Daily AI 20250317 (强化学习基础)
智能体与环境进行交互将智能体与环境的交互看作离散的时间序列.智能体从感知到的初始环境s0s_0s0开始,然后决定做一个相应的动作a0a_0a0,环境相应地发生改变到新的状态s1s_1s1,并反馈给智能体一个即时奖励r1r_1r1,然后智能体又根据状态s1s_1s1做一个动作a1a_1a1,环境相应改变为s2s_2s2,并反馈奖励r2r_2r2.这样的交互可以一直进行下去,其中rtr
参考资料:神经网络与深度学习
深度强化学习基础概念
强化学习也是机器学习中的一个重要分支.强化学习和监督学习的不同在于,强化学习问题不需要给出“正确”策略作为监督信息,只需要给出策略的(延迟)回报,并通过调整策略来取得最大化的期望回报。其与控制理论息息相关。
1.强化学习定义
智能体与环境进行交互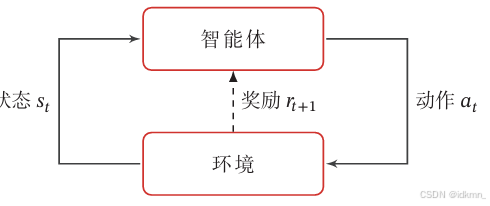
将智能体与环境的交互看作离散的时间序列.智能体从感知到的初始环境 s 0 s_0 s0 开始,然后决定做一个相应的动作 a 0 a_0 a0 ,环境相应地发生改变到新的状态 s 1 s_1 s1 ,并反馈给智能体一个即时奖励 r 1 r_1 r1 ,然后智能体又根据状态 s 1 s_1 s1 做一个动作 a 1 a_1 a1 ,环境相应改变为 s 2 s_2 s2 ,并反馈奖励 r 2 r_2 r2 .这样的交互可以一直进行下去,其中 r t = r ( s t − 1 , a t − 1 , s t ) r_t=r\left(s_{t-1}, a_{t-1}, s_t\right) rt=r(st−1,at−1,st) 是第 t t t 时刻的即时奖励。
策略:智能体的策略(Policy)就是智能体如何根据环境状态 s s s 来决定下一步的动作 a a a ,通常可以分为确定性策略和随机性策略两种。策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 是智能体根据环境状态 s s s 来决定下一步动作 a a a 的函数.
其中随机性策略表明在给定环境状态时,智能体选择某个动作 a a a的概率分布:
π ( a ∣ s ) ≜ p ( a ∣ s ) ∑ a ∈ A π ( a ∣ s ) = 1 \begin{aligned} \pi(a \mid s) & \triangleq p(a \mid s) \\ \sum_{a \in \mathcal{A}} \pi(a \mid s) & =1 \end{aligned} π(a∣s)a∈A∑π(a∣s)≜p(a∣s)=1
2.马尔可夫决策过程
智能体与环境的交互过程可以看作一个马尔可夫决策过程。
对于一个马尔可夫过程,下一个时刻状态只取决于当前状态,即
p ( s t + 1 ∣ s t , ⋯ , s 0 ) = p ( s t + 1 ∣ s t ) \begin{aligned} p\left(s_{t+1} \mid s_t, \cdots, s_0\right)=p\left(s_{t+1} \mid s_t\right) \end{aligned} p(st+1∣st,⋯,s0)=p(st+1∣st)
其中 p ( s t + 1 ∣ s t ) p\left(s_{t+1} \mid s_t\right) p(st+1∣st) 称为状态转移概率,满足 ∑ s t + 1 ∈ S p ( s t + 1 ∣ s t ) = 1 \sum_{s_{t+1} \in \mathcal{S}} p\left(s_{t+1} \mid s_t\right)=1 ∑st+1∈Sp(st+1∣st)=1 。
马尔可夫决策过程在马尔可夫过程中加入一个额外的变量:动作 a a a ,使得下一个时刻的状态 s t + 1 s_{t+1} st+1 不但和当前时刻的状态 s t s_t st 相关,而且和动作 a t a_t at 相关,即
p ( s t + 1 ∣ s t , a t , ⋯ , s 0 , a 0 ) = p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_t, a_t, \cdots, s_0, a_0\right)=p\left(s_{t+1} \mid s_t, a_t\right) p(st+1∣st,at,⋯,s0,a0)=p(st+1∣st,at)
其中 p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_t, a_t\right) p(st+1∣st,at) 为状态转移概率。
当给定策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s)时,马尔可夫决策过程的一个轨迹 τ = s 0 , a 0 , s 1 , r 1 , a 1 , ⋯ , s T − 1 , a T − 1 , s T , r T \tau=s_0, a_0, s_1, r_1, a_1, \cdots, s_{T-1}, a_{T-1}, s_T, r_T τ=s0,a0,s1,r1,a1,⋯,sT−1,aT−1,sT,rT对应的概率为
p ( τ ) = p ( s 0 , a 0 , s 1 , a 1 , ⋯ ) = p ( s 0 ) ∏ t = 0 T − 1 π ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) \begin{aligned} p(\tau) & =p\left(s_0, a_0, s_1, a_1, \cdots\right) \\ & =p\left(s_0\right) \prod_{t=0}^{T-1} \pi\left(a_t \mid s_t\right) p\left(s_{t+1} \mid s_t, a_t\right) \end{aligned} p(τ)=p(s0,a0,s1,a1,⋯)=p(s0)t=0∏T−1π(at∣st)p(st+1∣st,at)
Note: 根据条件概率的链式法则,有
p ( X 1 , X 2 , … , X n ) = p ( X 1 ) p ( X 2 ∣ X 1 ) p ( X 3 ∣ X 1 , X 2 ) ⋯ p ( X n ∣ X 1 , X 2 , … , X n − 1 ) p\left(X_1, X_2, \ldots, X_n\right)=p\left(X_1\right) p\left(X_2 \mid X_1\right) p\left(X_3 \mid X_1, X_2\right) \cdots p\left(X_n \mid X_1, X_2, \ldots, X_{n-1}\right) p(X1,X2,…,Xn)=p(X1)p(X2∣X1)p(X3∣X1,X2)⋯p(Xn∣X1,X2,…,Xn−1)
将 p ( τ ) p(\tau) p(τ)按照链式法则分解,能够得到
p ( s 0 , a 0 , s 1 , a 1 , … , s T ) = p ( s 0 ) p ( a 0 ∣ s 0 ) p ( s 1 ∣ s 0 , a 0 ) p ( a 1 ∣ s 0 , a 0 , s 1 ) p ( s 2 ∣ s 0 , a 0 , s 1 , a 1 ) … p ( s T ∣ s 0 , a 0 , … , s T − 1 , a T − 1 ) p\left(s_0, a_0, s_1, a_1, \ldots, s_T\right)=p\left(s_0\right) p\left(a_0 \mid s_0\right) p\left(s_1 \mid s_0, a_0\right) p\left(a_1 \mid s_0, a_0, s_1\right) p\left(s_2 \mid s_0, a_0, s_1, a_1\right) \ldots p\left(s_T \mid s_0, a_0, \ldots, s_{T-1}, a_{T-1}\right) p(s0,a0,s1,a1,…,sT)=p(s0)p(a0∣s0)p(s1∣s0,a0)p(a1∣s0,a0,s1)p(s2∣s0,a0,s1,a1)…p(sT∣s0,a0,…,sT−1,aT−1)
再根据:
环境的状态转移概率 满足马尔可夫性质:
p ( s t + 1 ∣ s 0 , a 0 , s 1 , a 1 , … , s t , a t ) = p ( s t + 1 ∣ s t , a t ) p\left(s_{t+1} \mid s_0, a_0, s_1, a_1, \ldots, s_t, a_t\right)=p\left(s_{t+1} \mid s_t, a_t\right) p(st+1∣s0,a0,s1,a1,…,st,at)=p(st+1∣st,at)
策略的决策概率 只依赖当前状态:
p ( a t ∣ s 0 , a 0 , s 1 , a 1 , … , s t ) = p ( a t ∣ s t ) = π ( a t ∣ s t ) p\left(a_t \mid s_0, a_0, s_1, a_1, \ldots, s_t\right)=p\left(a_t \mid s_t\right)=\pi\left(a_t \mid s_t\right) p(at∣s0,a0,s1,a1,…,st)=p(at∣st)=π(at∣st)
进而简化链式法则分解的表达式:
p ( s 0 , a 0 , s 1 , a 1 , … , s T ) = p ( s 0 ) ∏ t = 0 T − 1 p ( a t ∣ s t ) p ( s t + 1 ∣ s t , a t ) p\left(s_0, a_0, s_1, a_1, \ldots, s_T\right)=p\left(s_0\right) \prod_{t=0}^{T-1} p\left(a_t \mid s_t\right) p\left(s_{t+1} \mid s_t, a_t\right) p(s0,a0,s1,a1,…,sT)=p(s0)t=0∏T−1p(at∣st)p(st+1∣st,at)
3.强化学习的目标函数
3.1.总回报
给定策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) ,智能体和环境一次交互过程的轨迹 τ \tau τ 所收到的累积奖励为总回报。(基于环境 s t s_t st,智能体做出动作 a t a_t at,环境相应变为 s t + 1 s_{t+1} st+1,并给出相应的 reward r t + 1 r_{t+1} rt+1)
G ( τ ) = ∑ t = 0 T − 1 r t + 1 = ∑ t = 0 T − 1 r ( s t , a t , s t + 1 ) G(\tau) =\sum_{t=0}^{T-1} r_{t+1} =\sum_{t=0}^{T-1} r\left(s_t, a_t, s_{t+1}\right) G(τ)=t=0∑T−1rt+1=t=0∑T−1r(st,at,st+1)
假设环境中有一个或多个特殊的终止状态,当到达终止状态时,一个智能体和环境的交互过程就结束了。这一轮交互的过程称为一个回合 或试验。一般的强化学习任务(比如下棋,游戏)都属于这种回合式任务。如果环境中没有终止状态(比如终身学习的机器人),即 T = ∞ T=\infty T=∞ ,称为持续式任务,其总回报也可能是无穷大。为了解决这个问题,我们可以引入一个折扣率来降低远期回报的权重。折扣回报定义为
G ( τ ) = ∑ t = 0 T − 1 γ t r t + 1 G(\tau)=\sum_{t=0}^{T-1} \gamma^t r_{t+1} G(τ)=t=0∑T−1γtrt+1
3.2.目标函数
J ( θ ) = E τ ∼ p θ ( τ ) [ G ( τ ) ] = E τ ∼ p θ ( τ ) [ ∑ t = 0 T − 1 γ t r t + 1 ] \mathcal{J}(\theta)=\mathbb{E}_{\tau \sim p_\theta(\tau)}[G(\tau)]=\mathbb{E}_{\tau \sim p_\theta(\tau)}\left[\sum_{t=0}^{T-1} \gamma^t r_{t+1}\right] J(θ)=Eτ∼pθ(τ)[G(τ)]=Eτ∼pθ(τ)[t=0∑T−1γtrt+1]
强化学习目标是学习一个策略 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s)以最大化期望回报,其中 θ \theta θ为策略函数的参数。 p θ ( τ ) p_{\theta}(\tau) pθ(τ)为基于策略 π θ ( a ∣ s ) \pi_\theta(a \mid s) πθ(a∣s)得到轨迹 τ \tau τ的概率。
4.强化学习中的值函数
为了评估策略 π \pi π 的期望回报,进一步定义两个值函数:状态值函数和状态-动作值函数。
4.1.状态值函数
如前所述,强化学习的目标是最大化策略 π \pi π 的 期望回报,策略 π \pi π 的期望回报可以分解为
E τ ∼ p ( τ ) [ G ( τ ) ] = E s ∼ p ( s 0 ) [ E τ ∼ p ( τ ) [ ∑ t = 0 T − 1 γ t r t + 1 ∣ τ s 0 = s ] ] = E s ∼ p ( s 0 ) [ V π ( s ) ] \begin{aligned} \mathbb{E}_{\tau \sim p(\tau)}[G(\tau)] & =\mathbb{E}_{s \sim p\left(s_0\right)}\left[\mathbb{E}_{\tau \sim p(\tau)}\left[\sum_{t=0}^{T-1} \gamma^t r_{t+1} \mid \tau_{s_0}=s\right]\right] \\ & =\mathbb{E}_{s \sim p\left(s_0\right)}\left[V^\pi(s)\right] \end{aligned} Eτ∼p(τ)[G(τ)]=Es∼p(s0)[Eτ∼p(τ)[t=0∑T−1γtrt+1∣τs0=s]]=Es∼p(s0)[Vπ(s)]
其中 V π ( s ) V^\pi(s) Vπ(s) 称为状态值函数(State Value Function),表示从状态 s s s 开始,执行策略 π \pi π 得到的期望总回报
V π ( s ) = E τ ∼ p ( τ ) [ ∑ t = 0 T − 1 γ t r t + 1 ∣ τ s 0 = s ] V^\pi(s)=\mathbb{E}_{\tau \sim p(\tau)}\left[\sum_{t=0}^{T-1} \gamma^t r_{t+1} \mid \tau_{s_0}=s\right] Vπ(s)=Eτ∼p(τ)[t=0∑T−1γtrt+1∣τs0=s]
其中 τ s 0 \tau_{s_0} τs0 表示轨迹 τ \tau τ 的起始状态。
Note:利用轨迹的初始状态 s 0 s_0 s0 进行分解: E τ ∼ p ( τ ) [ G ( τ ) ] = ∑ s 0 p ( s 0 ) E τ ∼ p ( τ ) [ G ( τ ) ∣ s 0 ] \mathbb{E}_{\tau \sim p(\tau)}[G(\tau)]=\sum_{s_0} p\left(s_0\right) \mathbb{E}_{\tau \sim p(\tau)}\left[G(\tau) \mid s_0\right] Eτ∼p(τ)[G(τ)]=∑s0p(s0)Eτ∼p(τ)[G(τ)∣s0],这里 p ( s 0 ) p\left(s_0\right) p(s0) 是初始状态的分布。状态值函数 V π ( s ) V^\pi(s) Vπ(s) 即衡量了智能体从某个状态 s s s 出发,遵循策略 π \pi π 所能期望获得的长期收益。
贝尔曼方程(值函数的递归定义):令用 τ 0 : T \tau_{0: T} τ0:T 来表示轨迹 s 0 , a 0 , s 1 , ⋯ , s T s_0, a_0, s_1, \cdots, s_T s0,a0,s1,⋯,sT ,用 τ 1 : T \tau_{1: T} τ1:T 来表示轨迹 s 1 , a 1 , ⋯ , s T s_1, a_1, \cdots, s_T s1,a1,⋯,sT ,因此有 τ 0 : T = s 0 , a 0 , τ 1 : T \tau_{0: T}=s_0, a_0, \tau_{1: T} τ0:T=s0,a0,τ1:T 。基于马尔科夫性质,对状态值函数 V π ( s ) V^\pi(s) Vπ(s)展开得到:
V π ( s ) = ( a ) E τ 0 : T ∼ p ( τ ) [ r 1 + γ ∑ t = 1 T − 1 γ t − 1 r t + 1 ∣ τ s 0 = s ] = ( b ) E a ∼ π ( a ∣ s ) E s ′ ∼ p ( s ′ ∣ s , a ) E τ 1 : T ∼ p ( τ ) [ r ( s , a , s ′ ) + γ ∑ t = 1 T − 1 γ t − 1 r t + 1 ∣ τ s 1 = s ′ ] = ( c ) E a ∼ π ( a ∣ s ) E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ E τ 1 : T ∼ p ( τ ) [ ∑ t = 1 T − 1 γ t − 1 r t + 1 ∣ τ s 1 = s ′ ] ] = ( d ) E a ∼ π ( a ∣ s ) E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ V π ( s ′ ) ] \begin{aligned} & V^\pi(s)\overset{(a)}{=}\mathbb{E}_{\tau_{0: T} \sim p(\tau)}\left[r_1+\gamma \sum_{t=1}^{T-1} \gamma^{t-1} r_{t+1} \mid \tau_{s_0}=s\right] \\ & \overset{(b)}{=} \mathbb{E}_{a \sim \pi(a \mid s)} \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)} \mathbb{E}_{\tau_{1: T} \sim p(\tau)}\left[r\left(s, a, s^{\prime}\right)+\gamma \sum_{t=1}^{T-1} \gamma^{t-1} r_{t+1} \mid \tau_{s_1}=s^{\prime}\right] \\ & \overset{(c)}{=} \mathbb{E}_{a \sim \pi(a \mid s)} \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma \mathbb{E}_{\tau_{1: T} \sim p(\tau)}\left[\sum_{t=1}^{T-1} \gamma^{t-1} r_{t+1} \mid \tau_{s_1}=s^{\prime}\right]\right] \\ & \overset{(d)}{=} \mathbb{E}_{a \sim \pi(a \mid s)} \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma V^\pi\left(s^{\prime}\right)\right] \end{aligned} Vπ(s)=(a)Eτ0:T∼p(τ)[r1+γt=1∑T−1γt−1rt+1∣τs0=s]=(b)Ea∼π(a∣s)Es′∼p(s′∣s,a)Eτ1:T∼p(τ)[r(s,a,s′)+γt=1∑T−1γt−1rt+1∣τs1=s′]=(c)Ea∼π(a∣s)Es′∼p(s′∣s,a)[r(s,a,s′)+γEτ1:T∼p(τ)[t=1∑T−1γt−1rt+1∣τs1=s′]]=(d)Ea∼π(a∣s)Es′∼p(s′∣s,a)[r(s,a,s′)+γVπ(s′)]
其中,
(a)等价于将回报拆成第一步奖励 r 1 r_1 r1 和后续奖励;
(b)使用条件期望分解未来轨迹,根据马尔科夫链性质,未来状态仅依赖于当前状态和当前动作,而不依赖过去的历史轨迹。具体而言,
- 首先在状态 s s s 选择动作 a a a ,其概率由策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 决定。
- 然后环境转移到新的状态 s ′ s^{\prime} s′ ,其概率由环境动力学(状态转移概率) p ( s ′ ∣ s , a ) p\left(s^{\prime} \mid s, a\right) p(s′∣s,a) 确定。
- 最后计算从状态 s ′ s^{\prime} s′ 开始的未来期望回报。
(c)根据 E [ X + Y ] = E [ X ] + E [ Y ] \mathbb{E}[X+Y]=\mathbb{E}[X]+\mathbb{E}[Y] E[X+Y]=E[X]+E[Y],表明先计算即时奖励 r ( s , a , s ′ ) r\left(s, a, s^{\prime}\right) r(s,a,s′),未来回报的期望则单独计算(再乘以一个 γ \gamma γ);
(d)观察可知 E τ 1 : T ∼ p ( τ ) [ ∑ t = 1 T − 1 γ t − 1 r t + 1 ∣ τ s 1 = s ′ ] \mathbb{E}_{\tau_{1: T} \sim p(\tau)}\left[\sum_{t=1}^{T-1} \gamma^{t-1} r_{t+1} \mid \tau_{s_1}=s^{\prime}\right] Eτ1:T∼p(τ)[∑t=1T−1γt−1rt+1∣τs1=s′]即为 V π ( s ′ ) V^\pi\left(s^{\prime}\right) Vπ(s′)
Note:贝尔曼方程表明当前状态的值函数可以通过下一状态的值函数递归地计算。如果我们希望找到最优策略 π ∗ \pi^* π∗ ,则其最优值函数 V ∗ ( s ) V^*(s) V∗(s) 满足 贝尔曼最优方程:
V ∗ ( s ) = max a E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ V ∗ ( s ′ ) ] V^*(s)=\max _a \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma V^*\left(s^{\prime}\right)\right] V∗(s)=amaxEs′∼p(s′∣s,a)[r(s,a,s′)+γV∗(s′)]
4.2.状态-动作 值函数
观察上述关于 V π ( s ) V^{\pi}(s) Vπ(s)的贝尔曼方程:
V π ( s ) = E a ∼ π ( a ∣ s ) E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ V π ( s ′ ) ] V^{\pi}(s)=\mathbb{E}_{a \sim \pi(a \mid s)} {\color{red} \mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma V^\pi\left(s^{\prime}\right)\right] } Vπ(s)=Ea∼π(a∣s)Es′∼p(s′∣s,a)[r(s,a,s′)+γVπ(s′)]
其中红色部分表明指初始状态为 s s s 并进行动作 a a a ,然后执行策略 π \pi π 得到的期望总回报,称为状态-动作值函数(State-Action Value Function),也被称为Q 函数(Q-Function):
Q π ( s , a ) = E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ V π ( s ′ ) ] Q^\pi(s, a)=\mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma V^\pi\left(s^{\prime}\right)\right] Qπ(s,a)=Es′∼p(s′∣s,a)[r(s,a,s′)+γVπ(s′)]
状态值函数 V π ( s ) V^\pi(s) Vπ(s) 是 Q 函数 Q π ( s , a ) Q^\pi(s, a) Qπ(s,a) 关于动作 a a a 的期望,
V π ( s ) = E a ∼ π ( a ∣ s ) [ Q π ( s , a ) ] V^\pi(s)=\mathbb{E}_{a \sim \pi(a \mid s)}\left[Q^\pi(s, a)\right] Vπ(s)=Ea∼π(a∣s)[Qπ(s,a)]
进一步地,因为 V π ( s ′ ) = E a ′ ∼ π ( a ′ ∣ s ′ ) [ Q π ( s ′ , a ′ ) ] V^\pi(s')=\mathbb{E}_{a' \sim \pi(a' \mid s')}\left[Q^\pi(s', a')\right] Vπ(s′)=Ea′∼π(a′∣s′)[Qπ(s′,a′)],Q 函数可以写为
Q π ( s , a ) = E s ′ ∼ p ( s ′ ∣ s , a ) [ r ( s , a , s ′ ) + γ E a ′ ∼ π ( a ′ ∣ s ′ ) [ Q π ( s ′ , a ′ ) ] ] , Q^\pi(s, a)=\mathbb{E}_{s^{\prime} \sim p\left(s^{\prime} \mid s, a\right)}\left[r\left(s, a, s^{\prime}\right)+\gamma \mathbb{E}_{a^{\prime} \sim \pi\left(a^{\prime} \mid s^{\prime}\right)}\left[Q^\pi\left(s^{\prime}, a^{\prime}\right)\right]\right], Qπ(s,a)=Es′∼p(s′∣s,a)[r(s,a,s′)+γEa′∼π(a′∣s′)[Qπ(s′,a′)]],
上式为关于 Q 函数的贝尔曼方程。
Note:
因为根据前文,状态值函数的定义为: V π ( s ) = E τ ∼ p ( τ ) [ ∑ t = 0 T − 1 γ t r t + 1 ∣ τ s 0 = s ] V^\pi(s)=\mathbb{E}_{\tau \sim p(\tau)}\left[\sum_{t=0}^{T-1} \gamma^t r_{t+1} \mid \tau_{s_0}=s\right] Vπ(s)=Eτ∼p(τ)[∑t=0T−1γtrt+1∣τs0=s],表示从状态 s s s 出发,遵循策略 π \pi π ,在未来所期望获得的 折扣累计回报。而Q函数则是:从状态 s s s 执行动作 a a a 后,接下来遵循策略 π \pi π 时,未来期望的折扣累计回报,即 Q π ( s , a ) = E τ ∼ p ( τ ) [ ∑ t = 0 ∞ γ t r t + 1 ∣ τ s 0 = s , a 0 = a ] Q^\pi(s, a)=\mathbb{E}_{\tau \sim p(\tau)}\left[\sum_{t=0}^{\infty} \gamma^t r_{t+1} \mid \tau_{s_0}=s, a_0=a\right] Qπ(s,a)=Eτ∼p(τ)[∑t=0∞γtrt+1∣τs0=s,a0=a]。故:
状态值函数 V π ( s ) 是 Q 函数 Q π ( s , a ) 关于动作 a 的期望 V π ( s ) = E a ∼ π ( a ∣ s ) [ Q π ( s , a ) ] V π ( s ) 代表所有可能的动作 a 的 加权期望回报,其中权重由策略 π ( a ∣ s ) 确定 {\color{red}\text { 状态值函数 } V^\pi(s) \text { 是 } Q \text { 函数 } Q^\pi(s, a) \text { 关于动作 } a \text { 的期望 } }\\ {\color{red} V^\pi(s)=\mathbb{E}_{a \sim \pi(a \mid s)}\left[Q^\pi(s, a)\right] } \\ {\color{red}V^\pi(s) \text { 代表所有可能的动作 } a \text { 的 加权期望回报,其中权重由策略 } \pi(a \mid s) \text { 确定 } } 状态值函数 Vπ(s) 是 Q 函数 Qπ(s,a) 关于动作 a 的期望 Vπ(s)=Ea∼π(a∣s)[Qπ(s,a)]Vπ(s) 代表所有可能的动作 a 的 加权期望回报,其中权重由策略 π(a∣s) 确定
值函数可以看作是对策略 π \pi π 的评估,故可以根据值函数来优化策略。假设在状态 s s s ,有一个动作 a ∗ a^* a∗ 使得 Q π ( s , a ∗ ) > V π ( s ) Q^\pi\left(s, a^*\right)>V^\pi(s) Qπ(s,a∗)>Vπ(s) ,说明执行动作 a ∗ a^* a∗ 的回报比当前的策略 π ( a ∣ s ) \pi(a \mid s) π(a∣s) 要高,便可调整参数使得策略中动作 a ∗ a^* a∗ 的概率 p ( a ∗ ∣ s ) p\left(a^* \mid s\right) p(a∗∣s) 增加。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)