EfficientAD学习-基于教师学生网络和自编码器的高效异常检测方法
EfficientAD 是一种高效的视觉异常检测模型,其核心由三个模块构成:高效的补丁描述网络(PDN)、轻量级学生-教师模型和自动编码器。最近使用异常检测方法efficientAD在自己的工业数据集上应用,发现效果不太好,因此回到论文中,重新学习下其结构,寻找在自有数据集上效果不好的原因。通过轻量设计、损失函数优化和多模块协同,EfficientAD在异常检测性能和计算效率间实现了最佳平衡,为工
·
大纲
EfficientAD学习-基于教师学生网络和自编码器的高效异常检测方法
最近使用异常检测方法efficientAD在自己的工业数据集上应用,发现效果不太好,因此回到论文中,重新学习下其结构,以期寻找在自有数据集上效果不好的原因。
paper:https://arxiv.org/abs/2303.14535
EfficientAD 是一种高效的视觉异常检测模型,其核心由三个模块构成:高效的补丁描述网络(PDN)、轻量级学生-教师模型和自动编码器。以下从网络结构、训练方式及各模块在训练/推理时的使用方式进行详细介绍:
1. 网络结构
(1) 补丁描述网络(PDN)
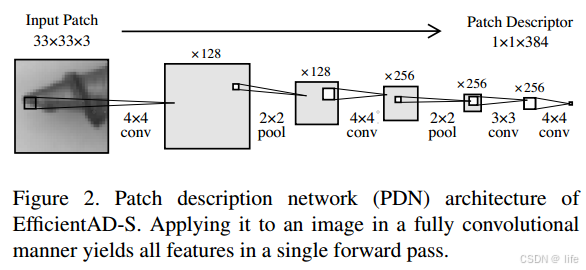
- 结构:PDN 是一个轻量级卷积网络,由四层卷积组成(如图2所示)。输入图像经过两次步长为2的平均池化层进行下采样,最终输出每个33×33图像块对应的384维特征向量。其全卷积设计支持任意尺寸输入,单张256×256图像的特征提取时间<1ms。
- 功能:作为教师网络,提供正常图像的特征表示。通过知识蒸馏从预训练的WideResNet-101中学习,确保特征仅依赖局部图像块,避免长距离依赖问题(如图3所示)。

(2) 学生-教师模型
- 结构:学生网络与PDN结构相同,但输出通道扩展为两倍:一部分预测教师的特征(局部特征),另一部分预测自动编码器的输出(全局特征)。
- 功能:学生通过模仿教师的正常特征和自动编码器的全局重建,学习正常模式,无法预测异常特征。
(3) 自动编码器(Autoencoder)
- 结构:标准卷积自动编码器,编码器通过步长卷积压缩特征,解码器通过双线性上采样重建。瓶颈层为64维,强制学习全局语义约束。
- 功能:捕捉正常图像的逻辑约束(如物体排列),异常图像的重建误差反映逻辑异常。
2. 训练方式
(1) PDN的预训练
- 目标:通过知识蒸馏使PDN模仿WideResNet-101的特征。
- 损失函数:最小化PDN输出与WideResNet特征的均方误差(MSE)。
- 数据:使用ImageNet图像进行训练。
(2) 学生-教师模型训练
- 硬特征损失(loss_hard ):
- 仅对损失最大的前0.1%特征进行反向传播,抑制学生对正常图像的过拟合,提升对异常的敏感度。
- 公式:计算学生与教师输出的平方差,选取分位数阈值以上部分计算平均损失。
- 预训练数据惩罚项(loss_penalty ):
- 在训练中混入ImageNet图像,惩罚学生对其特征的预测,防止泛化到异常分布1。
- 公式:学生输出与零向量的MSE损失。
- 总损失(loss_st ):硬特征损失 + 预训练惩罚项。
(3) 自动编码器训练
- 目标:重建PDN提取的特征。
- 损失函数(loss_ae ):自动编码器输出与教师特征的MSE损失。
(4) 学生与自动编码器的联合训练
- 附加损失(loss_stae ):学生额外预测自动编码器的输出,损失为两者的MSE。
- 总训练目标:学生同时优化对教师和自动编码器的预测,总损失为硬特征损失、预训练惩罚项、自动编码器重建损失和学生附加损失之和。
"""
# 这是从EfficientAD forward中截取的loss相关代码,便于理解每种loss具体是如何计算的
# 可以从源代码中对应以上几种loss,每种loss的英文命名已在上面括号中标识
"""
student_output = self.student(batch)
# 计算教师与学生网络的输出差异 distance_st
distance_st = torch.pow(teacher_output - student_output[:, : self.teacher_out_channels, :, :], 2)
if self.training:
# Student loss
distance_st = reduce_tensor_elems(distance_st)
d_hard = torch.quantile(distance_st, 0.999)
loss_hard = torch.mean(distance_st[distance_st >= d_hard])
student_output_penalty = self.student(batch_imagenet)[:, : self.teacher_out_channels, :, :]
loss_penalty = torch.mean(student_output_penalty**2)
loss_st = loss_hard + loss_penalty
# Autoencoder and Student AE Loss
aug_img = self.choose_random_aug_image(batch)
ae_output_aug = self.ae(aug_img, image_size)
with torch.no_grad():
teacher_output_aug = self.teacher(aug_img)
if self.is_set(self.mean_std):
teacher_output_aug = (teacher_output_aug - self.mean_std["mean"]) / self.mean_std["std"]
student_output_ae_aug = self.student(aug_img)[:, self.teacher_out_channels :, :, :]
distance_ae = torch.pow(teacher_output_aug - ae_output_aug, 2)
distance_stae = torch.pow(ae_output_aug - student_output_ae_aug, 2)
loss_ae = torch.mean(distance_ae)
loss_stae = torch.mean(distance_stae)
3. 各模块在训练/推理时的使用方式
(1) 训练阶段
- PDN:作为固定教师,提供正常图像的特征。
- 学生网络:
- 输入:正常训练图像。
- 输出:同时预测教师特征和自动编码器重建特征。
- 优化目标:最小化与教师和自动编码器的差异,同时抑制对非正常分布(ImageNet)的预测。
- 自动编码器:输入正常图像,输出重建的教师特征,优化重建误差。
(2) 推理阶段
- 异常检测流程:
- 特征提取:教师PDN处理输入图像,生成局部特征。
- 学生预测:学生网络生成局部特征预测和自动编码器特征预测。
- 自动编码器重建:自动编码器生成全局重建特征。
- 异常图生成:
- 局部异常图:学生与教师特征的平方差,平均通道后上采样至输入尺寸。
- 全局异常图:学生预测的自动编码器特征与真实自动编码器输出的平方差。
- 归一化与融合:基于验证集分位数归一化局部和全局异常图,取平均得到最终异常图。
4. 关键设计
- 高效性:PDN和学生网络结构轻量,单次推理仅需2ms(EfficientAD-S)。
- 硬特征损失:通过反向传播关键区域损失,提升异常敏感度。
- 逻辑异常检测:自动编码器捕获全局约束,学生预测其重建误差,结合局部异常检测。
- 归一化校准:分位数归一化确保局部和全局异常图尺度一致,避免噪声干扰。
性能与效果
- 检测指标:在MVTec AD、VisA和LOCO数据集上,EfficientAD的图像级AU-ROC达96.0%,显著优于PatchCore(91.1%)和AST(92.4%)。
- 延迟与吞吐量:EfficientAD-S在NVIDIA RTX A6000上延迟2.2ms,吞吐量614帧/秒,适合实时应用。
通过轻量设计、损失函数优化和多模块协同,EfficientAD在异常检测性能和计算效率间实现了最佳平衡,为工业检测等实时场景提供了高效解决方案。
-
因此即使是用到自己的数据集上,也需要下载一个imagenet的数据集 ↩︎

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)