大模型decode采样策略
是影响文本质量、创造性和稳定性的关键因素。这几种方法结合使用,可以更好地控制大模型的文本生成效果。在大模型(如 GPT)生成文本时,
·
在大模型(如 GPT)生成文本时,采样策略 是影响文本质量、创造性和稳定性的关键因素。这里我们介绍 Top-K、Top-P(Nucleus Sampling)、Temperature 以及核采样 的概念。
1️⃣ Temperature(温度系数)
- 作用:控制生成文本的“随机性”或“创造性”。
- 原理:对模型的概率分布进行缩放,调整较高和较低概率之间的差距。
温度系数公式
模型输出的概率 p_i 通过 Temperature (T) 进行调整: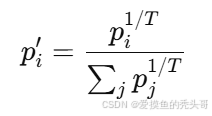
其中:
- T → 低(<1.0):使高概率的词更可能被选中,生成更确定性的文本,减少随机性。
- T → 高(>1.0):使低概率词的选择概率增加,文本更加多样化和随机,但可能降低可读性。
温度调节效果
| Temperature | 结果 |
|---|---|
| T → 0 | 变成贪心搜索,总是选最高概率的词,生成固定文本 |
| T = 0.7 | 默认值,平衡创造性和连贯性 |
| T > 1.0 | 生成文本更发散,但可能变得无意义 |
2️⃣ Top-K 采样
- 作用:限制每次采样时只从前 K 个最高概率的词中选择,忽略低概率词,减少“奇怪”输出的可能性。
- K 值含义:
- K → 1:退化为贪心搜索(Greedy Search),总是选择最高概率的词,文本趋于固定。
- K → ∞(无限):等同于标准采样,所有词都可能被选中。
示例
假设模型预测的词概率:
词1: 0.40, 词2: 0.35, 词3: 0.15, 词4: 0.05, 词5: 0.05
- Top-3 采样(K=3) → 只在【词1, 词2, 词3】里选,忽略 词4 和 词5
- Top-1 采样(K=1) → 永远选 词1,变成贪心搜索
3️⃣ Top-P 采样(Nucleus Sampling,核采样)
- 作用:与 Top-K 不同,Top-P 不是选定固定个数的词,而是选择概率总和达到 P 的词,可以自适应调整选择范围。
- P 值含义:
- P → 1.0:相当于完全随机采样,所有词都可能选中。
- P → 0.9(常见):选择累积概率达到 90% 的词,忽略剩下的 10%。
示例
假设模型预测的词概率:
词1: 0.50, 词2: 0.30, 词3: 0.10, 词4: 0.05, 词5: 0.05
- Top-P(P=0.9):
- 选取【词1, 词2, 词3】,因为它们的累计概率达到 0.9
- 词4 和 词5 被忽略
- 适应性强:当分布平缓时,选择范围更大;当分布陡峭时,选择范围更小。
4️⃣ 核采样(Nucleus Sampling)
- 概念:Top-P 采样就被称为“核采样”(Nucleus Sampling),因为它会选取一个“核”部分(核心词集合)。
- 优势:
- 比 Top-K 更灵活:Top-K 固定选 K 个词,而 Top-P 依据概率动态调整。
- 减少奇怪词的出现:如果高概率词集中,Top-P 会选择更少的词,避免随机选择低概率词。
5️⃣ 采样策略对比
| 采样方法 | 作用 | 适用场景 |
|---|---|---|
| Temperature | 控制随机性(创造性 vs. 连贯性) | 适用于所有情况 |
| Top-K | 限制选择前 K 个最高概率的词 | 适用于需要可控输出的任务 |
| Top-P(核采样) | 选择概率总和达到 P 的词,动态调整 | 适用于自然对话、创造性文本 |
6️⃣ 采样策略的组合
大多数实际应用会结合多种采样方法:
- Temperature + Top-K
- 降低温度(T=0.7)+ 选前 K=50 个词
- 保持多样性,但不会太随机
- Temperature + Top-P(核采样)
- 温度 0.8 + Top-P=0.9
- 让生成更加自然,控制选择范围
- Top-K + Top-P(混合策略)
- K=50, P=0.95
- 既控制选择词数量,也动态调整候选池
7️⃣ 总结
| 方法 | 作用 | 推荐使用场景 |
|---|---|---|
| Temperature | 调整生成随机性 | 影响创造力,T 高更随机,T 低更稳定 |
| Top-K | 选择前 K 个高概率词 | 确保只选择有意义的词,减少低概率错误 |
| Top-P(核采样) | 选择累计概率 P 的词 | 适应性强,适合自然语言对话 |
| 核采样(Nucleus Sampling) | Top-P 的别称 | 适用于聊天机器人、生成式任务 |
一般来说:
- 创造性任务(如小说、对话) → Top-P + Temperature
- 精准任务(如摘要、翻译) → 低温度 + Top-K
- 通用任务 → Top-K + Top-P 结合
这几种方法结合使用,可以更好地控制大模型的文本生成效果。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)