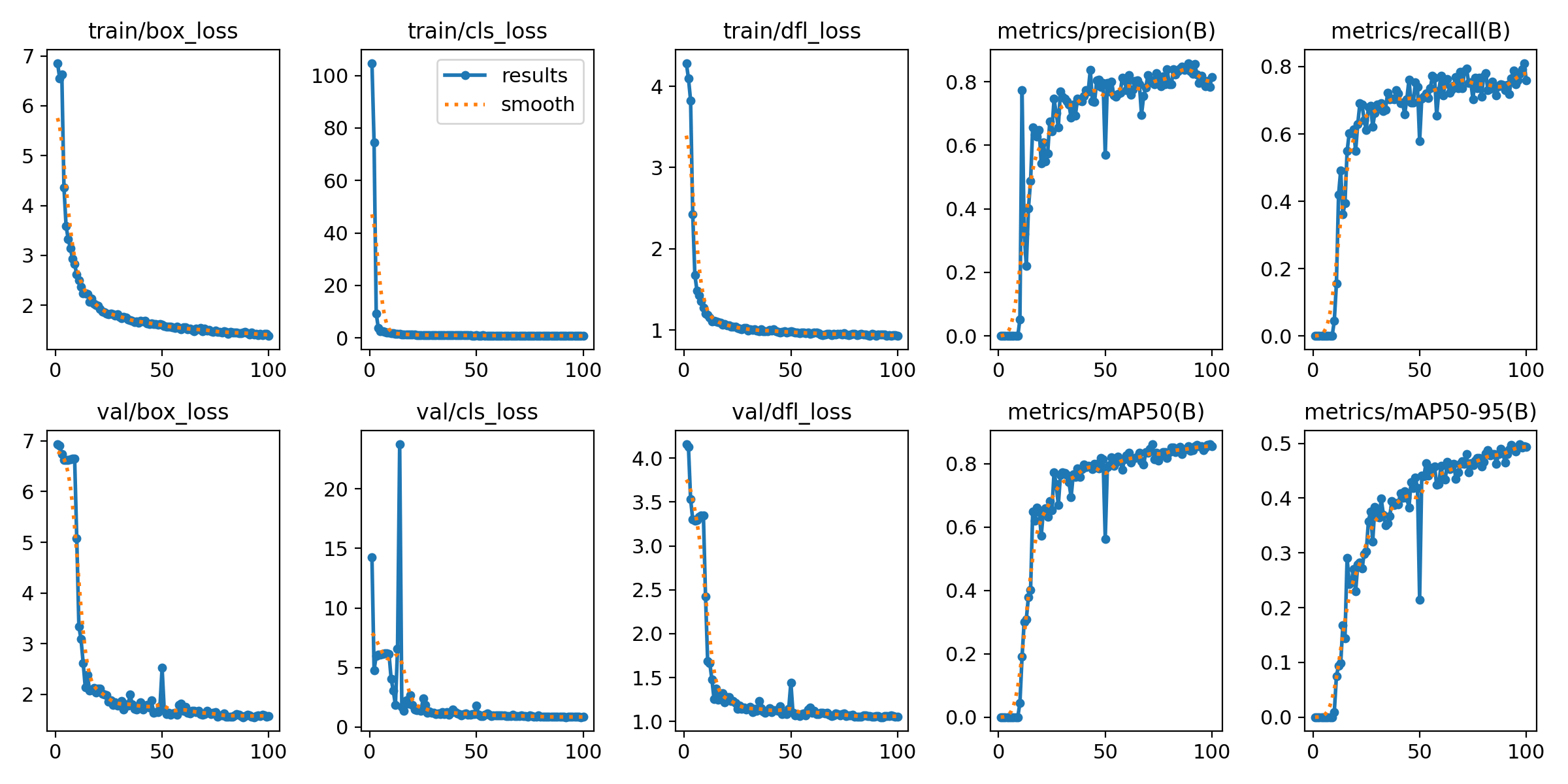
此处曲线数据同时由生成文件中results.csv记录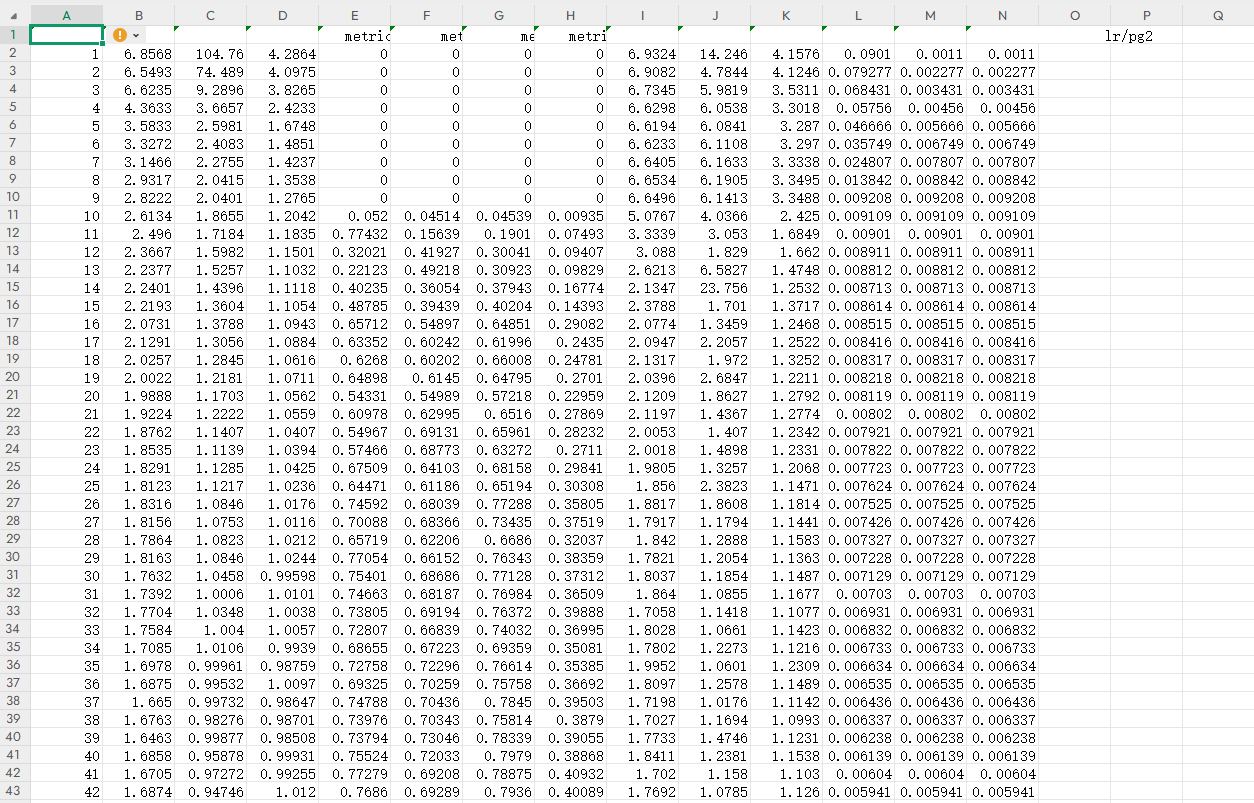
这里训练了100轮。YOLOv8三个损失,分别是:
1.box_loss(边界框损失):这个损失函数用于计算预测边界框与真实边界框之间的差异。YOLOv8使用IOU(Intersection overUnion)作为度量,来衡量两个边界框之间的重叠程度。box_loss通过计算预测框与真实框之间的IOU,来衡量预测框的位置准确度,并将其转化为一个损失值。通过最小化box_loss,模型可以学习到更准确的边界框位置。
2.cls_loss(分类损失):这个损失函数用于计算预测类别与真实类别之间的差异。YOLOv8使用交叉熵损失(Cross Entropy Loss)来衡量分类准确度。cls_loss通过比较预测类别分布与真实类别标签之间的差异,来计算分类的损失值。通过最小化cls_loss,模型可以学习到更准确的类别分类。
3.dfl_loss(特征点损失):这个损失函数是YOLOv8中引入的自定义损失函数。YOLOv8使用了特征点来预测物体的方向和角度信息,dfl_loss用于计算预测特征点与真实特征点之间的差异。通过最小化dfl_loss,模型可以学习到更准确的物体方向和角度信息。
4. val_batch
验证中的标签框和预测框

5. 训练过程中实时显示的数据
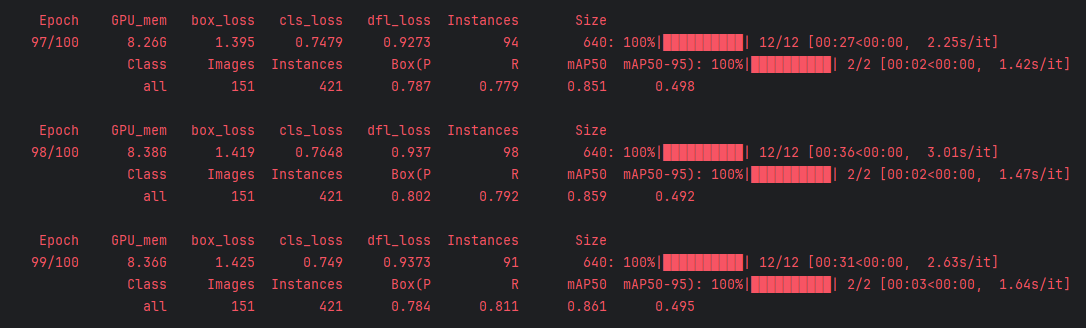
Epoch:迭代次数
Gpu_mem:显卡显存占用,不超过最大显卡显存就好,如果超过可以调低batch.
box_loss:边界框损失
cls_loss:分类损失
dfl_loss:特征点损失
Instances:实例个数,矩形框个数,这个数是在不断变化的
Size:640,训练时会将输入图像resize到640*640
Class:训练类
Images:后面少二个0,训练图像数量
Instances:全部矩形框个数
Box(P:精准率
R:召回率
由图可知,精准率在提高,召回率在下降,结合前面公式,说明漏检数量在提升。map50:置信度阈值在0.5时,检测的map
map50-95:50.55.60.65.70.75.80.85.90.95,取得10个mAP值,然后对这十个值取平均。由图可知,map50,map是0.6,map50-95:map是0.35,说明在高阈值时,检测效果并不好,由0.7,0.75对称可得:大部分检出框置信度在0.5~0.7之间。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 64
64 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)