深度学习项目基础知识补充(学习笔记)
RNN(LSTM)**RNN(Recurrent Neural Network,循环神经网络)**是一种用于处理序列数据的神经网络。它能够处理任意长度的序列,并且能够捕捉序列中的时间依赖关系。**LSTM(Long Short-Term Memory)**是RNN的一种变体,专门设计来解决RNN在处理长序列时遇到的梯度消失和梯度爆炸问题。LSTM通过引入门控机制(包括输入门、遗忘门和输出门)来控制
深度学习项目基础知识补充
python语法
if name == ‘main’:
是 Python 中常用的一种代码结构,用于判断当前脚本是否是直接运行的。
name 是 Python 的一个内置变量。它的值取决于脚本的运行方式。
当脚本被直接运行时,name 的值是 ‘main’。
当脚本被作为模块导入到其他脚本时,name 的值就是脚本的文件名(不带路径和 .py 后缀)。
import torch:导入PyTorch库,PyTorch是一个流行的深度学习框架,提供了用于构建和训练神经网络的工具。
import torch.nn as nn:导入PyTorch的神经网络模块,并将其简化命名为nn。这个模块包括了构建神经网络的基本组件,如层(layers)、损失函数(loss functions)等。
import torch.nn.functional as F:导入PyTorch的功能性神经网络模块,并将其命名为F。这个模块包含一些常用的激活函数、池化函数和其他的操作,在构建模型时经常用到。
import numpy as np:导入NumPy库,NumPy是一个科学计算库,提供了多维数组对象和各种数学函数。通常用于处理数据和做数值计算。
x, _ = x 解包语法
语法解释:
x, _ = x 是 Python 中的一种多重赋值语句,也称为解包(unpacking)。
左边的 x, _ 是一个元组,表示将右边的 x 解包成两个变量。
_ 是一个特殊的变量名,通常用于表示不关心或不需要使用的值。
具体解释:
假设 x 是一个元组,例如 x = (input_data, other_data)。
执行 x, _ = x 后,x 将被解包成两个部分:
第一个部分 input_data 被赋值给左边的 x。
第二个部分 other_data 被赋值给左边的 _,但由于 _ 是一个占位符,表示我们不关心这个值。
应用场景:
在深度学习中,输入数据可能是一个包含多个部分的元组,例如 (input_data, labels)。
通过 x, _ = x,我们可以方便地提取出实际的输入数据 input_data,而忽略其他部分(如标签 labels)。
示例
假设 x 是一个包含输入数据和标签的元组:x = (torch.tensor([[1, 2], [3, 4]]), torch.tensor([0, 1]))
执行 x, _ = x 后:
x 将变为 torch.tensor([[1, 2], [3, 4]])。
_ 将变为 torch.tensor([0, 1]),但通常我们会忽略 _ 的值。
python类和构造函数
类 = 月饼模具
想象你有一个月饼模具,这个模具决定了月饼的形状和花纹。这个模具就是类(Class)。每次用这个模具压出来的月饼,都叫对象(Object)。
构造函数 = 往模具里塞馅料的过程
当你用模具压月饼时,通常还要往模具里塞入馅料(比如豆沙、蛋黄)。**构造函数(__init__方法)**就是这个塞馅料的过程:
决定月饼的初始属性(比如馅料类型、甜度)
在月饼被压出来(对象被创建)时自动执行
# 1. 定义一个月饼模具(类)
class MoonCake:
# 2. 构造函数:塞馅料的步骤
def __init__(self, filling, sweetness):
self.filling = filling # 馅料类型
self.sweetness = sweetness # 甜度等级
# 3. 用模具压一个月饼(创建对象)
my_cake = MoonCake(filling="豆沙", sweetness=5)
print(my_cake.filling) # 输出:豆沙
print(my_cake.sweetness) # 输出:5
关键语法解释
定义类:class 类名:
类名通常用大写字母开头(比如MoonCake)
构造函数:def init(self, 参数1, 参数2…):
固定名字__init__,每次创建对象时自动调用
self代表当前对象自己(类似说"这个月饼")
通过self.属性名 = 值给对象添加属性
创建对象:对象名 = 类名(参数)
参数会传递给__init__方法
不需要手动写self参数,Python会自动处理
为什么需要构造函数?
初始化属性:就像不给月饼塞馅料的话,月饼就是空心的
灵活定制:通过传递不同参数,创建不同属性的对象(比如豆沙馅、五仁馅)
python类中的构造函数和方法的区别
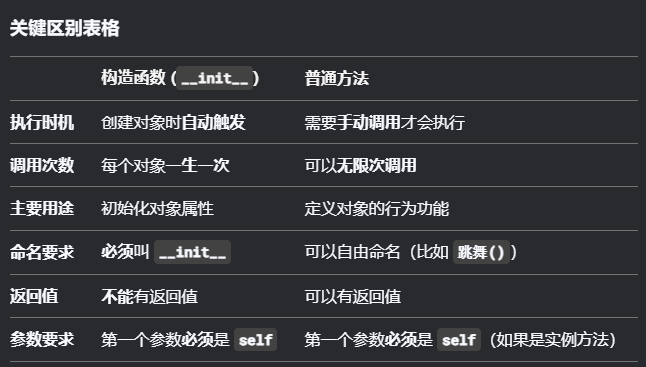
class 学生:
def __init__(self, 姓名): # 构造函数
self.姓名 = 姓名
print(f"{姓名}同学入学!")
def 交作业(self): # 普通方法
print(f"{self.姓名}提交了作业")
# 创建对象时自动触发构造函数
小明 = 学生("小明") # 输出:小明同学入学!
# 普通方法需要手动调用
小明.交作业() # 输出:小明提交了作业
**一句话总结:**构造函数是「出厂设置说明书」,普通方法是「功能使用说明书」 📖
—— 前者决定对象生来什么样,后者决定对象能做什么事。
一个python类中没有构造函数?
一个python类中没有构造函数只有方法,这种语法是合法的。你可以将这个类认为是一个工具箱。
深度学习项目知识
词嵌入(Word Embedding)和随机初始化(Random Initialization) 是两种为模型表示文本数据的不同方式。以下是对它们的简要解释:词嵌入:
词嵌入是将文本数据(如单词或字符)转化为数值向量的一种技术,帮助模型理解词汇的语义关系。
预训练的词嵌入文件(如 embedding_SougouNews.npz)通常基于大规模语料库训练,已包含丰富的词语间关系。
使用词嵌入可以加快模型的收敛速度,并提高分类任务中的表现,尤其在数据量较小的情况下。随机初始化:
随机初始化是将词汇的向量值随机设置,模型通过训练数据逐步学习词汇关系。
这种方法不借助预训练语义关系,因此训练开始时模型对词语的理解是“空白”。
随机初始化适用于没有现成预训练词嵌入的领域,但通常需要更多数据和训练时间才能达到较好的表现。
随机数种子:指生成随机数的初始值,保证每次运行程序产生一致的随机数序列。设置随机数种子可以保证每次运行结果一样,从而保证结果可复现、调试便利、得出性能比较等
批量迭代器:用于逐批加载数据的工具,支持模型一次处理一个批次的数据(助于内存、训练、更新的效率)
train模式和eval模式
在traim模式下启用模型中的训练专用设置,如会打开 Dropout 和 Batch Normalization 层的训练模式
在eval模式下,即相对应的测试模式。关闭Dropout层将Batch Normalization 层的行为设置为推理模式
Batch 的具体含义
一个 batch 是在一次前向和反向传播中处理的样本集合,batch size 是每次处理的样本数
批量大小(Batch Size):一个 batch 中包含的样本数量。比如,若 batch size 为 32,则每个 batch 中包含 32 个样本。
数据集拆分:在训练时,数据集会被拆分为多个 batch。例如,若数据集有 1000 个样本,batch size 为 100,则会被拆分为 10 个 batch,每个 batch 包含 100 个样本
前向传播和后向传播
一个 batch 的数据会经历一次前向传播计算出预测和损失,然后通过反向传播计算梯度并更新参数。这个过程被称为“前向和反向传播”,是训练神经网络的基本单元
前向传播
前向传播是将输入数据通过神经网络层层传递,直到得到模型的输出(预测值)的过程。在一次前向传播中,模型从输入层开始,将输入数据通过每一层的神经元进行计算,直到输出层得到结果。过程如下:
输入数据<层层传递<计算预测值<计算损失
后向传播
反向传播是根据前向传播的损失值,计算并传播误差,更新每一层的参数,使模型更接近真实输出的过程。反向传播主要包括以下步骤:
计算梯度<更新参数<逐层传播
init 和 forward 的关系
init 构造函数:定义网络结构和各层组件。
forward 函数:定义输入数据如何在网络中流动,即前向传播的过程。
在使用模型时,通过 model(input) 自动调用 forward 函数,执行模型的前向传播
学习模型介绍
RNN(LSTM):
**RNN(Recurrent Neural Network,循环神经网络)**是一种用于处理序列数据的神经网络。它能够处理任意长度的序列,并且能够捕捉序列中的时间依赖关系。
**LSTM(Long Short-Term Memory)**是RNN的一种变体,专门设计来解决RNN在处理长序列时遇到的梯度消失和梯度爆炸问题。LSTM通过引入门控机制(包括输入门、遗忘门和输出门)来控制信息的流动,从而更好地捕捉长距离依赖。
Sequence2Sequence模型(Seq2Seq):
Seq2Seq模型是一种用于处理序列到序列(Seq2Seq)问题的模型,广泛应用于机器翻译、文本摘要等任务。它通常由两部分组成:Encoder(编码器)和Decoder(解码器)。
Encoder负责将输入序列(如一段文本)编码成一个固定长度的向量。
Decoder负责将这个向量解码成输出序列(如另一种语言的文本)。
注意力机制(Attention Mechanism):
注意力机制是一种让模型在处理序列时能够聚焦于特定部分的技术。它最初在神经机器翻译中被提出,后来被广泛应用于各种序列处理任务。
在Seq2Seq模型中,注意力机制允许Decoder在生成每个输出词时,动态地聚焦于输入序列的不同部分,从而提高翻译的准确性和流畅性。
通过计算输入序列中每个词与当前输出词的相关性权重,注意力机制使得模型能够更好地捕捉全局上下文信息。
总结来说,RNN(特别是LSTM)用于处理序列数据,Seq2Seq模型用于将序列转换为另一序列,而注意力机制则增强了Seq2Seq模型在处理序列时的灵活性和准确性。这些技术共同推动了自然语言处理领域的发展。
对抗样本
在图片中添加了一些什么微笑的噪声,引起深度学习完全不一样的判断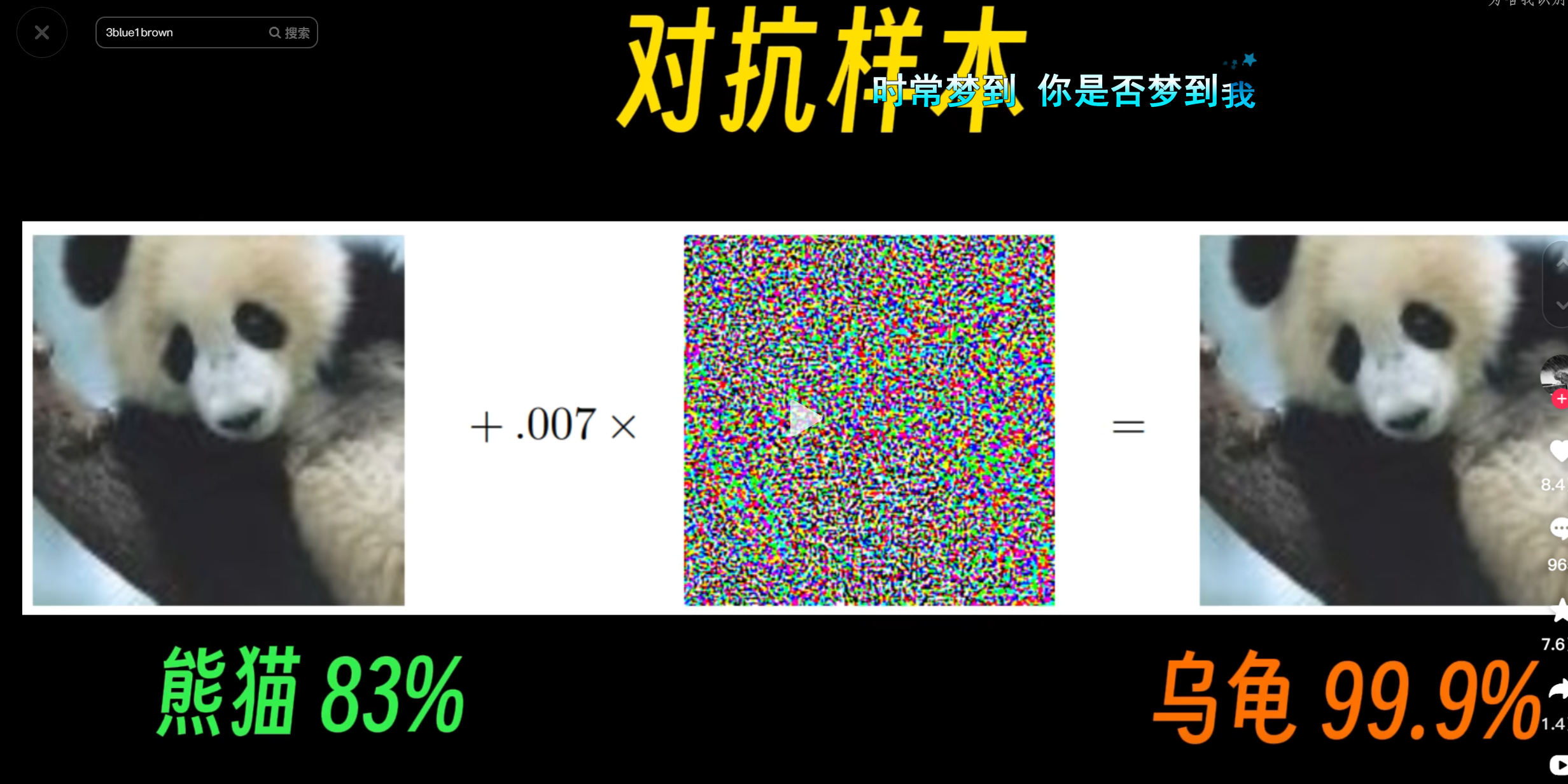
transformer
class Encoder(nn.Module):编码器的类,继承自 nn.Module,这是PyTorch中所有神经网络模型的基类
学习项目思路
项目概述:从 README.md 入手,理解项目的整体目标。
入口文件:学习 run.py,掌握项目的启动流程。
核心逻辑:深入 train_eval.py,理解训练、验证、测试的实现。
模型实现:从 models/ 中学习各个模型的定义,从简单到复杂依次进行。
辅助工具:理解 utils.py,掌握辅助函数的使用。
实验对比:运行不同模型,掌握项目的评估流程。
尝试修改:在熟悉项目后可以动手扩展。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)