DeepSeek-R1技术文章简单解读

DS-R1-Zero完全是RL训练而来的,没有经过SFT(监督式微调)。但是也带来了一些问题,比如容易生成 重复内容、可读性差、语言混杂。GRPO 集中在知识检索和外部数据增强部分。它为 LLM 提供与当前任务最相关的知识片段,确保生成的推理链能依托于真实、准确的信息。GRPO可以减少因低质量检索引入的噪音,降低 LLM 推理时因信息不充分而出现的错误,提高系统整体性能和用户体验。

于是有了DS-R1,在强化学习之前,先加入了冷启动数据进行微调(SFT),让模型从一开始就具备基础的语言和推理能力,之后再用强化学习优化推理能力。这样可以减少 R1-Zero 版本的缺点,提高回答质量和可读性。DS-R1还有多阶段训练这一特征。还是用了一些SFT数据进行后处理(Post-Training)。

接下来是最关键的奖励机制:1. Accuracy rewards;2. Format rewards。准确性奖励用来评估模型的回答是否正确;格式的奖励强制大模型将思考的过程放置于<think>和</think>之间。并没有使用一个结果或者过程的奖励,因为在实际过程中如果这么奖励会出现reward hacking,会陷入一个被动的不断推理的过程。

整个模型有个self-evolution的过程,使得RL可以让一个模型自动提升其推理能力。使用RL初始化base model,我们可以近距离观察模型的进化而不使用SFT阶段。这种方法提供了模型如何随时间演变的清晰视图,特别是在其处理复杂推理任务的能力方面,即在R1的训练过程中,随着时间的推移,R1自我思考的时间越来越长,就有了越来越好的推理能力,这就是自我整体进化的过程。

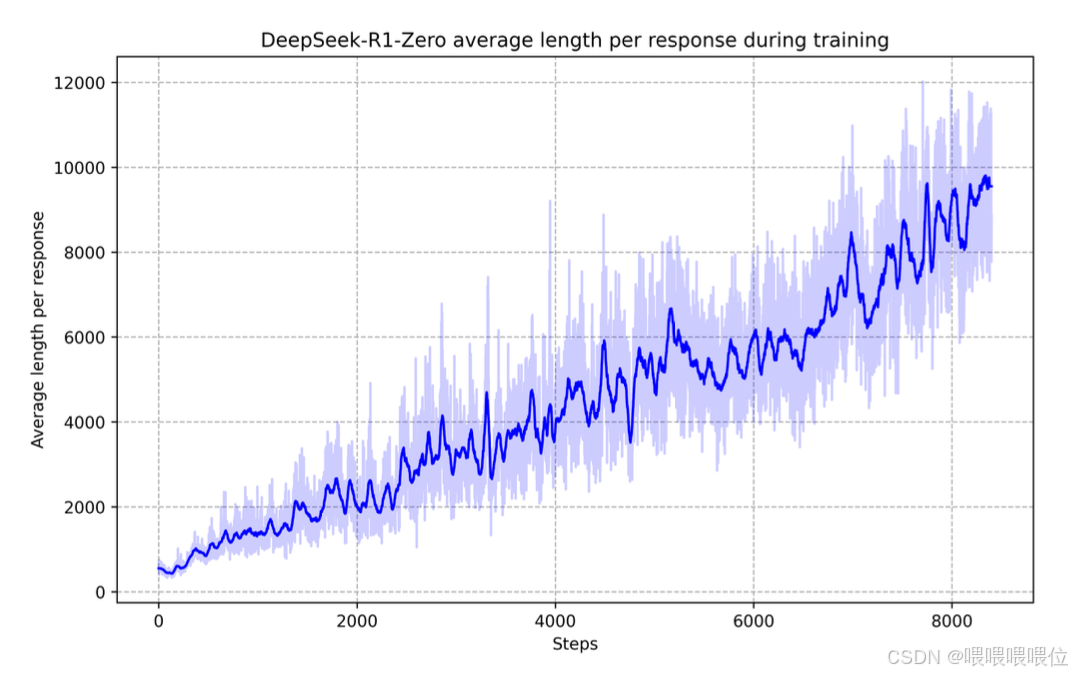
Aha Moment of DeepSeek-R1-Zero:DeepSeek-R1-Zero 的训练过程中会出现一个 “Aha Moment” 的发生(即所谓的顿悟,但是我感觉这就是强化学习的流程之一...)。这一刻,如下表所示,发生在模型的中间版本中。在此阶段,DeepSeek-R1-Zero 通过重新评估问题的初始值来学习为问题分配更多的思考时间方法。这样的表现不只是对模型推理能力成长的证明,也是一个很好的例子,关于强化学习如何能引导出一些预料之外的精密的输出。


Aha Moment象征着模型学会了以拟人化的语气进行重新思考。这对我们来说也是一个顿悟时刻,让我们得以见证强化学习的力量与美。
但是这样的r1-zero也有缺点:不太好的可读性,语言会混杂到一起等。

接下来介绍解决方案:冷启动强化学习(Reinforcement learning with Cold start)和多阶段训练。
在进入之前,讨论两个问题:1. 在冷启动过程中我们能不能加入少量数据来提升模型性能?2. 怎么才能提升zero的可阅读性和友好性?

收集了很多长CoT数据作为RL的微调过程,主要是为了缓解语言混杂问题,在强化学习里就引入了语言一致性的奖励,但是这个奖励会导致模型性能的有所下降,但是由于很符合人类的阅读习惯,所以还是加入了。


拒绝采样和监督微调工作:在RL训练过程中,当快要收敛时,会使用CKPT去收集下一轮的数据。过程就是基于checpoint断点进行拒绝采样,生成了很多推理的轨迹,生成了推理的数据,这里还有非推理的数据为了应对一些简单的问题。

中间是一些实验,这个我们等到复现时候再来细细考量。最后跳到unsuccessful attempts,特别是过程奖励的尝试。

另外就是MTCS蒙特卡洛搜索树相关的算法,但是这个搜索树会让整个模型不断的探索,微调也很困难,也很难去做大规模的扩展。O1也是一样的,采用了MTCS,导致训练过程变得非常的复杂,算法越复杂越不利于scale out或者scaling law,只有scale out或者scaling law才会使我们的模型效果越来越好。(这里和当年的bert、T5为什么没有gpt1、2、3效果好很像,因为前者的encoder、decoder架构整体训练越来越复杂,纯粹采用decoder架构更方便)


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)