深度学习(斋藤)学习笔记(二)
深度学习入门-基于python的理论与实现,学习笔记系列,包括:学习心得与代码实践
本篇笔记将介绍损失函数与梯度,上一篇链接:https://blog.csdn.net/m0_65639009/article/details/145813564?fromshare=blogdetail&sharetype=blogdetail&sharerId=145813564&sharerefer=PC&sharesource=m0_65639009&sharefrom=from_link
批处理(这部分可跳过)
在上一篇文章中只是单个样本依次处理,这里设置一个batch_size,按照batch为单位进行处理。
def main():
# 获取数据
x_test, t_test = get_data()
# 初始化网络
network = init_network()
# 对测试集中的每一张图片进行预测
correct_count = 0
batch_size = 100 # 批数量
for i in range(0,len(x_test),batch_size):
x_batch = x_test[i:i + batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
correct_count += np.sum(p == t_test[i:i + batch_size])
# 输出准确率
accuracy = correct_count / len(x_test) * 100
print(f"Test accuracy: {accuracy:.2f}%")def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, flatten=True, one_hot_label=False)
t_test = np.array(t_test) #增加一行代码:确保t_test是数组,能和p匹配
return x_test, t_test特征量(这部分可跳过)
定义:“特征量”是指可以从输入数据(输入图像)中准确地提取本质数据(重要的数据)的转换器。
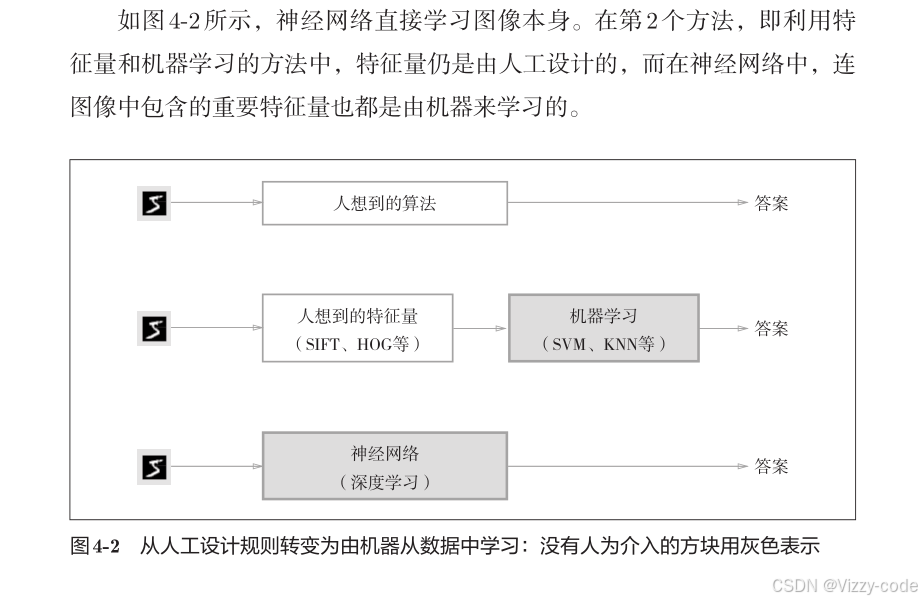 深度 学 习 有 时 也 称 为 端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思。
深度 学 习 有 时 也 称 为 端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思。
通过不断地学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与待处理的问题无关,神经网络可以将数据直接作为原始数据,进行“端对端”的学习。
损失函数
神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数,
但一般用均方误差和交叉熵误差等。
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的神经网络对监督数据在多大程度上不拟合,在多大程度上不一致。
损失函数乘上一个负值,就可以解释为“在多大程度上不坏”,即“性能有多好”。并且,“使性能的恶劣程度达到最小”和“使性能的优良程度达到最大”是等价的。

def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
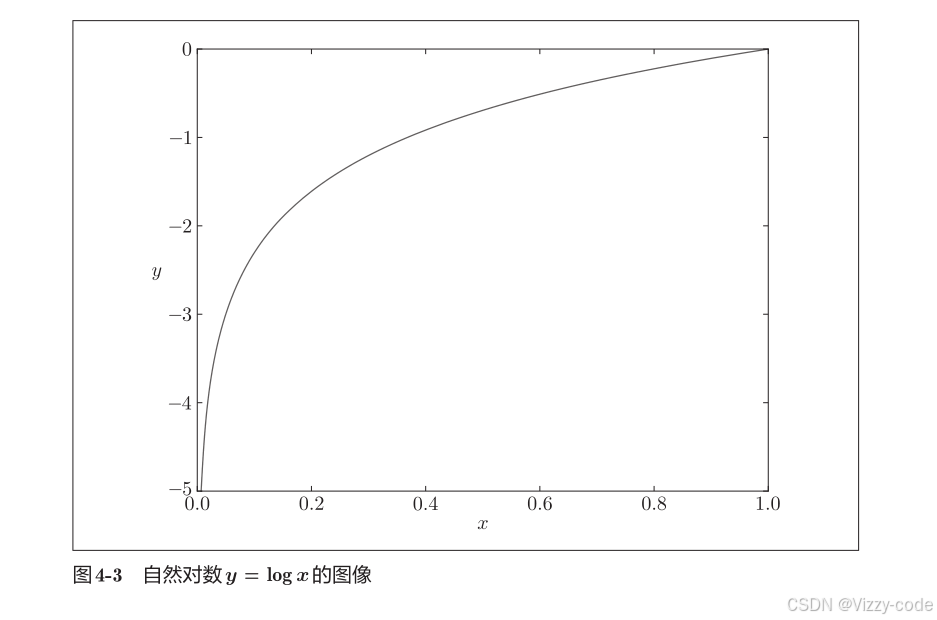
因此损失函数越大,性能越差。
def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta))函数内部在计算 np.log 时,加上了一个微小值 delta。这是因为,当出现 np.log(0) 时,np.log(0) 会变为负无限大的 -inf,这样一来就会导致后续计算无法进行。
可能有人要问:“为什么要导入损失函数呢?”以数字识别任务为例,我们想获得的是能提高识别精度的参数,特意再导入一个损失函数不是有些重复劳动吗?也就是说,既然我们的目标是获得使识
别精度尽可能高的神经网络,那不是应该把识别精度作为指标吗?
对该权重参数的损失函数求导,表示的是“如果稍微改变这个权重参数的值,损失函数的值会如何变化”。如果导数的值为负,通过使该权重参数向正方向改变,可以减小损失函数的值;反过来,如果导数的值为正,则通过使该权重参数向负方向改变,可以减小损失函数的值。不过,当导数的值为 0 时,无论权重参数向哪个方向变化,损失函数的值都不会改变,此时该权重参数的更新会停在此处。
之所以不能用识别精度作为指标,是因为这样一来绝大多数地方的导数都会变为 0,导致参数无法更新。
损失函数关于参数值的变化是连续的,识别精度是离散的。
梯度
导函数
数值微分





梯度与偏导数

而成的向量称为梯度(gradient)。梯度可以像下面这样来实现
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
#f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad函数 numerical_gradient(f, x) 的实现看上去有些复杂,但它执行的处理和求单变量的数值微分基本没有区别。需要补充说明一下的是,np.zeros_like(x) 会生成一个形状和 x相同、所有元素都为 0 的数组。函数 numerical_gradient(f, x) 中,参数 f 为函数,x 为 NumPy 数组,该函数对 NumPy 数组 x 的各个元素求数值微分。

下面,我们用 Python 来实现梯度下降法:
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x参数 f 是要进行最优化的函数,init_x 是初始值,lr 是学习率 learningrate,step_num 是梯度法的重复次数。numerical_gradient(f,x) 会求函数的梯度,用该梯度乘以学习率得到的值进行更新操作,由 step_num 指定重复的次数。
使用这个函数可以求函数的极小值,顺利的话,还可以求函数的最小值。
梯度与导数的关系与区别-CSDN博客
作为导数到梯度的衔接,大家可以看看这篇文章。】
代码实战:
import numpy as np
# 定义目标函数 f(x0, x1) = x0^2 + x1^2
def f(x):
return np.sum(x ** 2) # 对数组 x 中的每个元素平方并求和
# 定义数值梯度函数
def numerical_gradient(f, x):
h = 1e-4 # 步长(很小的值,用于计算数值梯度)
grad = np.zeros_like(x) # 创建一个与 x 形状相同的零数组,用于存储梯度
for idx in range(x.size): # 遍历每一个元素
tmp_val = x[idx] # 保存当前 x 的值
# 计算 f(x+h)
x[idx] = tmp_val + h
fxh1 = f(x)
# 计算 f(x-h)
x[idx] = tmp_val - h
fxh2 = f(x)
# 使用中心差分法计算梯度
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 恢复原始的 x 值
return grad # 返回梯度
# 定义梯度下降函数
def gradient_descent(f, init_x, lr=0.1, step_num=100):
x = init_x # 初始化 x 值
for i in range(step_num): # 迭代更新
grad = numerical_gradient(f, x) # 计算梯度
x -= lr * grad # 使用梯度更新 x 值,lr 是学习率
return x # 返回最优解
# 初始化 x 值并运行梯度下降
init_x = np.array([3.0, 4.0]) # 设置初始点 x0=3.0, x1=4.0
result = gradient_descent(f, init_x, lr=0.1, step_num=100) # 执行梯度下降
print(result) # 返回梯度下降得到的最小值对应的 x0 和 x1
运行结果:
![]()
这些值非常接近于原点 (0,0),说明梯度下降法成功找到了该函数的最小值,符合预期结果。
神经网络的梯度
在知道了目标函数(最小化误差函数),梯度计算方法后,怎么和前篇的神经网络呼应,求神经网络参数的梯度呢,本小节将对此做出介绍。


下面,我们以一个简单的神经网络为例,来实现求梯度的代码。为此,我们要实现一个名为 simpleNet 的类:
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 用高斯分布进行初始化
def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
它有两个方法,一个是用于预测的 predict(x),另一个是用于求损失函数值的 loss(x,t)。这里参数 x 接收输入数据,t接收正确解标签。现在我们来试着用一下这个 simpleNet。
# 创建 simpleNet 对象
net = simpleNet()
# 输出权重参数
print("权重参数 W:")
print(net.W)
# 输入一个样本
x = np.array([0.6, 0.9])
# 设置正确解标签(one-hot 编码)
t = np.array([0, 0, 1])
# 计算并输出损失值
loss = net.loss(x, t)
print("损失值:")
print(loss)返回如下结果:

接下来求梯度。
#计算梯度
dW = numerical_gradient(net.loss(x, t), net.W)
print(dW)
完整代码:
import numpy as np
from learn2 import numerical_gradient
# Softmax 函数
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策,减去最大值来防止溢出
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 交叉熵损失函数
def cross_entropy_error(y, t):
delta = 1e-7 # 防止log(0)出现
return -np.sum(t * np.log(y + delta))
# simpleNet 类
class simpleNet:
def __init__(self):
self.W = np.random.randn(2, 3) # 用高斯分布初始化权重参数
def predict(self, x):
return np.dot(x, self.W) # 使用权重参数进行预测
def loss(self, x, t):
z = self.predict(x) # 计算预测值
y = softmax(z) # 计算softmax输出
loss = cross_entropy_error(y, t) # 计算交叉熵损失
return loss # 返回损失值
# 示例使用代码
# 创建 simpleNet 对象
net = simpleNet()
# 输出权重参数
print("权重参数 W:")
print(net.W)
# 输入一个样本
x = np.array([0.6, 0.9])
# 设置正确解标签(one-hot 编码)
t = np.array([0, 0, 1])
# 计算并输出损失值
loss = net.loss(x, t)
print("损失值:")
print(loss)
#计算梯度
dW = numerical_gradient(net.loss(x, t), net.W)
print(dW)运行结果:

至此关于 神 经 网 络 学 习 的 基 础 知 识,到 这 里 就 全 部 介 绍 完 了。下一章将介绍完整的学习算法实现以及误差反向传播。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)